
강화 학습에 대한 심층 분석
게시 됨: 2022-03-11강화 학습에 대해 자세히 살펴보겠습니다. 이 기사에서는 TensorFlow, TensorBoard, Keras 및 OpenAI 체육관과 같은 최신 라이브러리의 구체적인 문제를 다룰 것입니다. 내부 작동을 학습하기 위해 deep $Q$-learning이라는 기본 알고리즘 중 하나를 구현하는 방법을 볼 수 있습니다. 하드웨어와 관련하여 전체 코드는 일반적인 PC에서 작동하고 발견된 모든 CPU 코어를 사용합니다(TensorFlow에서 즉시 처리됨).
문제는 Mountain Car라고 합니다. 자동차는 두 산 사이에 위치한 1차원 트랙에 있습니다. 목표는 오른쪽에 있는 산을 올라가는 것입니다(깃발에 도달). 하지만 차의 엔진은 한 번에 산을 오를 만큼 강하지 않다. 따라서 성공할 수 있는 유일한 방법은 앞뒤로 운전하여 추진력을 구축하는 것입니다.
이 문제는 단일 CPU 코어에서 몇 분 만에 강화 학습 솔루션을 찾을 수 있을 만큼 간단하기 때문에 선택되었습니다. 그러나 좋은 대표자가 되기에는 충분히 복잡합니다.
먼저 강화 학습이 일반적으로 하는 일에 대해 간략히 설명하겠습니다. 그런 다음 기본 용어를 다루고 문제를 표현합니다. 그런 다음 Deep $Q$-learning 알고리즘을 설명하고 이를 구현하여 문제를 해결합니다.
강화 학습 기초
강화학습은 쉽게 말해서 시행착오를 통한 학습입니다. 주인공은 "에이전트"라고 불리며, 우리 문제에서 자동차가 될 것입니다. 에이전트는 환경에서 행동을 하고 새로운 관찰과 그 행동에 대한 보상을 받습니다. 더 큰 보상으로 이어지는 행동이 강화되어 이름이 붙여졌습니다. 컴퓨터 과학의 다른 많은 것들과 마찬가지로, 이것 역시 살아있는 생물을 관찰하면서 영감을 받았습니다.
에이전트와 환경의 상호 작용은 다음 그래프에 요약되어 있습니다.
에이전트는 수행된 작업에 대한 관찰과 보상을 받습니다. 그런 다음 다른 작업을 수행하고 2단계를 수행합니다. 환경은 이제 (아마도) 약간 다른 관찰과 보상을 반환합니다. 이것은 에이전트에게 "done"을 보내서 터미널 상태에 도달할 때까지 계속됩니다. 관찰 > 행동 > 다음_관찰 > 보상 의 전체 순서를 에피소드(또는 궤적)라고 합니다.
마운틴 카로 돌아가서: 우리 차는 에이전트입니다. 환경은 1차원 산의 블랙박스 세계입니다. 자동차의 동작은 단 하나의 숫자로 요약됩니다. 긍정적인 경우 엔진은 자동차를 오른쪽으로 밀어냅니다. 음수이면 차를 왼쪽으로 밀어냅니다. 에이전트는 차량의 X 위치 및 속도와 같은 관찰을 통해 환경을 인식합니다. 우리 차가 산 정상을 주행하기를 원하면 편리한 방식으로 보상을 정의합니다. 에이전트는 목표에 도달하지 못한 모든 단계에 대해 보상에 -1을 받습니다. 목표에 도달하면 에피소드가 종료됩니다. 따라서 실제로 에이전트는 우리가 원하는 위치에 있지 않은 것에 대해 처벌을 받습니다. 더 빨리 도달할수록 그에게는 더 좋습니다. 에이전트의 목표는 한 에피소드의 보상 합계인 총 보상을 최대화하는 것입니다. 따라서 예를 들어 110보 후에 원하는 지점에 도달하면 총 -110의 리턴을 받게 되는데, 이는 마운틴카에게 좋은 결과가 될 것입니다. 목표에 도달하지 못하면 200보를 벌하기 때문입니다. (따라서 -200의 반환).
이것이 전체 문제 공식입니다. 이제 몇 분 만에 이러한 문제를 해결할 수 있을 만큼 강력한 알고리즘에 이를 제공할 수 있습니다(잘 조정된 경우). 에이전트에게 목표를 달성하는 방법을 알려주지 않는다는 점은 주목할 가치가 있습니다. 우리는 힌트도 제공하지 않습니다(휴리스틱). 에이전트는 스스로 이길 수 있는 방법(정책)을 찾을 것입니다.
