كيفية الموازاة في Spark Parallel Processing؟ [باستخدام RDD]
نشرت: 2020-09-03زاد توليد واستهلاك البيانات بمقدار n أضعاف خلال السنوات القليلة الماضية. مع ظهور العديد من الأنظمة الأساسية ، أصبح التعامل مع البيانات وإدارتها بعناية أمرًا بالغ الأهمية. يعمل الذكاء الاصطناعي (AI) و ML (التعلم الآلي) على جعل تجاربنا الرقمية أكثر سلاسة من خلال إيجاد حلول أفضل لمشاكلنا. لذلك ، تتجه الشركات الآن نحو معالجة البيانات وإيجاد رؤى منها.
في الوقت نفسه ، فإن البيانات التي تم إنشاؤها بواسطة الشركات ومشغلي الشبكات وعمالقة المحمول هائلة. نتيجة لذلك ، تم تقديم مفهوم البيانات الضخمة. منذ ظهور البيانات الضخمة في الصورة ، بدأت أدوات إدارة البيانات الضخمة ومعالجتها أيضًا تكتسب شعبية وأهمية.
تعد Apache Spark واحدة من تلك الأدوات التي تتعامل مع مجموعات البيانات الضخمة وتعالجها لاكتساب رؤى من هذه البيانات. لا يمكن معالجة مجموعات البيانات الكبيرة هذه أو إدارتها في مسار واحد لأن الطاقة الحسابية المطلوبة مكثفة للغاية.
هذا هو المكان الذي تأتي فيه المعالجة المتوازية في الصورة. سنبدأ بفهم المعالجة المتوازية باختصار ثم ننتقل إلى فهم كيفية الموازاة في الشرارة.
قراءة: Apache Spark Architecture
جدول المحتويات
ما هي المعالجة المتوازية؟
المعالجة المتوازية هي إحدى العمليات الأساسية لنظام البيانات الضخمة. عندما تكون مهمتك مهمة ، تصادف أنك تقسم إلى مهام أصغر ثم تحل كل مهمة على حدة. تتضمن المعالجة المتوازية للبيانات الضخمة نفس العملية.

من الناحية الفنية ، المعالجة المتوازية هي طريقة لتشغيل جزأين أو أكثر من مشكلة واحدة كبيرة في معالجات مختلفة. هذا يقلل من وقت المعالجة ويعزز الأداء.
نظرًا لأنه لا يمكنك إجراء عمليات على مجموعات البيانات الكبيرة على جهاز واحد ، فأنت بحاجة إلى شيء قوي للغاية. هذا هو بالضبط المكان الذي يأتي فيه التوازي في Spark في الصورة. سنأخذك الآن من خلال Spark Parallel Processing وكيفية الموازاة في الشرارة للحصول على المخرجات الصحيحة من مجموعات البيانات الكبيرة.
شرارة المعالجة المتوازية
تعمل تطبيقات Spark في شكل عمليات مستقلة موجودة في مجموعات ويتم تنسيقها بواسطة SparkContext في البرنامج الرئيسي.
تتمثل الخطوة الأولى في تشغيل برنامج Spark في إرسال الوظيفة باستخدام Spark-submit. يتم استخدام البرنامج النصي لتقديم شرارة لبدء تشغيل البرنامج على كتلة.
بمجرد إرسال الوظيفة باستخدام برنامج نصي لإرسال شرارة ، تتم إعادة توجيه الوظيفة إلى برامج تشغيل sparkcontext. برنامج تشغيل Sparkcontext هو نقطة الدخول إلى Spark. يقوم Sparkcontext بتوجيه البرنامج إلى الوحدات النمطية مثل Cluster Master Node و RDDs التي يتم إنشاؤها أيضًا بواسطة برامج تشغيل Sparkcontext هذه.
ثم يتم منح البرنامج إلى العقدة الرئيسية للكتلة. كل مجموعة لها عقدة رئيسية واحدة تقوم بتنفيذ جميع العمليات اللازمة. يقوم بإعادة توجيه البرنامج إلى العقد العاملة.
العقدة العاملة هي التي تحل المشاكل. تحتوي العقد الرئيسية على منفذين يتم تنفيذها باستخدام برنامج تشغيل Sparkcontext.
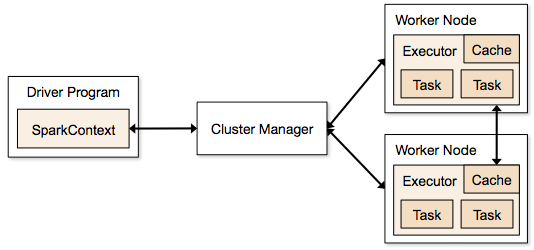 مصدر
مصدر
ما هي مجموعة البيانات الموزعة المرنة (RDD)؟
RDD هو هيكل البيانات الأساسي لـ Apache Spark. هيكل البيانات هذا عبارة عن مجموعة غير قابلة للتغيير من الكائنات التي يتم حسابها على عقد مختلفة من الكتلة. يتم تقسيم كل مجموعة بيانات في Spark RDD منطقيًا عبر خوادم مختلفة بحيث يمكن تشغيل الحسابات بسلاسة على كل عقدة.

