
เจาะลึกการเรียนรู้การเสริมกำลัง
เผยแพร่แล้ว: 2022-03-11มาเจาะลึกการเรียนรู้การเสริมกำลังกัน ในบทความนี้ เราจะแก้ไขปัญหาที่เป็นรูปธรรมกับห้องสมุดสมัยใหม่ เช่น TensorFlow, TensorBoard, Keras และยิม OpenAI คุณจะเห็นวิธีการใช้หนึ่งในอัลกอริธึมพื้นฐานที่เรียกว่า $Q$-learning เชิงลึก เพื่อเรียนรู้การทำงานภายในของมัน ในส่วนของฮาร์ดแวร์ รหัสทั้งหมดจะทำงานบนพีซีทั่วไปและใช้แกนประมวลผลของ CPU ที่พบทั้งหมด (ซึ่ง TensorFlow จัดการให้)
ปัญหาที่เรียกว่า Mountain Car: รถอยู่บนเส้นทางหนึ่งมิติซึ่งอยู่ระหว่างภูเขาสองลูก เป้าหมายคือการขับขึ้นภูเขาทางด้านขวา (ถึงธง) อย่างไรก็ตามเครื่องยนต์ของรถไม่แข็งแรงพอที่จะปีนขึ้นไปบนภูเขาได้ในครั้งเดียว ดังนั้น วิธีเดียวที่จะประสบความสำเร็จคือการขับเคลื่อนไปมาเพื่อสร้างโมเมนตัม
ปัญหานี้ได้รับเลือกเนื่องจากง่ายพอที่จะค้นหาวิธีแก้ปัญหาด้วยการเรียนรู้แบบเสริมกำลังภายในไม่กี่นาทีบนคอร์ของ CPU ตัวเดียว อย่างไรก็ตาม มันซับซ้อนพอที่จะเป็นตัวแทนที่ดีได้
อันดับแรก ฉันจะให้สรุปสั้น ๆ ว่าการเรียนรู้แบบเสริมกำลังทำอะไรโดยทั่วไป จากนั้น เราจะครอบคลุมคำศัพท์พื้นฐานและแสดงปัญหาของเรากับพวกเขา หลังจากนั้น ฉันจะอธิบายอัลกอริทึมการเรียนรู้ $Q$ เชิงลึก และเราจะดำเนินการเพื่อแก้ปัญหา
พื้นฐานการเรียนรู้การเสริมแรง
การเรียนรู้การเสริมกำลังด้วยคำที่ง่ายที่สุดคือการเรียนรู้จากการลองผิดลองถูก ตัวละครหลักเรียกว่า "เอเย่นต์" ซึ่งคงจะเป็นรถในปัญหาของเรา ตัวแทนดำเนินการในสภาพแวดล้อมและได้รับการสังเกตใหม่และรางวัลสำหรับการกระทำนั้น การกระทำที่นำไปสู่รางวัลที่ใหญ่กว่านั้นได้รับการเสริมกำลัง ดังนั้นชื่อ เช่นเดียวกับเรื่องอื่นๆ ในสาขาวิทยาการคอมพิวเตอร์ เรื่องนี้ได้รับแรงบันดาลใจจากการสังเกตสิ่งมีชีวิตด้วย
การโต้ตอบของตัวแทนกับสภาพแวดล้อมถูกสรุปไว้ในกราฟต่อไปนี้:
ตัวแทนได้รับการสังเกตและรางวัลสำหรับการกระทำที่ทำ จากนั้นจึงดำเนินการอื่นและใช้ขั้นตอนที่สอง สภาพแวดล้อมตอนนี้ส่งคืนการสังเกตและรางวัลที่แตกต่างกันเล็กน้อย (อาจ) สิ่งนี้จะดำเนินต่อไปจนกว่าจะถึงสถานะเทอร์มินัล โดยส่งสัญญาณว่า "เสร็จสิ้น" ไปยังตัวแทน ลำดับการ สังเกตทั้งหมด > การกระทำ > next_observations > รางวัล เรียกว่าตอน (หรือวิถี)
กลับไปที่ Mountain Car ของเรา: รถของเราเป็นตัวแทน สภาพแวดล้อมเป็นโลกกล่องดำของภูเขามิติเดียว การกระทำของรถลดลงเหลือเพียงตัวเลขเดียว: หากเป็นบวก เครื่องยนต์จะดันรถไปทางขวา ถ้าติดลบก็จะดันรถไปทางซ้าย ตัวแทนรับรู้สภาพแวดล้อมผ่านการสังเกต: ตำแหน่ง X และความเร็วของรถ หากเราต้องการให้รถของเราวิ่งบนยอดเขา เราจะกำหนดรางวัลด้วยวิธีที่สะดวก: ตัวแทนจะได้รับ -1 เป็นรางวัลสำหรับทุกๆ ย่างก้าวที่ยังไม่ถึงเป้าหมาย เมื่อถึงเป้าหมายตอนจะจบลง ดังนั้น อันที่จริง เอเยนต์ถูกลงโทษเพราะไม่อยู่ในตำแหน่งที่เราต้องการให้เป็น ยิ่งเขาไปถึงเร็วเท่าไหร่ก็ยิ่งดีสำหรับเขาเท่านั้น เป้าหมายของตัวแทนคือการเพิ่มรางวัลรวมสูงสุด ซึ่งเป็นผลรวมของรางวัลจากตอนหนึ่ง ดังนั้นหากถึงจุดที่ต้องการหลังจากนั้น เช่น 110 ก้าว ได้ผลตอบแทนรวม -110 ซึ่งจะเป็นผลงานที่ยอดเยี่ยมสำหรับ Mountain Car เพราะหากไปไม่ถึงเป้าหมายจะถูกลงโทษ 200 ก้าว (ดังนั้น ผลตอบแทน -200)
