วิธีการ Parallelize ในการประมวลผล Spark Parallel? [ใช้ RDD]
เผยแพร่แล้ว: 2020-09-03การสร้างและการใช้ข้อมูลเพิ่มขึ้น n-folds ในช่วงไม่กี่ปีที่ผ่านมา ด้วยแพลตฟอร์มจำนวนมากที่เข้ามาในชีวิต การจัดการและจัดการข้อมูลอย่างรอบคอบจึงกลายเป็นสิ่งสำคัญ AI (ปัญญาประดิษฐ์) และ ML (การเรียนรู้ของเครื่อง) ทำให้ประสบการณ์ดิจิทัลของเราราบรื่นยิ่งขึ้นด้วยการค้นหาวิธีแก้ไขปัญหาที่ดีขึ้น ดังนั้น บริษัทต่างๆ จึงกำลังมุ่งสู่การปฏิบัติต่อข้อมูลและค้นหาข้อมูลเชิงลึกจากข้อมูลดังกล่าว
ในขณะเดียวกัน ข้อมูลที่สร้างโดยบริษัท ผู้เล่นเครือข่าย และยักษ์ใหญ่ด้านมือถือก็มหาศาลเช่นกัน ด้วยเหตุนี้จึงมีการแนะนำแนวคิดของข้อมูลขนาดใหญ่ เนื่องจากข้อมูลขนาดใหญ่เข้ามาในรูปภาพ เครื่องมือในการจัดการและจัดการข้อมูลขนาดใหญ่ก็เริ่มได้รับความนิยมและมีความสำคัญ
Apache Spark เป็นหนึ่งในเครื่องมือเหล่านั้นที่จัดการและประมวลผลชุดข้อมูลขนาดใหญ่เพื่อรับข้อมูลเชิงลึกจากข้อมูลเหล่านี้ ไม่สามารถประมวลผลหรือจัดการชุดข้อมูลขนาดใหญ่เหล่านี้ได้ในครั้งเดียว เนื่องจากกำลังประมวลผลที่ต้องใช้นั้นรุนแรงเกินไป
นั่นคือจุดที่การประมวลผลแบบขนานเข้ามาในภาพ เราจะเริ่มต้นด้วยการทำความเข้าใจการประมวลผลแบบขนานในระยะสั้น จากนั้นจึงดำเนินการต่อไปเพื่อทำความเข้าใจวิธีการขนานในจุดประกาย
อ่าน: Apache Spark Architecture
สารบัญ
การประมวลผลแบบขนานคืออะไร?
การประมวลผลแบบขนานเป็นหนึ่งในการดำเนินการที่สำคัญของระบบข้อมูลขนาดใหญ่ เมื่องานของคุณมีความสำคัญ คุณจะแบ่งงานย่อยๆ แล้วแก้ปัญหาแต่ละอย่างแยกกัน การประมวลผลข้อมูลขนาดใหญ่แบบคู่ขนานเกี่ยวข้องกับกระบวนการเดียวกัน

ในทางเทคนิคแล้ว การประมวลผลแบบขนานเป็นวิธีการเรียกใช้สองส่วนหรือมากกว่าของปัญหาใหญ่เพียงส่วนเดียวในโปรเซสเซอร์ที่ต่างกัน ซึ่งจะช่วยลดเวลาในการประมวลผลและเพิ่มประสิทธิภาพ
เนื่องจากคุณไม่สามารถดำเนินการกับชุดข้อมูลขนาดใหญ่ในเครื่องเดียวได้ คุณจึงต้องมีบางสิ่งที่แข็งแกร่งมาก นั่นคือจุดที่การขนานกันใน Spark เข้ามาในภาพอย่างแม่นยำ ตอนนี้เราจะนำคุณไปสู่การประมวลผล Spark Parallel และวิธีทำให้ Spark Parallel ขนานกันเพื่อให้ได้ผลลัพธ์ที่ถูกต้องจากชุดข้อมูลขนาดใหญ่
การประมวลผลแบบขนานของประกายไฟ
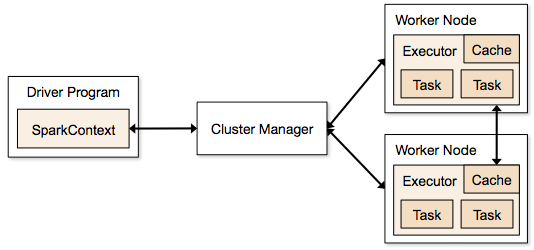