환경 설정
먼저 전체 자습서 코드를 디스크에 복사합니다.
git clone https://github.com/AdamStelmaszczyk/rl-tutorial cd rl-tutorial이제 사용할 Python 패키지를 설치해야 합니다. 사용자 공간에 설치하지 않기 위해(및 충돌 위험), 우리는 그것을 깨끗하게 만들고 conda 환경에 설치할 것입니다. conda가 설치되어 있지 않다면 https://conda.io/docs/user-guide/install/index.html을 따르십시오.
conda 환경을 생성하려면:
conda create -n tutorial python=3.6.5 -y활성화하려면:
source activate tutorial 쉘의 프롬프트 근처에 (tutorial) 가 표시되어야 합니다. "tutorial"이라는 이름의 콘다 환경이 활성화되어 있음을 의미합니다. 이제부터 모든 명령은 해당 conda 환경 내에서 실행되어야 합니다.
이제 밀폐형 콘다 환경에 모든 종속성을 설치할 수 있습니다.
pip install -r requirements.txt설치가 완료되었으므로 코드를 실행해 보겠습니다. Mountain Car 환경을 직접 구현할 필요는 없습니다. OpenAI 체육관 라이브러리는 그 구현을 제공합니다. 우리 환경에서 임의의 에이전트(임의의 행동을 취하는 에이전트)를 살펴보겠습니다.
import gym env = gym.make('MountainCar-v0') done = True episode = 0 episode_return = 0.0 for episode in range(5): for step in range(200): if done: if episode > 0: print("Episode return: ", episode_return) obs = env.reset() episode += 1 episode_return = 0.0 env.render() else: obs = next_obs action = env.action_space.sample() next_obs, reward, done, _ = env.step(action) episode_return += reward env.render() 이것은 see.py 파일입니다. 실행하려면 다음을 실행하십시오.
python see.py무작위로 앞뒤로 움직이는 차가 보일 것입니다. 각 에피소드는 200단계로 구성됩니다. 총 수익은 -200입니다.