دعونا نفهم RDD بمزيد من التفصيل ، لأنه يشكل أساس التوازي في الشرارة. يمكننا تقسيم الاسم إلى ثلاثة أجزاء ومعرفة سبب تسمية بنية البيانات بذلك.
- مرن : يعني أن بنية البيانات تتسامح مع الأخطاء بمساعدة الرسم البياني لنسب RDD ، وبالتالي ، يمكنها إعادة حساب الأقسام المفقودة أو الأجزاء التالفة الناتجة عن فشل العقدة.
- موزعة: هذا ينطبق على جميع الأنظمة التي تستخدم بيئة موزعة. يطلق عليه موزعة لأن البيانات متاحة على عقد مختلفة / متعددة.
- مجموعة البيانات: تمثل مجموعة البيانات البيانات التي تستخدمها معها. يمكنك استيراد أي من مجموعات البيانات المتاحة بأي تنسيق مثل .csv أو .json أو ملف نصي أو قاعدة بيانات. يمكنك القيام بذلك باستخدام JDBC بدون بنية محددة.
بمجرد استيراد مجموعة البيانات الخاصة بك أو تحميلها ، ستقوم RDDs بشكل منطقي بتقسيم بياناتك إلى عدة عقد عبر العديد من الخوادم ، للحفاظ على تشغيل العملية.
اقرأ أيضًا: ميزات Apache Spark
الآن بعد أن عرفت RDD ، سيكون من الأسهل عليك فهم المعالجة المتوازية Spark.
بالتوازي مع شرارة باستخدام RDD
تتم المعالجة المتوازية في 4 خطوات مهمة في Apache Spark. يتم استخدام RDD على مستوى رئيسي للتوازي في الشرارة لإجراء معالجة موازية.
الخطوة 1
عادة ما يتم إنشاء RDD من مصدر بيانات خارجي. يمكن أن يكون ملف CSV أو ملف JSON أو مجرد قاعدة بيانات لهذه المسألة. في معظم الحالات ، يكون ملف HDFS أو ملفًا محليًا.
الخطوة 2
بعد الخطوة الأولى ، سوف يمر RDD ببعض التحولات المتوازية مثل المرشح ، الخريطة ، المجموعة ، والانضمام. يوفر كل من هذه التحولات RDD مختلفًا يتقدم إلى التحول التالي.
احصل على شهادة علوم البيانات من أفضل الجامعات في العالم. انضم إلى برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.
الخطوه 3
المرحلة الأخيرة تدور حول العمل. هو دائما كذلك. يتم تصدير RDD ، في هذه المرحلة ، كإخراج خارجي إلى مصادر البيانات الخارجية.

تحقق من: Apache Spark تعليمي للمبتدئين
خاتمة
تكتسب المعالجة المتوازية شعبية بين عشاق البيانات ، حيث تساعد الرؤى الشركات و OTTs على تحقيق مكاسب كبيرة. Spark ، من ناحية أخرى ، هي إحدى الأدوات التي تساعد العمالقة الكبار على اتخاذ القرارات من خلال إجراء معالجة متوازية على البيانات الكبيرة والأكبر.
إذا كنت تتطلع إلى جعل معالجة البيانات الضخمة أسرع ، فإن Apache spark هي طريقك للذهاب. وتقدم RDDs في Spark أفضل أداء منذ أن عُرفت.
إذا كنت مهتمًا بمعرفة المزيد عن البيانات الضخمة ، فراجع دبلومة PG في تخصص تطوير البرمجيات في برنامج البيانات الضخمة المصمم للمهنيين العاملين ويوفر أكثر من 7 دراسات حالة ومشاريع ، ويغطي 14 لغة وأدوات برمجة ، وتدريب عملي عملي ورش العمل ، أكثر من 400 ساعة من التعلم الصارم والمساعدة في التوظيف مع الشركات الكبرى.
تعلم دورات تطوير البرمجيات عبر الإنترنت من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.