นี่คือการกำหนดปัญหาทั้งหมด ตอนนี้ เราสามารถมอบให้กับอัลกอริธึม ซึ่งมีประสิทธิภาพเพียงพอที่จะแก้ปัญหาดังกล่าวได้ในเวลาไม่กี่นาที (หากปรับมาอย่างดี) เป็นที่น่าสังเกตว่าเราไม่ได้บอกตัวแทนว่าจะบรรลุเป้าหมายได้อย่างไร เราไม่ได้ให้คำแนะนำใดๆ (ฮิวริสติก) ตัวแทนจะหาวิธี (นโยบาย) ที่จะชนะด้วยตัวของมันเอง
การสร้างสิ่งแวดล้อม
ขั้นแรก ให้คัดลอกโค้ดบทช่วยสอนทั้งหมดลงในดิสก์ของคุณ:
git clone https://github.com/AdamStelmaszczyk/rl-tutorial cd rl-tutorialตอนนี้ เราต้องติดตั้งแพ็คเกจ Python ที่เราจะใช้ เพื่อไม่ให้ติดตั้งในพื้นที่ผู้ใช้ของคุณ (และมีความเสี่ยงในการชนกัน) เราจะทำให้มันสะอาดและติดตั้งในสภาพแวดล้อม conda หากคุณไม่ได้ติดตั้ง conda โปรดปฏิบัติตาม https://conda.io/docs/user-guide/install/index.html
เพื่อสร้างสภาพแวดล้อม conda ของเรา:
conda create -n tutorial python=3.6.5 -yวิธีเปิดใช้งาน:
source activate tutorial คุณควรเห็น (tutorial) ใกล้พรอมต์ของคุณในเชลล์ หมายความว่าสภาพแวดล้อม conda ที่มีชื่อ "บทช่วยสอน" เปิดใช้งานอยู่ จากนี้ไป คำสั่งทั้งหมดควรถูกดำเนินการภายในสภาพแวดล้อม conda นั้น
ตอนนี้ เราสามารถติดตั้งการพึ่งพาทั้งหมดในสภาพแวดล้อม conda ที่ปิดสนิทของเรา:
pip install -r requirements.txtเราทำการติดตั้งเสร็จแล้ว เรามารันโค้ดกัน เราไม่จำเป็นต้องปรับใช้สภาพแวดล้อมของ Mountain Car ด้วยตนเอง ห้องสมุด OpenAI Gym จัดให้มีการใช้งานนั้น มาดูตัวแทนสุ่ม (ตัวแทนที่ดำเนินการแบบสุ่ม) ในสภาพแวดล้อมของเรา:
import gym env = gym.make('MountainCar-v0') done = True episode = 0 episode_return = 0.0 for episode in range(5): for step in range(200): if done: if episode > 0: print("Episode return: ", episode_return) obs = env.reset() episode += 1 episode_return = 0.0 env.render() else: obs = next_obs action = env.action_space.sample() next_obs, reward, done, _ = env.step(action) episode_return += reward env.render() นี่คือไฟล์ see.py ; เพื่อเรียกใช้ดำเนินการ:
python see.pyคุณควรเห็นรถวิ่งไปมาแบบสุ่ม แต่ละตอนจะประกอบด้วย 200 ขั้นตอน; ผลตอบแทนรวมจะเป็น -200
ตอนนี้เราต้องแทนที่การกระทำแบบสุ่มด้วยสิ่งที่ดีกว่า มีอัลกอริธึมมากมายที่เราสามารถใช้ได้ สำหรับบทช่วยสอนเบื้องต้น ฉันคิดว่าแนวทางที่เรียกว่า $Q$-learning เชิงลึกนั้นเหมาะสม การทำความเข้าใจวิธีการนั้นเป็นรากฐานที่มั่นคงสำหรับการเรียนรู้แนวทางอื่นๆ
การเรียนรู้ $Q$ เชิงลึก
อัลกอริทึมที่เราจะใช้ได้รับการอธิบายครั้งแรกในปี 2013 โดย Mnih et al ในการเล่น Atari ด้วยการเรียนรู้การเสริมแรงอย่างลึกและขัดเกลาในอีกสองปีต่อมาในการควบคุมระดับมนุษย์ผ่านการเรียนรู้การเสริมแรงอย่างลึกซึ้ง ผลงานอื่นๆ มากมายสร้างขึ้นจากผลลัพธ์เหล่านั้น รวมถึงอัลกอริธึมล้ำสมัยในปัจจุบัน Rainbow (2017):
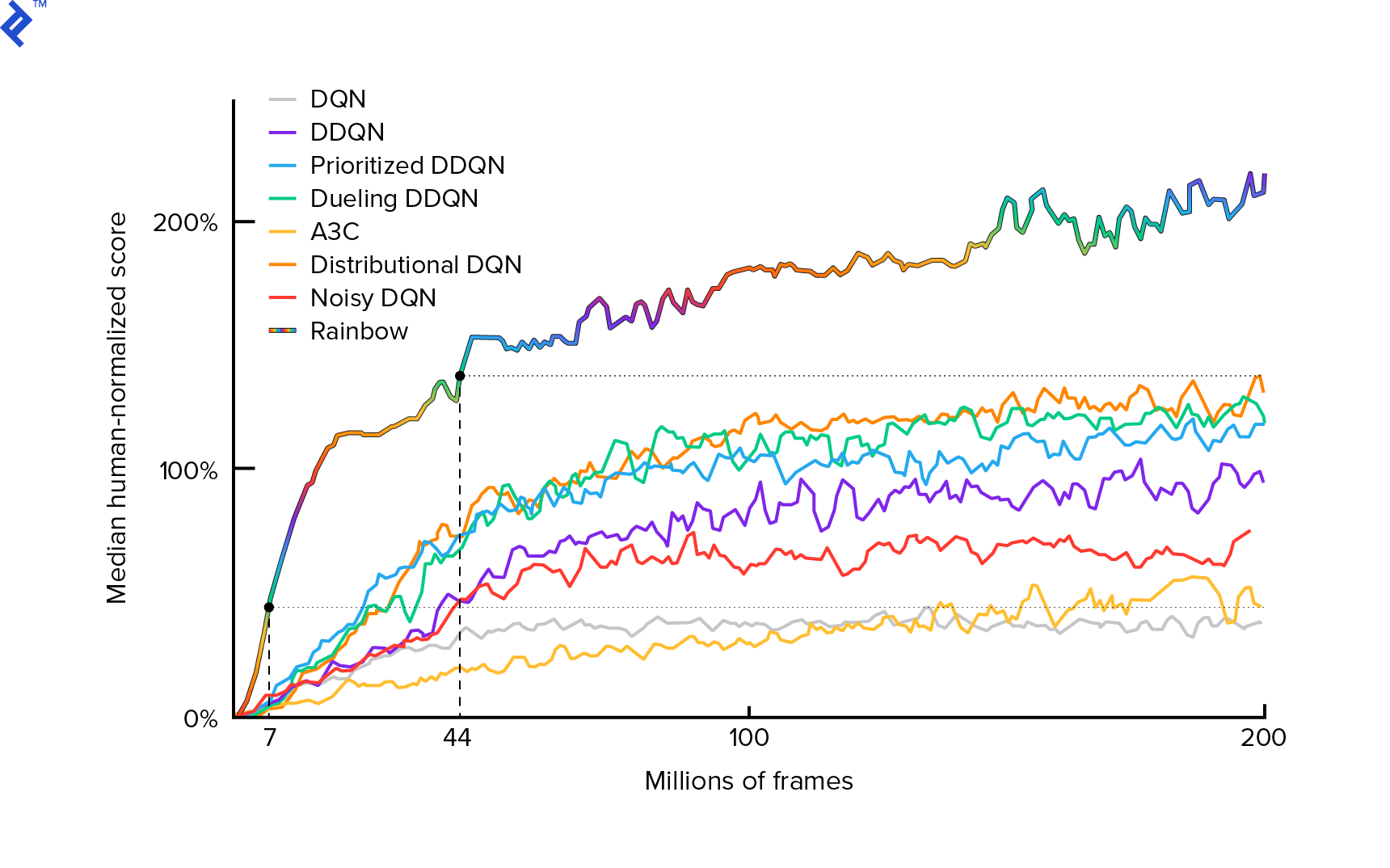