이제 무작위 작업을 더 나은 것으로 대체해야 합니다. 사용할 수 있는 알고리즘이 많이 있습니다. 입문 튜토리얼의 경우 deep $Q$-learning이라는 접근 방식이 적합하다고 생각합니다. 그 방법을 이해하면 다른 접근 방식을 배우기 위한 확고한 기반을 얻을 수 있습니다.
심층 $Q$ 학습
우리가 사용할 알고리즘은 2013년 Mnih et al. Deep Reinforcement Learning으로 Atari 플레이하기에서 그리고 2년 후 Deep Reinforcement Learning을 통한 인간 수준 제어에서 연마했습니다. 현재 최신 알고리즘인 Rainbow(2017)를 비롯한 많은 다른 작업이 이러한 결과를 기반으로 합니다.
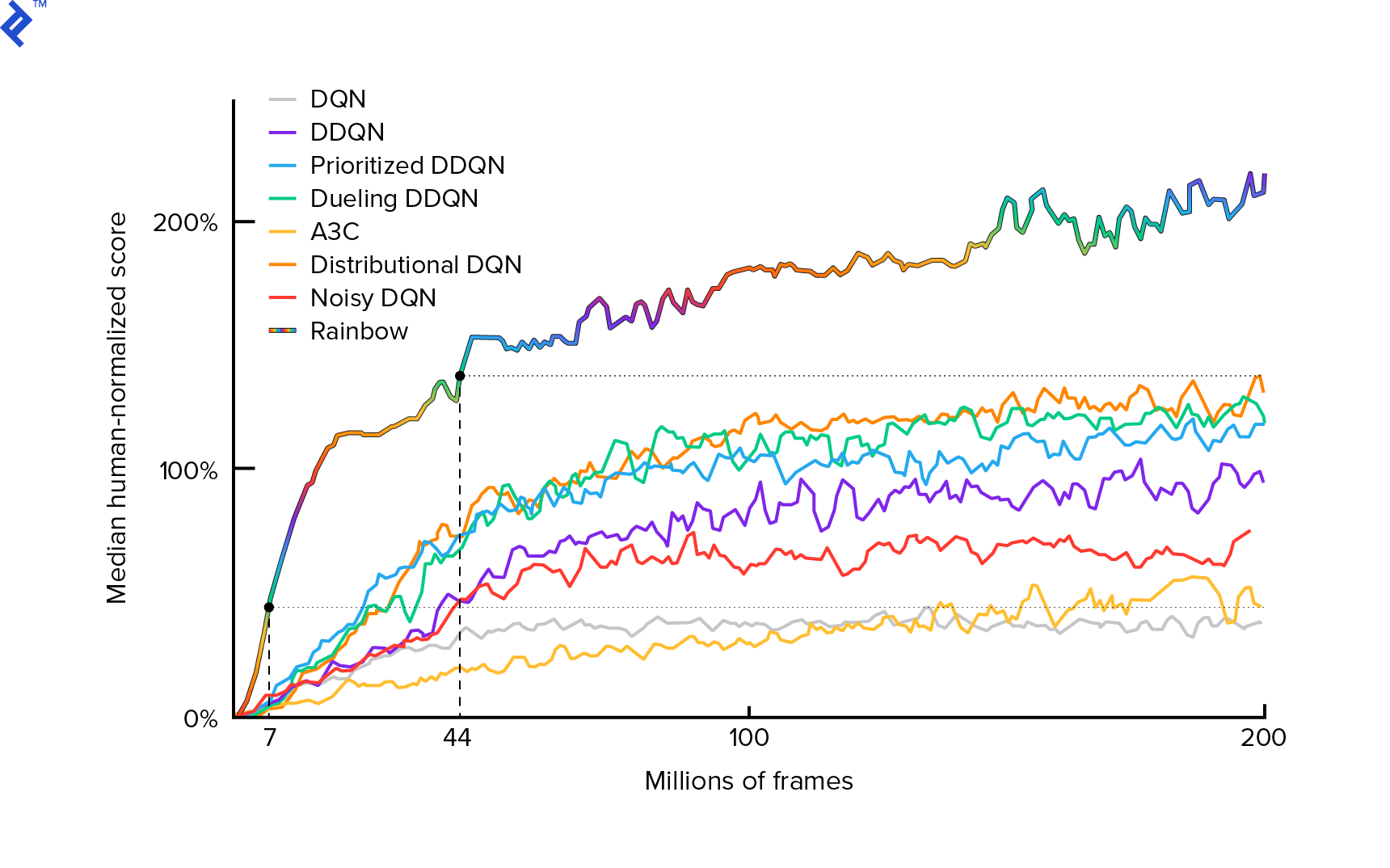
Rainbow는 많은 Atari 2600 게임에서 초인적인 성능을 발휘합니다. 이 튜토리얼을 적당한 크기로 유지하기 위해 가능한 한 적은 수의 추가 개선 사항이 있는 기본 DQN 버전에 중점을 둘 것입니다.
일반적으로 $π(s)$로 표시되는 정책은 주어진 상태 $s$에서 개별 조치를 취할 확률을 반환하는 함수입니다. 예를 들어 임의의 Mountain Car 정책은 모든 상태(왼쪽 50%, 오른쪽 50%)에 대해 반환합니다. 게임 플레이 중에 해당 정책(배포)에서 샘플링하여 실제 작업을 얻습니다.
$Q$-학습(Q는 품질을 나타냄)은 $Q_π(s, a)$로 표시된 행동 가치 함수를 나타냅니다. 구체적인 정책 $π$에 따라 $a$ 조치를 선택하여 주어진 상태 $s$에서 총 수익을 반환합니다. 총 수익은 한 에피소드(궤적)에 있는 모든 보상의 합계입니다.
$Q^*$로 표시된 최적의 $Q$ 함수를 알고 있다면 게임을 쉽게 풀 수 있습니다. 우리는 $Q^*$의 가장 높은 값, 즉 가장 높은 기대 수익을 가진 행동을 따를 것입니다. 이것은 우리가 가능한 가장 높은 수익에 도달할 것임을 보장합니다.
그러나 우리는 종종 $Q^*$를 모릅니다. 그러한 경우 우리는 환경과의 상호 작용을 통해 근사하거나 "학습"할 수 있습니다. 이름의 "$Q$-learning" 부분입니다. 그 함수를 근사하기 위해 범용 함수 근사기인 심층 신경망을 사용할 것이기 때문에 "deep"라는 단어도 있습니다. $Q$ 값에 근접하는 심층 신경망은 DQN(Deep Q-Networks)으로 명명되었습니다. 간단한 환경(메모리에 맞는 상태의 수)에서는 신경망 대신 테이블을 사용하여 $Q$-함수를 나타낼 수 있으며, 이 경우 "테이블 형식 $Q$-학습"이라는 이름이 지정됩니다.
따라서 이제 우리의 목표는 $Q^*$ 함수를 근사화하는 것입니다. Bellman 방정식을 사용합니다.
\[Q(s, a) = r + γ \space \textrm{최대}_{a'} Q(s', a')\]$s'$는 $s$ 이후의 상태입니다. $γ$(감마), 일반적으로 0.99는 할인 요인입니다(초매개변수). 그것은 미래의 보상에 더 작은 비중을 둡니다. (왜냐하면 그것들은 우리의 불완전한 $Q$에 대한 즉각적인 보상보다 덜 확실하기 때문입니다). Bellman 방정식은 심층 $Q$ 학습의 핵심입니다. 주어진 주와 행동에 대한 $Q$-value는 $a$ 행동을 취한 후 받은 보상 $r$에 $s'$에 도착한 주에서 가장 높은 $Q$-value를 더한 것입니다. 가장 높은 것은 $a'$ 행동을 선택한다는 의미에서 $s'$에서 가장 높은 총 수익으로 이어집니다.
벨만 방정식을 사용하여 지도 학습을 사용하여 $Q^*$를 근사화할 수 있습니다. $Q$ 함수는 $θ$(세타)로 표시된 신경망 가중치로 표현(매개변수화)됩니다. 간단한 구현은 상태와 동작을 네트워크 입력으로 취하고 Q 값을 출력합니다. 비효율성은 주어진 상태의 모든 작업에 대한 $Q$ 값을 알고 싶다면 해당 작업만큼 $Q$를 호출해야 한다는 것입니다. 훨씬 더 좋은 방법이 있습니다. 상태만 입력으로 사용하고 가능한 모든 작업에 대해 $Q$ 값을 출력하는 것입니다. 그 덕분에 단 한 번의 정방향 전달에서 모든 작업에 대해 $Q$-값을 얻을 수 있습니다.
무작위 가중치로 $Q$ 네트워크 훈련을 시작합니다. 환경에서 우리는 많은 전환(또는 "경험")을 얻습니다. 이것들은 (state, action, next state, reward) 또는 간단히 ($s$, $a$, $s'$, $r$)의 튜플입니다. 우리는 "경험 재생"이라는 링 버퍼에 수천 개를 저장합니다. 그런 다음 Bellman 방정식이 유지되기를 바라는 마음으로 해당 버퍼에서 경험을 샘플링합니다. 버퍼를 건너뛰고 경험을 하나씩 적용할 수 있었습니다(이를 "온라인" 또는 "정책상"이라고 함). 문제는 후속 경험이 서로 높은 상관 관계가 있고 이것이 발생하면 DQN이 제대로 훈련되지 않는다는 것입니다. 그렇기 때문에 이 데이터 상관 관계를 분석하기 위해 경험 재생이 도입되었습니다("오프라인", "오프 정책" 접근 방식). 가장 간단한 링 버퍼 구현 코드는 replay_buffer.py 파일에서 찾을 수 있습니다. 읽어보시기 바랍니다.
처음에는 신경망 가중치가 무작위였기 때문에 Bellman 방정식의 왼쪽 값은 오른쪽에서 멀리 떨어져 있습니다. 제곱된 차이가 손실 함수가 됩니다. 신경망 가중치 $θ$를 변경하여 손실 함수를 최소화합니다. 손실 함수를 작성해 보겠습니다.
\[L(θ) = [Q(s, a) - r - γ \space \textrm{max}_{a'}Q(s', a')]^2\]다시 작성된 벨만 방정식입니다. Mountain Car 경험 리플레이에서 경험($s$, left, $s'$, -1)을 샘플링했다고 가정해 보겠습니다. 예를 들어 $s$ 상태로 $Q$ 네트워크를 통해 정방향 전달을 수행하고 남은 작업에 대해 -120을 제공합니다. 따라서 $Q(s, \textrm{left}) = -120$입니다. 그런 다음 $s'$를 네트워크에 공급합니다. 예를 들어 왼쪽은 -130이고 오른쪽은 -122입니다. 따라서 $s'$에 대한 최선의 조치는 옳습니다. 따라서 $\textrm{max}_{a'}Q(s', a') = -122$입니다. 우리는 $r$을 알고 있습니다. 이것은 -1이었던 실제 보상입니다. 따라서 $L(θ) = [-120 - 1 + 0.99 ⋅ 122]^2 = (-0.22^2) = 0.0484$이기 때문에 우리의 $Q$-네트워크 예측은 약간 잘못되었습니다. 그래서 우리는 오류를 역전파하고 가중치 $θ$를 약간 수정합니다. 동일한 경험에 대해 손실을 다시 계산하면 이제 더 낮을 것입니다.
코드를 작성하기 전에 한 가지 중요한 관찰이 있습니다. DQN을 업데이트하기 위해 DQN... 자체에 대해 두 가지 정방향 전달을 수행합니다. 이것은 종종 불안정한 학습으로 이어집니다. 이를 완화하기 위해 다음 상태 $Q$ 예측에 대해 동일한 DQN을 사용하지 않습니다. 우리는 코드에서 target_model 이라고 하는 이전 버전을 사용합니다(주 DQN인 model 대신). 덕분에 안정적인 목표가 생겼습니다. 1000단계마다 model 가중치를 설정하여 target_model 을 업데이트합니다. 그러나 model 은 모든 단계를 업데이트합니다.
DQN 모델을 생성하는 코드를 살펴보겠습니다.
def create_model(env): n_actions = env.action_space.n obs_shape = env.observation_space.shape observations_input = keras.layers.Input(obs_shape, name='observations_input') action_mask = keras.layers.Input((n_actions,), name='action_mask') hidden = keras.layers.Dense(32, activation='relu')(observations_input) hidden_2 = keras.layers.Dense(32, activation='relu')(hidden) output = keras.layers.Dense(n_actions)(hidden_2) filtered_output = keras.layers.multiply([output, action_mask]) model = keras.models.Model([observations_input, action_mask], filtered_output) optimizer = keras.optimizers.Adam(lr=LEARNING_RATE, clipnorm=1.0) model.compile(optimizer, loss='mean_squared_error') return model첫째, 함수는 주어진 OpenAI 체육관 환경에서 행동 및 관찰 공간의 차원을 취합니다. 예를 들어, 우리 네트워크가 얼마나 많은 출력을 가질지 알아야 합니다. 작업 수와 같아야 합니다. 작업은 하나의 핫 인코딩입니다.
def one_hot_encode(n, action): one_hot = np.zeros(n) one_hot[int(action)] = 1 return one_hot따라서 (예) 왼쪽은 [1, 0]이 되고 오른쪽은 [0, 1]이 됩니다.

관찰이 입력으로 전달되는 것을 볼 수 있습니다. 또한 action_mask 를 두 번째 입력으로 전달합니다. 왜요? $Q(s,a)$를 계산할 때 모든 행동이 아니라 하나의 주어진 행동에 대해서만 $Q$-value를 알아야 합니다. action_mask 는 DQN 출력에 전달하려는 작업에 대해 1을 포함합니다. action_mask 가 어떤 작업에 대해 0이면 해당 $Q$-value는 출력에서 0이 됩니다. filtered_output 레이어가 그 일을 하고 있습니다. 모든 $Q$ 값(최대 계산의 경우)을 원하면 모든 값을 전달할 수 있습니다.
코드는 keras.layers.Dense 를 사용하여 완전 연결 계층을 정의합니다. Keras는 TensorFlow를 기반으로 하는 더 높은 수준의 추상화를 위한 Python 라이브러리입니다. 내부적으로 Keras는 편향, 적절한 가중치 초기화 및 기타 저수준 항목을 사용하여 TensorFlow 그래프를 생성합니다. 우리는 원시 TensorFlow를 사용하여 그래프를 정의할 수 있었지만 한 줄로 표시되지는 않습니다.
따라서 관찰은 ReLU(정류 선형 단위) 활성화와 함께 첫 번째 은닉층으로 전달됩니다. ReLU(x) 는 $\textrm{max}(0, x)$ 함수입니다. 이 레이어는 두 번째 동일한 레이어인 hidden_2 와 완전히 연결되어 있습니다. 출력 레이어는 뉴런의 수를 행동의 수로 줄입니다. 결국에는 출력에 action_mask 를 곱하는 filtered_output 이 있습니다.
$θ$ 가중치를 찾기 위해 평균 제곱 오차 손실이 있는 "Adam"이라는 최적화 프로그램을 사용합니다.
모델이 있으면 이를 사용하여 주어진 상태 관찰에 대한 $Q$ 값을 예측할 수 있습니다.
def predict(env, model, observations): action_mask = np.ones((len(observations), env.action_space.n)) return model.predict(x=[observations, action_mask]) 우리는 모든 작업에 대해 $Q$ 값을 원하므로 action_mask 는 1의 벡터입니다.
실제 훈련을 하기 위해 우리는 fit_batch() 를 사용할 것입니다:
def fit_batch(env, model, target_model, batch): observations, actions, rewards, next_observations, dones = batch # Predict the Q values of the next states. Passing ones as the action mask. next_q_values = predict(env, target_model, next_observations) # The Q values of terminal states is 0 by definition. next_q_values[dones] = 0.0 # The Q values of each start state is the reward + gamma * the max next state Q value q_values = rewards + DISCOUNT_FACTOR_GAMMA * np.max(next_q_values, axis=1) one_hot_actions = np.array([one_hot_encode(env.action_space.n, action) for action in actions]) history = model.fit( x=[observations, one_hot_actions], y=one_hot_actions * q_values[:, None], batch_size=BATCH_SIZE, verbose=0, ) return history.history['loss'][0] 배치에 BATCH_SIZE 경험이 포함되어 있습니다. next_q_values 는 $Q(s, a)$입니다. q_values 는 벨만 방정식에서 $r + γ \space \textrm{max}_{a'}Q(s', a')$입니다. 우리가 취한 작업은 하나의 핫 인코딩되고 model.fit() 을 호출할 때 입력에 action_mask 로 전달됩니다. $y$는 지도 학습에서 "목표"에 대한 일반적인 문자입니다. 여기에서 q_values 를 전달합니다. 나는 q_values[:. None] q_values[:. None] one_hot_actions 배열의 차원과 일치해야 하므로 배열 차원을 늘립니다. 더 자세히 알고 싶다면 이것을 슬라이스 표기법이라고 합니다.
TensorBoard 로그 파일에 저장하고 나중에 시각화하기 위해 손실을 반환합니다. 우리가 모니터링할 다른 사항이 많이 있습니다. 초당 얼마나 많은 단계를 수행하는지, 총 RAM 사용량, 평균 에피소드 반환률 등입니다. 이러한 플롯을 봅시다.
달리기
TensorBoard 로그 파일을 시각화하려면 먼저 하나가 있어야 합니다. 이제 교육을 실행해 보겠습니다.
python run.py이것은 먼저 우리 모델의 요약을 인쇄할 것입니다. 그런 다음 현재 날짜로 로그 디렉터리를 만들고 훈련을 시작합니다. 2000단계마다 다음과 유사한 로그라인이 인쇄됩니다.
episode 10 steps 200/2001 loss 0.3346639 return -200.0 in 1.02s 195.7 steps/s 9.0/15.6 GB RAM20,000번마다 10,000번 단계에서 모델을 평가합니다.
Evaluation 100%|█████████████████████████████████████████████████████████████████████████████████| 10000/10000 [00:07<00:00, 1254.40it/s] episode 677 step 120000 episode_return_avg -136.750 avg_max_q_value -56.004 677회, 12만 걸음 후 평균 회차수는 -200회에서 -136.75회까지! 확실히 배우는 중입니다. avg_max_q_value 가 무엇인지 독자에게 좋은 연습으로 남겨 둡니다. 그러나 훈련 중에 보면 매우 유용한 통계입니다.
200,000보를 걸으면 훈련이 완료됩니다. 제 4코어 CPU에서는 약 20분이 걸립니다. date-log 디렉토리 내부를 볼 수 있습니다(예: 06-07-18-39-log ). .h5 확장자를 가진 4개의 모델 파일이 있습니다. 이것은 TensorFlow 그래프 가중치의 스냅샷입니다. 나중에 우리가 배운 정책을 살펴보기 위해 50,000단계마다 저장합니다. 그것을 보려면:
python run.py --model 06-08-18-42-log/06-08-18-42-200000.h5 --view 다른 가능한 플래그를 보려면: python run.py --help .
이제 자동차는 원하는 목표에 훨씬 더 잘 도달하고 있습니다. date-log 디렉토리에는 events.out.* 파일도 있습니다. 이것은 TensorBoard가 데이터를 저장하는 파일입니다. loggers.py에 정의된 가장 간단한 TensorBoardLogger 를 사용하여 작성합니다 loggers.py. 이벤트 파일을 보려면 로컬 TensorBoard 서버를 실행해야 합니다.
tensorboard --logdir=. --logdir 은 날짜-로그 디렉토리가 있는 디렉토리를 가리킵니다. 이 경우에는 현재 디렉토리이므로 . . TensorBoard는 수신 중인 URL을 인쇄합니다. http://127.0.0.1:6006을 열면 다음과 유사한 8개의 플롯이 표시됩니다.
마무리
train() 은 모든 훈련을 수행합니다. 먼저 모델을 만들고 버퍼를 재생합니다. 그런 다음 see.py 의 루프와 매우 유사한 루프에서 환경과 상호 작용하고 버퍼에 경험을 저장합니다. 중요한 것은 우리가 엡실론-탐욕적인 정책을 따르는 것입니다. 우리는 항상 $Q$-function에 따라 최선의 행동을 선택할 수 있습니다. 그러나 탐색을 방해하여 전체 성능에 해를 끼칩니다. 따라서 엡실론 확률로 탐색을 시행하기 위해 무작위 작업을 수행합니다.