แอปพลิเคชัน Spark ทำงานในรูปแบบของกระบวนการอิสระที่อยู่บนคลัสเตอร์และประสานงานโดย SparkContext ในโปรแกรมหลัก
ขั้นตอนแรกในการรันโปรแกรม Spark คือการส่งงานโดยใช้ Spark-submit สคริปต์ spark-submit ใช้เพื่อเรียกใช้โปรแกรมบนคลัสเตอร์
เมื่อคุณส่งงานโดยใช้สคริปต์ spark-submit งานจะถูกส่งต่อไปยังไดรเวอร์ sparkcontext โปรแกรมไดรเวอร์ Sparkcontext เป็นจุดเริ่มต้นของ Spark Sparkcontext กำหนดเส้นทางโปรแกรมไปยังโมดูลเช่น Cluster Master Node และ RDD ซึ่งสร้างโดยโปรแกรมไดรเวอร์ Sparkcontext เหล่านี้
จากนั้นโปรแกรมจะถูกส่งไปยัง Cluster Master Node ทุกคลัสเตอร์มีโหนดหลักหนึ่งโหนดซึ่งดำเนินการประมวลผลที่จำเป็นทั้งหมด มันส่งต่อโปรแกรมเพิ่มเติมไปยังโหนดผู้ปฏิบัติงาน
โหนดผู้ปฏิบัติงานคือโหนดที่แก้ปัญหา โหนดหลักประกอบด้วยตัวดำเนินการที่ดำเนินการด้วยไดรเวอร์ Sparkcontext
 แหล่งที่มา
แหล่งที่มา
Resilient Distributed Dataset (RDD) คืออะไร
RDD เป็นโครงสร้างข้อมูลพื้นฐานของ Apache Spark โครงสร้างข้อมูลนี้เป็นคอลเล็กชันที่ไม่เปลี่ยนรูปของอ็อบเจ็กต์ที่คำนวณบนโหนดต่างๆ ของคลัสเตอร์ ชุดข้อมูลทุกชุดใน Spark RDD ถูกแบ่งพาร์ติชั่นตามตรรกะบนเซิร์ฟเวอร์ต่างๆ ดังนั้นการคำนวณจึงทำงานได้อย่างราบรื่นบนแต่ละโหนด

ให้เราเข้าใจ RDD ในรายละเอียดมากขึ้น เนื่องจากเป็นพื้นฐานของการขนานกันในประกายไฟ เราสามารถแบ่งชื่อออกเป็นสามส่วนและรู้ว่าเหตุใดโครงสร้างข้อมูลจึงตั้งชื่อเช่นนั้น
- ยืดหยุ่น : หมายความว่าโครงสร้างข้อมูลมีความทนทานต่อข้อผิดพลาดด้วยความช่วยเหลือของกราฟเชื้อสาย RDD และด้วยเหตุนี้จึงสามารถคำนวณพาร์ติชั่นที่ขาดหายไปหรือพาร์ติชั่นที่เสียหายซึ่งเกิดจากความล้มเหลวของโหนด
- กระจาย: สิ่งนี้เป็นจริงสำหรับระบบทั้งหมดที่ใช้สภาพแวดล้อมแบบกระจาย เรียกว่ากระจายเนื่องจากมีข้อมูลอยู่บนโหนดต่างๆ/หลายโหนด
- ชุดข้อมูล: ชุดข้อมูลแสดงถึงข้อมูลที่คุณใช้งาน คุณสามารถนำเข้าชุดข้อมูลที่มีอยู่ในรูปแบบใดก็ได้ เช่น .csv, .json, ไฟล์ข้อความ หรือฐานข้อมูล คุณสามารถทำได้โดยใช้ JDBC โดยไม่มีโครงสร้างเฉพาะ
เมื่อคุณนำเข้าหรือโหลดชุดข้อมูลของคุณ RDD จะแบ่งพาร์ติชันข้อมูลของคุณออกเป็นหลายโหนดในเซิร์ฟเวอร์จำนวนมากตามตรรกะ เพื่อให้การดำเนินการทำงานต่อไป
อ่านเพิ่มเติม: คุณสมบัติ Apache Spark
