Comment paralléliser dans Spark Parallel Processing ? [Utilisation RDD]
Publié: 2020-09-03La génération et la consommation de données ont été multipliées par n au cours des dernières années. Avec autant de plates-formes qui voient le jour, le traitement et la gestion soigneuse des données sont devenus cruciaux. L'IA (intelligence artificielle) et le ML (apprentissage automatique) rendent nos expériences numériques encore plus fluides en trouvant de meilleures solutions à nos problèmes. Par conséquent, les entreprises s'orientent désormais vers le traitement des données et en tirent des enseignements.
Simultanément, les données générées par les entreprises, les acteurs du réseau et les géants du mobile sont énormes. Grâce à cela, le concept de big data a été introduit. Depuis que le big data est entré en scène, les outils de gestion et de manipulation du big data ont également commencé à gagner en popularité et en importance.
Apache Spark est l'un de ces outils qui manipulent et traitent des ensembles de données massifs pour obtenir des informations à partir de ces données. Ces grands ensembles de données ne peuvent pas être traités ou gérés en une seule passe car la puissance de calcul requise est trop intense.
C'est là que le traitement parallèle entre en scène. Nous commencerons par comprendre le traitement parallèle en bref, puis passerons à comprendre comment paralléliser Spark.
Lire : Architecture Apache Spark
Table des matières
Qu'est-ce que le traitement parallèle ?
Le traitement parallèle est l'une des opérations essentielles d'un système Big Data. Lorsque votre tâche est importante, vous vous divisez en tâches plus petites, puis résolvez chacune indépendamment. Le traitement parallèle des mégadonnées implique le même processus.

Techniquement parlant, le traitement parallèle est une méthode d'exécution de deux parties ou plus d'un seul gros problème dans différents processeurs. Cela réduit le temps de traitement et améliore les performances.
Comme vous ne pouvez pas effectuer d'opérations sur de grands ensembles de données sur une seule machine, vous avez besoin de quelque chose de très solide. C'est précisément là que la parallélisation dans Spark entre en jeu. Nous allons maintenant vous guider à travers le traitement parallèle Spark et comment paralléliser dans Spark pour obtenir la bonne sortie à partir de grands ensembles de données.
Traitement parallèle Spark
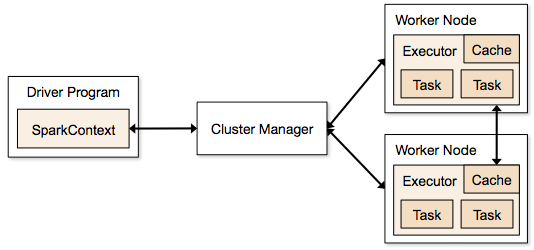
Les applications Spark s'exécutent sous la forme de processus indépendants qui résident sur des clusters et sont coordonnés par SparkContext dans le programme principal.
La première étape de l'exécution d'un programme Spark consiste à soumettre le travail à l'aide de Spark-submit. Le script spark-submit est utilisé pour lancer le programme sur un cluster.
Une fois que vous avez soumis le travail à l'aide d'un script spark-submit, le travail est transmis aux pilotes sparkcontext. Le programme pilote Sparkcontext est le point d'entrée de Spark. Sparkcontext achemine le programme vers les modules tels que Cluster Master Node et les RDD sont également créés par ces programmes de pilote Sparkcontext.
Le programme est ensuite transmis au Cluster Master Node. Chaque cluster a un nœud maître qui effectue tout le traitement nécessaire. Il transmet ensuite le programme aux nœuds de travail.
Le nœud de travail est celui qui résout les problèmes. Les nœuds maîtres contiennent des exécuteurs qui s'exécutent avec le pilote Sparkcontext.
 La source
La source
Qu'est-ce qu'un jeu de données distribué résilient (RDD) ?
RDD est la structure de données fondamentale d'Apache Spark. Cette structure de données est une collection immuable d'objets qui calculent sur différents nœuds d'un cluster. Chaque jeu de données dans Spark RDD est logiquement partitionné sur différents serveurs afin que les calculs puissent être exécutés sans problème sur chaque nœud.

Comprenons RDD un peu plus en détail, car il constitue la base de la parallélisation dans spark. Nous pouvons diviser le nom en trois parties et savoir pourquoi la structure de données est nommée ainsi.
- Résilient : cela signifie que la structure de données est tolérante aux pannes à l'aide du graphe de lignage RDD, et par conséquent, elle peut recalculer les partitions manquantes ou les partitions endommagées causées par des défaillances de nœuds.
- Distribué : cela est vrai pour tous les systèmes qui utilisent un environnement distribué. Il est appelé distribué car les données sont disponibles sur différents/multiples nœuds.
- Jeu de données : le jeu de données représente les données avec lesquelles vous travaillez. Vous pouvez importer n'importe lequel des ensembles de données disponibles dans n'importe quel format comme .csv, .json, un fichier texte ou une base de données. Vous pouvez le faire en utilisant JDBC sans structure spécifique.
Une fois que vous importez ou chargez votre ensemble de données, les RDD partitionneront logiquement vos données en plusieurs nœuds sur de nombreux serveurs, pour que l'opération continue de fonctionner.
Lisez également : Fonctionnalités d'Apache Spark
Maintenant que vous connaissez RDD, il vous sera plus facile de comprendre Spark Parallel Processing.
Paralléliser dans Spark à l'aide de RDD
Le traitement parallèle s'effectue en 4 étapes significatives dans Apache Spark. RDD est utilisé à un niveau majeur pour paralléliser Spark afin d'effectuer un traitement parallèle.
Étape 1
RDD est généralement créé à partir d'une source de données externe. Il peut s'agir d'un fichier CSV, d'un fichier JSON ou simplement d'une base de données. Dans la plupart des cas, il s'agit d'un HDFS ou d'un fichier local.
Étape 2
Après la première étape, RDD passerait par quelques transformations parallèles telles que filter, map, groupBy et join. Chacune de ces transformations fournit un RDD différent qui passe à la transformation suivante.
Obtenez une certification en science des données des meilleures universités du monde. Rejoignez nos programmes Executive PG, Advanced Certificate Programs ou Masters Programs pour accélérer votre carrière.
Étape 3
La dernière étape concerne l'action; c'est toujours le cas. Le RDD, à ce stade, est exporté en tant que sortie externe vers des sources de données externes.

Consultez : Didacticiel Apache Spark pour les débutants
Conclusion
Le traitement parallèle gagne en popularité parmi les passionnés de données, car les informations aident les entreprises et les OTT à gagner gros. Spark, d'autre part, est l'un des outils aidant les grands géants à prendre des décisions en effectuant un traitement parallèle sur des données de plus en plus volumineuses.
Si vous souhaitez accélérer le traitement du Big Data, Apache Spark est votre solution. Et, les RDD dans Spark offrent les meilleures performances depuis qu'elles sont connues.
Si vous souhaitez en savoir plus sur le Big Data, consultez notre programme PG Diploma in Software Development Specialization in Big Data qui est conçu pour les professionnels en activité et fournit plus de 7 études de cas et projets, couvre 14 langages et outils de programmation, pratique pratique ateliers, plus de 400 heures d'apprentissage rigoureux et d'aide au placement dans les meilleures entreprises.
Apprenez des cours de développement de logiciels en ligne dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.