def greedy_action(env, model, observation): next_q_values = predict(env, model, observations=[observation]) return np.argmax(next_q_values) def epsilon_greedy_action(env, model, observation, epsilon): if random.random() < epsilon: action = env.action_space.sample() else: action = greedy_action(env, model, observation) return action 엡실론은 1%로 설정되었습니다. 2000번의 경험이 끝나면 리플레이가 채워져 훈련을 시작할 수 있습니다. 재생 버퍼에서 샘플링된 임의의 경험 배치로 fit_batch() 를 호출하여 수행합니다.
batch = replay.sample(BATCH_SIZE) loss = fit_batch(env, model, target_model, batch) 20,000단계마다 결과를 평가하고 기록합니다(평가는 epsilon = 0 , 완전히 탐욕스러운 정책):
if step >= TRAIN_START and step % EVAL_EVERY == 0: episode_return_avg = evaluate(env, model) q_values = predict(env, model, q_validation_observations) max_q_values = np.max(q_values, axis=1) avg_max_q_value = np.mean(max_q_values) print( "episode {} " "step {} " "episode_return_avg {:.3f} " "avg_max_q_value {:.3f}".format( episode, step, episode_return_avg, avg_max_q_value, )) logger.log_scalar('episode_return_avg', episode_return_avg, step) logger.log_scalar('avg_max_q_value', avg_max_q_value, step) 전체 코드는 약 300 run.py 에는 가장 중요한 것 중 약 250줄이 포함되어 있습니다.
많은 하이퍼파라미터가 있음을 알 수 있습니다.
DISCOUNT_FACTOR_GAMMA = 0.99 LEARNING_RATE = 0.001 BATCH_SIZE = 64 TARGET_UPDATE_EVERY = 1000 TRAIN_START = 2000 REPLAY_BUFFER_SIZE = 50000 MAX_STEPS = 200000 LOG_EVERY = 2000 SNAPSHOT_EVERY = 50000 EVAL_EVERY = 20000 EVAL_STEPS = 10000 EVAL_EPSILON = 0 TRAIN_EPSILON = 0.01 Q_VALIDATION_SIZE = 10000그리고 그것이 전부는 아닙니다. 네트워크 아키텍처도 있습니다. 32개의 뉴런이 있는 두 개의 은닉 레이어, ReLU 활성화 및 Adam 최적화 프로그램을 사용했지만 다른 옵션도 많이 있습니다. 작은 변화라도 훈련에 큰 영향을 미칠 수 있습니다. 하이퍼파라미터를 조정하는 데 많은 시간이 소요될 수 있습니다. 최근 OpenAI 대회에서 2등 참가자는 초매개변수 조정 후 Rainbow 점수를 거의 두 배로 늘릴 수 있음을 발견했습니다. 당연히 과적합이 쉽다는 것을 기억해야 합니다. 현재 강화 알고리즘은 유사한 환경으로 지식을 이전하는 데 어려움을 겪고 있습니다. 우리의 마운틴 카는 현재 모든 유형의 산에 일반화되지 않습니다. 실제로 OpenAI 체육관 환경을 수정하고 에이전트가 일반화할 수 있는 정도를 확인할 수 있습니다.
또 다른 연습은 나보다 더 나은 하이퍼파라미터 집합을 찾는 것입니다. 확실히 가능합니다. 그러나 한 번의 교육 실행으로는 변경 사항이 개선되었는지 여부를 판단하기에 충분하지 않습니다. 일반적으로 훈련 실행 간에는 큰 차이가 있습니다. 편차가 큽니다. 더 나은 것을 결정하려면 여러 번 실행해야 합니다. 재현성과 같은 중요한 주제에 대해 더 자세히 알고 싶다면 Deep Reinforcement Learning that Matters를 읽어보시기 바랍니다. 수동으로 조정하는 대신 이 프로세스를 어느 정도 자동화할 수 있습니다. 문제에 더 많은 컴퓨팅 성능을 사용할 의향이 있는 경우입니다. 간단한 접근 방식은 일부 하이퍼파라미터에 대해 유망한 값 범위를 준비하고 병렬로 실행되는 훈련과 함께 그리드 검색(그 조합 확인)을 실행하는 것입니다. 병렬화 자체는 고성능을 위해 중요하기 때문에 그 자체로 큰 주제입니다.
Deep $Q$-learning은 가치 반복을 사용하는 강화 학습 알고리즘의 큰 제품군을 나타냅니다. 우리는 $Q$-함수를 근사화하려고 시도했고 대부분의 시간에 탐욕적인 방식으로 사용했습니다. 정책 반복을 사용하는 또 다른 제품군이 있습니다. 그들은 $Q$ 함수를 근사하는 데 초점을 맞추지 않고 최적의 정책 $π^*$을 직접 찾는 데 중점을 둡니다. 강화 학습 알고리즘 환경에서 가치 반복이 어디에 적합한지 확인하려면:
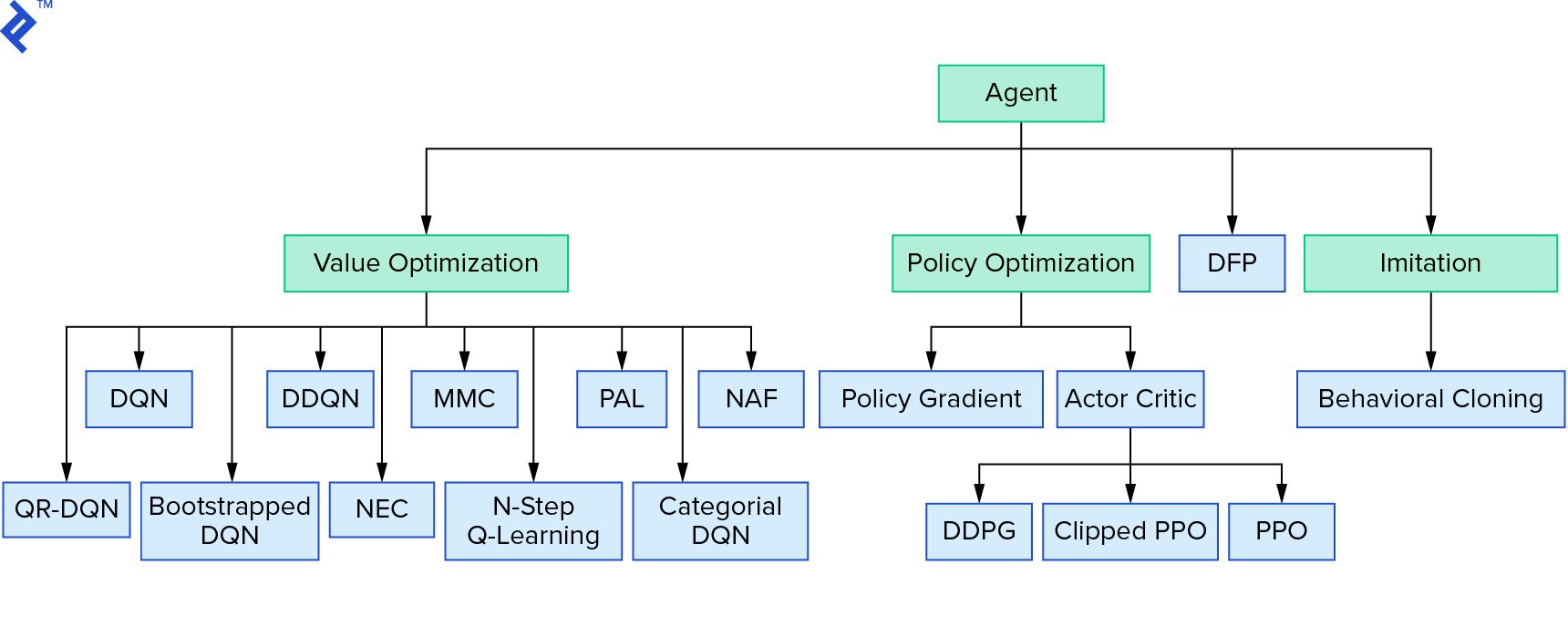
심층 강화 학습이 부서지기 쉬운 것처럼 보일 수 있습니다. 당신이 옳을 것입니다. 많은 문제가 있습니다. Deep Reinforcement Learning은 아직 작동하지 않음 및 Reinforcement Learning은 작동하지 않았으며 'deep'는 약간만 도움이 되었습니다.
이것으로 튜토리얼을 마칩니다. 학습 목적으로 자체 기본 DQN을 구현했습니다. 매우 유사한 코드를 사용하여 일부 Atari 게임에서 우수한 성능을 얻을 수 있습니다. 실제 응용 프로그램에서는 테스트된 고성능 구현(예: OpenAI 기준선)을 사용하는 경우가 많습니다. 더 복잡한 환경에서 심층 강화 학습을 적용하려고 할 때 직면할 수 있는 문제를 확인하려면 Our NIPS 2017: Learning to Run 접근 방식을 읽을 수 있습니다. 재미있는 대회 환경에서 더 자세히 알고 싶다면 NIPS 2018 대회 또는 crowdai.org를 살펴보십시오.
기계 학습 전문가가 되는 길에 지도 학습에 대한 지식을 심화하고 싶다면 기계 학습 비디오 분석: 물고기 식별에서 물고기 식별 에 대한 재미있는 실험을 확인하십시오.