Rainbow บรรลุประสิทธิภาพเหนือมนุษย์ในเกม Atari 2600 หลายเกม เราจะเน้นที่เวอร์ชัน DQN พื้นฐาน โดยมีการปรับปรุงเพิ่มเติมให้น้อยที่สุดเท่าที่จะเป็นไปได้ เพื่อให้บทช่วยสอนนี้มีขนาดที่เหมาะสม
นโยบาย ซึ่งโดยทั่วไปจะระบุ $π(s)$ เป็นฟังก์ชันที่คืนค่าความน่าจะเป็นของการดำเนินการแต่ละรายการในสถานะที่กำหนด $s$ ตัวอย่างเช่น นโยบายของ Mountain Car แบบสุ่มส่งคืนสำหรับรัฐใดๆ: ซ้าย 50% ขวา 50% ระหว่างการเล่นเกม เราสุ่มตัวอย่างจากนโยบายนั้น (การแจกจ่าย) เพื่อรับการดำเนินการจริง
$Q$-learning (Q is for Quality) หมายถึงฟังก์ชัน action-value ที่ระบุ $Q_π(s, a)$ จะส่งคืนผลตอบแทนทั้งหมดจากรัฐที่กำหนด $s$ โดยเลือกการดำเนินการ $a$ ตามนโยบายที่เป็นรูปธรรม $π$ ผลตอบแทนรวมคือผลรวมของรางวัลทั้งหมดในตอนเดียว (วิถี)
หากเรารู้ฟังก์ชัน $Q$-ที่เหมาะสม ซึ่งแสดงเป็น $Q^*$ เราก็สามารถแก้ปัญหาเกมได้อย่างง่ายดาย เราจะทำตามการกระทำที่มีมูลค่าสูงสุด $Q^*$ นั่นคือผลตอบแทนที่คาดหวังสูงสุด สิ่งนี้รับประกันได้ว่าเราจะได้ผลตอบแทนสูงสุด
อย่างไรก็ตาม เรามักจะไม่รู้ $Q^*$ ในกรณีเช่นนี้ เราสามารถประมาณ—หรือ “เรียนรู้”—จากการมีปฏิสัมพันธ์กับสิ่งแวดล้อม นี่คือส่วน "$Q$-การเรียนรู้" ในชื่อ นอกจากนี้ยังมีคำว่า "ลึก" อยู่ด้วยเพราะในการประมาณฟังก์ชันนั้น เราจะใช้โครงข่ายประสาทเทียมระดับลึก ซึ่งเป็นตัวประมาณฟังก์ชันสากล Deep Neural Networks ซึ่งมีค่าประมาณ $Q$-values มีชื่อว่า Deep Q-Networks (DQN) ในสภาพแวดล้อมที่เรียบง่าย (ด้วยจำนวนสถานะที่เหมาะสมในหน่วยความจำ) เราสามารถใช้ตารางแทนโครงข่ายประสาทเพื่อเป็นตัวแทนของฟังก์ชัน $Q$ ซึ่งในกรณีนี้จะมีชื่อว่า "การเรียนรู้แบบตาราง $Q$"
ดังนั้นเป้าหมายของเราในตอนนี้คือการประมาณฟังก์ชัน $Q^*$ เราจะใช้สมการเบลล์แมน:
\[Q(s, a) = r + γ \space \textrm{max}_{a'} Q(s', a')\]$s'$ คือสถานะหลัง $s$ $γ$ (แกมมา) โดยทั่วไปแล้ว 0.99 เป็นปัจจัยส่วนลด (เป็นพารามิเตอร์ไฮเปอร์) มันทำให้น้ำหนักน้อยลงสำหรับรางวัลในอนาคต (เพราะพวกเขาไม่แน่ใจน้อยกว่ารางวัลทันทีที่มี $Q$ ที่ไม่สมบูรณ์ของเรา) สมการ Bellman เป็นหัวใจสำคัญของการเรียนรู้ $Q$-learning มันบอกว่าค่า $Q$-สำหรับรัฐที่กำหนดและการกระทำนั้นเป็นรางวัลที่ $r$ ได้รับหลังจากดำเนินการ $a$ บวก กับมูลค่า $Q$- สูงสุดสำหรับรัฐที่เราลงจอดใน $s'$ ค่าสูงสุดคือการที่เรากำลังเลือกการดำเนินการ $a'$ ซึ่งนำไปสู่ผลตอบแทนรวมสูงสุดจาก $s'$
ด้วยสมการ Bellman เราสามารถใช้การเรียนรู้ภายใต้การดูแลเพื่อประมาณ $Q^*$ ฟังก์ชัน $Q$-จะถูกแสดง (กำหนดพารามิเตอร์) โดยน้ำหนักโครงข่ายประสาทเทียมที่แสดงเป็น $θ$ (ทีต้า) การนำไปใช้อย่างตรงไปตรงมาจะใช้สถานะและการดำเนินการเป็นอินพุตเครือข่ายและเอาต์พุตค่า Q ความไร้ประสิทธิภาพคือถ้าเราต้องการทราบค่า $Q$-สำหรับการดำเนินการทั้งหมดในสถานะที่กำหนด เราจำเป็นต้องเรียก $Q$ หลายครั้งตามที่มีการกระทำ มีวิธีที่ดีกว่ามาก: ใช้เฉพาะสถานะเป็นค่าอินพุตและเอาต์พุต $Q$-values สำหรับการดำเนินการที่เป็นไปได้ทั้งหมด ด้วยเหตุนี้ เราจึงสามารถได้รับค่า $Q$-สำหรับการดำเนินการทั้งหมดในการส่งต่อเพียงครั้งเดียว
เราเริ่มฝึกเครือข่าย $Q$ ด้วยน้ำหนักแบบสุ่ม จากสิ่งแวดล้อม เราได้รับการเปลี่ยนแปลงมากมาย (หรือ “ประสบการณ์”) สิ่งเหล่านี้คือทูเพิลของ (สถานะ การดำเนินการ สถานะถัดไป รางวัล) หรือโดยย่อ ($s$, $a$, $s'$, $r$) เราจัดเก็บพวกมันไว้หลายพันตัวในบัฟเฟอร์แบบวงแหวนที่เรียกว่า “experience replay” จากนั้น เราสุ่มตัวอย่างประสบการณ์จากบัฟเฟอร์นั้นด้วยความปรารถนาที่สมการของเบลล์แมนจะเก็บไว้ให้พวกเขา เราอาจข้ามบัฟเฟอร์และใช้ประสบการณ์ทีละอย่าง (ซึ่งเรียกว่า "ออนไลน์" หรือ "ตามนโยบาย"); ปัญหาคือประสบการณ์ที่ตามมามีความสัมพันธ์ซึ่งกันและกันอย่างมาก และ DQN ฝึกฝนได้ไม่ดีเมื่อสิ่งนี้เกิดขึ้น นั่นเป็นเหตุผลที่แนะนำการเล่นซ้ำของประสบการณ์ (แนวทาง "ออฟไลน์" "นอกนโยบาย") เพื่อแยกแยะความสัมพันธ์ของข้อมูลนี้ โค้ดของการใช้ริงบัฟเฟอร์ที่ง่ายที่สุดมีอยู่ในไฟล์ replay_buffer.py เราขอแนะนำให้คุณอ่าน
ในตอนเริ่มต้น เนื่องจากน้ำหนักโครงข่ายประสาทเทียมของเราเป็นแบบสุ่ม ค่าด้านซ้ายมือของสมการเบลล์แมนจะอยู่ห่างจากด้านขวามือมาก ผลต่างกำลังสองจะเป็นฟังก์ชันการสูญเสียของเรา เราจะลดฟังก์ชันการสูญเสียโดยการเปลี่ยนน้ำหนักโครงข่ายประสาท $θ$ ลองเขียนฟังก์ชันการสูญเสียของเรา:
\[L(θ) = [Q(s, a) - r - γ \space \textrm{max}_{a'}Q(s', a')]^2\]เป็นสมการของเบลล์แมนที่เขียนใหม่ สมมติว่าเราสุ่มตัวอย่างประสบการณ์ ($s$, left, $s'$, -1) จากการเล่นซ้ำของประสบการณ์ Mountain Car เราทำการส่งต่อผ่านเครือข่าย $Q$ ของเราโดยมีสถานะ $s$ และสำหรับการดำเนินการที่เหลือมันให้ -120 แก่เรา เป็นต้น ดังนั้น $Q(s, \textrm{left}) = -120$ จากนั้นเราป้อน $s'$ ไปยังเครือข่าย ซึ่งจะให้ เช่น -130 สำหรับด้านซ้าย และ -122 สำหรับด้านขวา ชัดเจนว่าการกระทำที่ดีที่สุดสำหรับ $s'$ นั้นถูกต้อง ดังนั้น $\textrm{max}_{a'}Q(s', a') = -122$ เรารู้ $r$ นี่คือรางวัลที่แท้จริง ซึ่งก็คือ -1 ดังนั้นการคาดการณ์เครือข่าย $Q$-ของเราจึงผิดเล็กน้อย เนื่องจาก $L(θ) = [-120 - 1 + 0.99 ⋅ 122]^2 = (-0.22^2) = 0.0484$ ดังนั้นเราจึงส่งต่อข้อผิดพลาดและแก้ไขข้อผิดพลาด $θ$ เล็กน้อย ถ้าเราจะคำนวณการสูญเสียอีกครั้งสำหรับประสบการณ์เดิม ตอนนี้ก็จะลดลง
ข้อสังเกตสำคัญอย่างหนึ่งก่อนที่เราจะไปเขียนโค้ด ขอให้สังเกตว่า ในการอัปเดต DQN ของเรา เราจะทำการส่งต่อสองครั้งบน DQN... เอง นี้มักจะนำไปสู่การเรียนรู้ที่ไม่เสถียร เพื่อบรรเทาปัญหานั้น สำหรับการคาดการณ์ $Q$ ของรัฐถัดไป เราไม่ได้ใช้ DQN เดียวกัน เราใช้เวอร์ชันเก่ากว่า ซึ่งในโค้ดนี้เรียกว่า target_model (แทนที่จะเป็น model เป็น DQN หลัก) ด้วยเหตุนี้เราจึงมีเป้าหมายที่มั่นคง เราอัปเดต target_model โดยตั้งค่าให้เป็น model น้ำหนักทุกๆ 1,000 ขั้นตอน แต่ model ปรับปรุงทุกขั้นตอน
มาดูโค้ดที่สร้างโมเดล DQN กัน:
def create_model(env): n_actions = env.action_space.n obs_shape = env.observation_space.shape observations_input = keras.layers.Input(obs_shape, name='observations_input') action_mask = keras.layers.Input((n_actions,), name='action_mask') hidden = keras.layers.Dense(32, activation='relu')(observations_input) hidden_2 = keras.layers.Dense(32, activation='relu')(hidden) output = keras.layers.Dense(n_actions)(hidden_2) filtered_output = keras.layers.multiply([output, action_mask]) model = keras.models.Model([observations_input, action_mask], filtered_output) optimizer = keras.optimizers.Adam(lr=LEARNING_RATE, clipnorm=1.0) model.compile(optimizer, loss='mean_squared_error') return modelอย่างแรก ฟังก์ชันนี้ใช้มิติของการกระทำและพื้นที่สังเกตการณ์จากสภาพแวดล้อม OpenAI Gym ที่กำหนด จำเป็นต้องทราบ เช่น จำนวนเอาต์พุตที่เครือข่ายของเราจะมี ต้องเท่ากับจำนวนการกระทำ การดำเนินการเป็นการเข้ารหัสแบบด่วน:

def one_hot_encode(n, action): one_hot = np.zeros(n) one_hot[int(action)] = 1 return one_hotดังนั้น (เช่น) ซ้ายจะเป็น [1, 0] และทางขวาจะเป็น [0, 1]
เราจะเห็นว่าการสังเกตถูกส่งผ่านเป็นข้อมูลเข้า นอกจากนี้เรายังส่ง action_mask เป็นอินพุตที่สอง ทำไม? เมื่อทำการคำนวณ $Q(s,a)$ เราจำเป็นต้องรู้ค่า $Q$-สำหรับการกระทำที่กำหนดเพียงครั้งเดียว ไม่ใช่ทั้งหมด action_mask มี 1 สำหรับการกระทำที่เราต้องการส่งต่อไปยังเอาต์พุต DQN หาก action_mask มี 0 สำหรับการกระทำบางอย่าง ค่า $Q$- ที่สอดคล้องกันจะเป็นศูนย์ในผลลัพธ์ เลเยอร์ filtered_output กำลังทำเช่นนั้น หากเราต้องการค่า $Q$-values ทั้งหมด (สำหรับการคำนวณสูงสุด) เราก็สามารถส่งผ่านได้ทั้งหมด
รหัสนี้ใช้ keras.layers.Dense เพื่อกำหนดเลเยอร์ที่เชื่อมต่ออย่างสมบูรณ์ Keras เป็นไลบรารี่ Python สำหรับนามธรรมระดับสูงบน TensorFlow ภายใต้ประทุน Keras จะสร้างกราฟ TensorFlow โดยมีอคติ การเริ่มต้นน้ำหนักที่เหมาะสม และสิ่งอื่น ๆ ในระดับต่ำ เราสามารถใช้ TensorFlow ดิบเพื่อกำหนดกราฟได้ แต่จะไม่ใช่เส้นเดียว
ดังนั้นการสังเกตจะถูกส่งไปยังเลเยอร์แรกที่ซ่อนอยู่ด้วยการเปิดใช้งาน ReLU (หน่วยเชิงเส้นที่แก้ไข) ReLU(x) เป็นเพียงฟังก์ชัน $\textrm{max}(0, x)$ เลเยอร์นั้นเชื่อมต่ออย่างสมบูรณ์กับชั้นที่สองที่เหมือนกัน, hidden_2 เลเยอร์เอาต์พุตทำให้จำนวนเซลล์ประสาทลดลงตามจำนวนการกระทำ ในที่สุด เราก็ได้ filtered_output ซึ่งเพิ่งจะคูณผลลัพธ์ด้วย action_mask
ในการค้นหาน้ำหนัก $θ$ เราจะใช้เครื่องมือเพิ่มประสิทธิภาพที่ชื่อ “อดัม” โดยมีการสูญเสียข้อผิดพลาดกำลังสองเฉลี่ย
การมีแบบจำลอง เราสามารถใช้เพื่อทำนายค่า $Q$ สำหรับการสังเกตสถานะที่กำหนด:
def predict(env, model, observations): action_mask = np.ones((len(observations), env.action_space.n)) return model.predict(x=[observations, action_mask]) เราต้องการ $Q$-values สำหรับการกระทำทั้งหมด ดังนั้น action_mask จึงเป็นเวกเตอร์ของการกระทำ
ในการทำแบบฝึกหัด เราจะใช้ fit_batch() :
def fit_batch(env, model, target_model, batch): observations, actions, rewards, next_observations, dones = batch # Predict the Q values of the next states. Passing ones as the action mask. next_q_values = predict(env, target_model, next_observations) # The Q values of terminal states is 0 by definition. next_q_values[dones] = 0.0 # The Q values of each start state is the reward + gamma * the max next state Q value q_values = rewards + DISCOUNT_FACTOR_GAMMA * np.max(next_q_values, axis=1) one_hot_actions = np.array([one_hot_encode(env.action_space.n, action) for action in actions]) history = model.fit( x=[observations, one_hot_actions], y=one_hot_actions * q_values[:, None], batch_size=BATCH_SIZE, verbose=0, ) return history.history['loss'][0] แบทช์มีประสบการณ์ BATCH_SIZE next_q_values คือ $Q(s, a)$ q_values คือ $r + γ \space \textrm{max}_{a'}Q(s', a')$ จากสมการ Bellman การดำเนินการที่เราทำคือการเข้ารหัสแบบด่วนและส่งผ่านเป็น action_mask ไปยังอินพุตเมื่อเรียก model.fit() $y$ เป็นตัวอักษรทั่วไปสำหรับ "เป้าหมาย" ในการเรียนรู้ภายใต้การดูแล ที่นี่เรากำลังส่งผ่าน q_values ฉันทำ q_values[:. None] q_values[:. None] เพื่อเพิ่มมิติอาร์เรย์เนื่องจากต้องสอดคล้องกับมิติข้อมูลของอาร์เรย์ one_hot_actions นี่เรียกว่าสัญกรณ์สไลซ์ หากคุณต้องการอ่านเพิ่มเติมเกี่ยวกับมัน
เราคืนความสูญเสียเพื่อบันทึกไว้ในล็อกไฟล์ TensorBoard และเห็นภาพในภายหลัง มีหลายสิ่งหลายอย่างที่เราจะติดตาม: เราสร้างกี่ก้าวต่อวินาที, การใช้ RAM ทั้งหมด, ค่าเฉลี่ยของตอนกลับมาเป็นเท่าใด ฯลฯ มาดูพล็อตเหล่านั้นกัน
วิ่ง
เพื่อให้เห็นภาพล็อกไฟล์ TensorBoard อันดับแรก เราต้องมีอยู่หนึ่งไฟล์ เรามาเริ่มการฝึกกันเลย:
python run.pyการดำเนินการนี้จะพิมพ์สรุปแบบจำลองของเราก่อน จากนั้นจะสร้างไดเร็กทอรีบันทึกพร้อมวันที่ปัจจุบันและเริ่มการฝึก ทุกๆ 2,000 ขั้นตอน จะมีการพิมพ์บันทึกในลักษณะนี้:
episode 10 steps 200/2001 loss 0.3346639 return -200.0 in 1.02s 195.7 steps/s 9.0/15.6 GB RAMทุกๆ 20,000 เราจะประเมินแบบจำลองของเราใน 10,000 ขั้นตอน:
Evaluation 100%|█████████████████████████████████████████████████████████████████████████████████| 10000/10000 [00:07<00:00, 1254.40it/s] episode 677 step 120000 episode_return_avg -136.750 avg_max_q_value -56.004 หลังจาก 677 ตอนและ 120,000 ก้าว การกลับมาของตอนโดยเฉลี่ยดีขึ้นจาก -200 เป็น -136.75! เป็นการเรียนรู้อย่างแน่นอน อะไร avg_max_q_value ที่ฉันปล่อยให้เป็นแบบฝึกหัดที่ดีสำหรับผู้อ่าน แต่มันเป็นสถิติที่มีประโยชน์มากในการดูระหว่างการฝึก
หลังจาก 200,000 ก้าว การฝึกของเราก็เสร็จสิ้น สำหรับ CPU สี่คอร์ของฉัน ใช้เวลาประมาณ 20 นาที เราสามารถดูไดเร็กทอรี date-log เช่น 06-07-18-39-log จะมีไฟล์โมเดลสี่ไฟล์ที่มีนามสกุล . .h5 นี่คือภาพรวมของน้ำหนักกราฟ TensorFlow เราบันทึกทุกๆ 50,000 ขั้นตอนเพื่อดูนโยบายที่เราได้เรียนรู้ในภายหลัง หากต้องการดู:
python run.py --model 06-08-18-42-log/06-08-18-42-200000.h5 --view หากต้องการดูแฟล็กอื่นที่เป็นไปได้: python run.py --help
ตอนนี้รถทำงานได้ดีขึ้นมากในการบรรลุเป้าหมายที่ต้องการ ในไดเร็กทอรี date-log ยังมีไฟล์ events.out.* นี่คือไฟล์ที่ TensorBoard เก็บข้อมูลไว้ เราเขียนถึงมันโดยใช้ TensorBoardLogger ที่ง่ายที่สุดที่กำหนดไว้ใน loggers.py. ในการดูไฟล์เหตุการณ์ เราจำเป็นต้องเรียกใช้เซิร์ฟเวอร์ TensorBoard ในเครื่อง:
tensorboard --logdir=. --logdir เพียงชี้ไปที่ไดเร็กทอรีซึ่งมีไดเร็กทอรีบันทึกวันที่ ในกรณีของเรา นี่จะเป็นไดเร็กทอรี . ดังนั้น . TensorBoard พิมพ์ URL ที่กำลังฟังอยู่ หากคุณเปิด http://127.0.0.1:6006 ขึ้นมา คุณจะเห็นแปดแปลงที่คล้ายกับเหล่านี้:
ห่อ
train() ทำการฝึกอบรมทั้งหมด ขั้นแรก เราสร้างโมเดลและเล่นซ้ำบัฟเฟอร์ จากนั้นในลูปที่คล้ายกับจาก see.py เราโต้ตอบกับสภาพแวดล้อมและเก็บประสบการณ์ไว้ในบัฟเฟอร์ สิ่งสำคัญคือเราปฏิบัติตามนโยบายที่โลภมาก เราสามารถเลือกการกระทำที่ดีที่สุดได้ตามฟังก์ชัน $Q$-; อย่างไรก็ตาม สิ่งเหล่านี้ไม่สนับสนุนการสำรวจ ซึ่งส่งผลเสียต่อประสิทธิภาพโดยรวม ดังนั้น เพื่อบังคับใช้การสำรวจด้วยความน่าจะเป็นของเอปซิลอน เราจึงสุ่มดำเนินการ:
def greedy_action(env, model, observation): next_q_values = predict(env, model, observations=[observation]) return np.argmax(next_q_values) def epsilon_greedy_action(env, model, observation, epsilon): if random.random() < epsilon: action = env.action_space.sample() else: action = greedy_action(env, model, observation) return action Epsilon ถูกตั้งค่าเป็น 1% หลังจากประสบการณ์ 2000 ครั้ง การเล่นซ้ำจะเต็มพอที่จะเริ่มการฝึก เราทำได้โดยการเรียก fit_batch() ด้วยชุดประสบการณ์แบบสุ่มที่สุ่มตัวอย่างจากบัฟเฟอร์การเล่นซ้ำ:
batch = replay.sample(BATCH_SIZE) loss = fit_batch(env, model, target_model, batch) เราประเมินและบันทึกผลลัพธ์ทุกๆ 20,000 ขั้นตอน (การประเมินใช้ epsilon = 0 นโยบายโลภโดยสิ้นเชิง):
if step >= TRAIN_START and step % EVAL_EVERY == 0: episode_return_avg = evaluate(env, model) q_values = predict(env, model, q_validation_observations) max_q_values = np.max(q_values, axis=1) avg_max_q_value = np.mean(max_q_values) print( "episode {} " "step {} " "episode_return_avg {:.3f} " "avg_max_q_value {:.3f}".format( episode, step, episode_return_avg, avg_max_q_value, )) logger.log_scalar('episode_return_avg', episode_return_avg, step) logger.log_scalar('avg_max_q_value', avg_max_q_value, step) โค้ดทั้งหมดมีความยาวประมาณ 300 บรรทัด และ run.py มีโค้ดที่สำคัญที่สุดประมาณ 250 รายการ
สามารถสังเกตได้ว่ามีไฮเปอร์พารามิเตอร์มากมาย:
DISCOUNT_FACTOR_GAMMA = 0.99 LEARNING_RATE = 0.001 BATCH_SIZE = 64 TARGET_UPDATE_EVERY = 1000 TRAIN_START = 2000 REPLAY_BUFFER_SIZE = 50000 MAX_STEPS = 200000 LOG_EVERY = 2000 SNAPSHOT_EVERY = 50000 EVAL_EVERY = 20000 EVAL_STEPS = 10000 EVAL_EPSILON = 0 TRAIN_EPSILON = 0.01 Q_VALIDATION_SIZE = 10000และนั่นไม่ใช่ทั้งหมด นอกจากนี้ยังมีสถาปัตยกรรมเครือข่าย—เราใช้เลเยอร์ที่ซ่อนอยู่สองชั้นที่มีเซลล์ประสาท 32 เซลล์ การเปิดใช้งาน ReLU และเครื่องมือเพิ่มประสิทธิภาพอดัม แต่มีตัวเลือกอื่นๆ มากมาย แม้การเปลี่ยนแปลงเพียงเล็กน้อยก็ส่งผลกระทบอย่างมากต่อการฝึก ใช้เวลามากในการปรับแต่งไฮเปอร์พารามิเตอร์ ในการแข่งขัน OpenAI เมื่อเร็วๆ นี้ ผู้เข้าแข่งขันอันดับสองพบว่าคะแนนของ Rainbow เพิ่มขึ้นเกือบ สองเท่า หลังจากปรับไฮเปอร์พารามิเตอร์ โดยธรรมชาติแล้ว เราต้องจำไว้ว่ามันง่ายที่จะใส่มากเกินไป ในปัจจุบัน อัลกอริธึมการเสริมกำลังกำลังดิ้นรนกับการถ่ายทอดความรู้ไปยังสภาพแวดล้อมที่คล้ายคลึงกัน รถบนภูเขาของเรายังไม่ครอบคลุมถึงภูเขาทุกประเภทในขณะนี้ คุณสามารถปรับเปลี่ยนสภาพแวดล้อมของ OpenAI Gym และดูว่าตัวแทนสามารถสรุปได้ไกลแค่ไหน
แบบฝึกหัดอื่นคือการหาชุดของไฮเปอร์พารามิเตอร์ที่ดีกว่าของฉัน มันเป็นไปได้อย่างแน่นอน อย่างไรก็ตาม การฝึกวิ่งเพียงครั้งเดียวอาจไม่เพียงพอที่จะตัดสินว่าการเปลี่ยนแปลงของคุณเป็นการปรับปรุงหรือไม่ โดยปกติแล้วจะมีความแตกต่างอย่างมากระหว่างการฝึกซ้อม ความแปรปรวนมีขนาดใหญ่ คุณจะต้องวิ่งหลายครั้งเพื่อพิจารณาว่ามีบางอย่างที่ดีกว่า หากคุณต้องการอ่านเพิ่มเติมเกี่ยวกับหัวข้อสำคัญเช่นความสามารถในการทำซ้ำ เราขอแนะนำให้คุณอ่าน Deep Reinforcement Learning that Matters แทนที่จะปรับด้วยมือ เราสามารถทำให้กระบวนการนี้เป็นแบบอัตโนมัติได้ในระดับหนึ่ง—หากเรายินดีที่จะใช้พลังประมวลผลในการแก้ปัญหามากขึ้น วิธีง่ายๆ คือการเตรียมช่วงของค่าที่เป็นไปได้สำหรับไฮเปอร์พารามิเตอร์บางตัว และดำเนินการค้นหากริด Parallelization เป็นหัวข้อใหญ่ในตัวเองเนื่องจากเป็นสิ่งสำคัญสำหรับประสิทธิภาพสูง
การเรียนรู้แบบเจาะลึก $Q$ แสดงถึงกลุ่มอัลกอริธึมการเรียนรู้แบบเสริมกำลังกลุ่มใหญ่ที่ใช้การวนซ้ำมูลค่า เราพยายามประมาณค่าฟังก์ชัน $Q$- และเราใช้มันด้วยความโลภเกือบตลอดเวลา มีอีกครอบครัวหนึ่งที่ใช้การวนซ้ำนโยบาย พวกเขาไม่ได้มุ่งเน้นที่การประมาณค่าฟังก์ชัน $Q$-แต่อยู่ที่การหานโยบายที่เหมาะสม $π^*$ โดยตรง หากต้องการดูว่าการวนซ้ำค่าเหมาะสมกับภูมิทัศน์ของอัลกอริธึมการเรียนรู้การเสริมแรงอย่างไร:
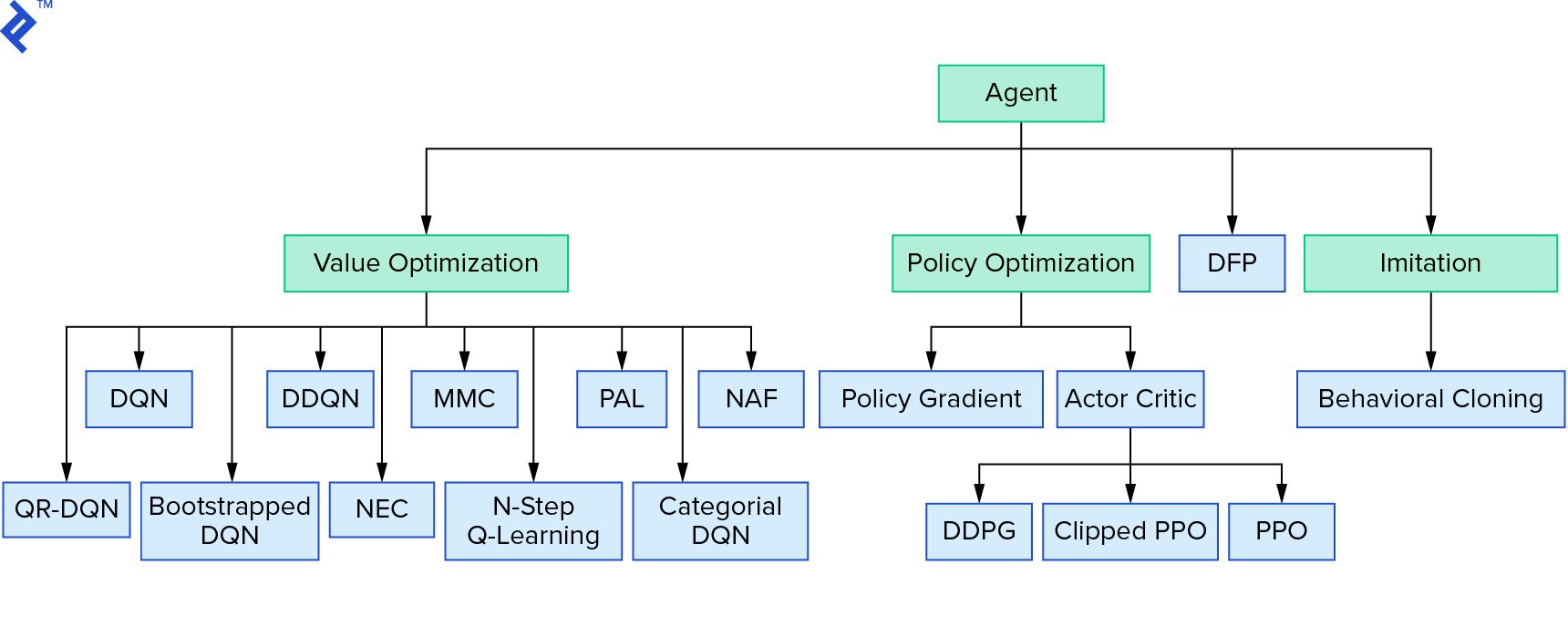
ความคิดของคุณอาจเป็นได้ว่าการเรียนรู้แบบเสริมกำลังลึกนั้นดูเปราะบาง คุณจะพูดถูก มีปัญหามากมาย คุณสามารถอ้างถึง Deep Reinforcement Learning ที่ยังใช้งานไม่ได้ และ Reinforcement Learning ก็ไม่เคยทำงาน และ 'deep' ช่วยได้เพียงเล็กน้อย
บทแนะนำนี้เป็นการสรุป เราใช้ DQN พื้นฐานของเราเองเพื่อจุดประสงค์ในการเรียนรู้ สามารถใช้โค้ดที่คล้ายกันมากเพื่อให้ได้ประสิทธิภาพที่ดีในเกม Atari บางเกม ในการใช้งานจริง มักใช้การทดสอบที่มีประสิทธิภาพสูง เช่น หนึ่งรายการจากพื้นฐาน OpenAI หากคุณต้องการดูว่าความท้าทายใดที่เราเผชิญได้เมื่อพยายามใช้การเรียนรู้แบบเสริมกำลังเชิงลึกในสภาพแวดล้อมที่ซับซ้อนมากขึ้น คุณสามารถอ่านแนวทาง NIPS 2017 ของเรา: เรียนรู้ที่จะเรียกใช้ หากคุณต้องการเรียนรู้เพิ่มเติมในสภาพแวดล้อมการแข่งขันที่สนุกสนาน ให้ดูที่ NIPS 2018 Competitions หรือ crowdai.org
หากคุณกำลังจะเป็นผู้เชี่ยวชาญด้านแมชชีนเลิร์นนิงและต้องการเพิ่มพูนความรู้ของคุณในการเรียนรู้ภายใต้การดูแล ให้ลองดู วิดีโอการวิเคราะห์แมชชีนเลิร์นนิง: การระบุปลา เพื่อการทดลองสนุกๆ ในการระบุปลา