เมื่อคุณรู้จัก RDD แล้ว คุณจะเข้าใจการประมวลผล Spark Parallel ได้ง่ายขึ้น
ขนานกันใน Spark โดยใช้ RDD
การประมวลผลแบบขนานดำเนินการใน 4 ขั้นตอนสำคัญใน Apache Spark RDD ใช้ในระดับหลักเพื่อขนานกันในจุดประกายเพื่อดำเนินการประมวลผลแบบขนาน
ขั้นตอนที่ 1
RDD มักจะสร้างจากแหล่งข้อมูลภายนอก อาจเป็นไฟล์ CSV ไฟล์ JSON หรือฐานข้อมูลสำหรับเรื่องนั้น ในกรณีส่วนใหญ่ จะเป็น HDFS หรือไฟล์ในเครื่อง
ขั้นตอนที่ 2
หลังจากขั้นตอนแรก RDD จะผ่านการแปลงแบบคู่ขนานสองสามอย่าง เช่น ตัวกรอง แผนที่ groupBy และการเข้าร่วม การแปลงแต่ละรูปแบบเหล่านี้ให้ RDD ที่แตกต่างกันซึ่งนำไปสู่การเปลี่ยนแปลงครั้งต่อไป
รับ ใบรับรองวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก เข้าร่วมโปรแกรม Executive PG, Advanced Certificate Programs หรือ Masters Programs ของเราเพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
ขั้นตอนที่ 3
ขั้นตอนสุดท้ายเกี่ยวกับการกระทำ มันเป็นเสมอ RDD ในขั้นตอนนี้ จะถูกส่งออกเป็นเอาต์พุตภายนอกไปยังแหล่งข้อมูลภายนอก

เช็คเอาท์: บทช่วยสอน Apache Spark สำหรับผู้เริ่มต้น
บทสรุป
การประมวลผลแบบขนานกำลังได้รับความนิยมในหมู่ผู้ที่ชื่นชอบข้อมูล เนื่องจากข้อมูลเชิงลึกช่วยให้บริษัทและ OTT มีรายได้มหาศาล ในทางกลับกัน Spark เป็นหนึ่งในเครื่องมือที่ช่วยให้ยักษ์ใหญ่ในการตัดสินใจโดยดำเนินการประมวลผลแบบขนานกับข้อมูลขนาดใหญ่และขนาดใหญ่
หากคุณกำลังรอคอยที่จะทำให้การประมวลผลข้อมูลขนาดใหญ่เร็วขึ้น Apache spark คือหนทางของคุณ และ RDD ใน Spark ก็ให้ประสิทธิภาพที่ดีที่สุดนับตั้งแต่เป็นที่รู้จัก
หากคุณสนใจที่จะทราบข้อมูลเพิ่มเติมเกี่ยวกับ Big Data โปรดดูที่ PG Diploma in Software Development Specialization in Big Data program ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีกรณีศึกษาและโครงการมากกว่า 7 กรณี ครอบคลุมภาษาและเครื่องมือในการเขียนโปรแกรม 14 รายการ เวิร์กช็อป ความช่วยเหลือด้านการเรียนรู้และจัดหางานอย่างเข้มงวดมากกว่า 400 ชั่วโมงกับบริษัทชั้นนำ
เรียนรู้ หลักสูตรการพัฒนาซอฟต์แวร์ ออนไลน์จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม Executive PG โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว