
Pythonでの階層的クラスタリング[概念と分析]
公開: 2020-08-14生データの流れの増加と分析の必要性に伴い、教師なし学習の概念は時間の経過とともに一般的になりました。 これは、ラベル付けされたターゲット値のない入力データで構成されるデータセットから洞察を引き出すために使用されます。 Pythonでの階層的クラスタリングについて説明し、さまざまなデータセットにアルゴリズムを適用する前に、クラスタリングの基本的な考え方を再検討しましょう。
クラスタリングは主に生データの分類を扱います。 これは、互いに最も類似しているさまざまなデータポイントをグループ化することで構成されます。 これらのグループはクラスターと呼ばれ、定義された類似性またはクラスタリングメトリックに基づいて形成されます。
目次
序章
階層的クラスタリングは、ツリーまたは明確に定義された階層の形式でデータを処理します。 このプロセスでは、一度に2つのクラスターを処理します。 アルゴリズムは、計算上の決定のために類似性または距離行列に依存しています。 意味、マージする2つのクラスター、またはクラスターを2つに分割する方法。 これらの2つのオプションを念頭に置いて、2種類の階層的クラスタリングがあります。 初心者でデータサイエンスについて詳しく知りたい場合は、一流大学のデータサイエンスコースをご覧ください。
アルゴリズム全体がそれに基づいて進行するため、アルゴリズムの重要な側面の1つは類似度行列(近接行列とも呼ばれます)です。 この記事でさらに説明する多くの近接方法があります。
タイプ
階層的クラスタリングには2つのタイプがあります。
- 凝集的クラスタリング
- 分割クラスタリング
タイプは、基本的な機能、つまり階層を開発する方法ごとに異なります。 Agglomerativeはボトムアップの階層ジェネレーターですが、divisiveはトップダウンの階層ジェネレーターです。
Agglomerativeは、すべてのポイントを個別のクラスターとして受け取り、各反復で一度に2つずつそれらをマージします。 分割は、データ全体を1つのクラスターと見なすことから始まり、すべてのポイントが個別のクラスターになるまでデータを分割します。
結果は、階層ツリーとして認識できるネストされたクラスターのセットです。 これを表示する最良の方法は、セット構造を樹状図に変換して階層を表示することです。
以下に、樹状図とクラスター表現の簡単な例を示します。
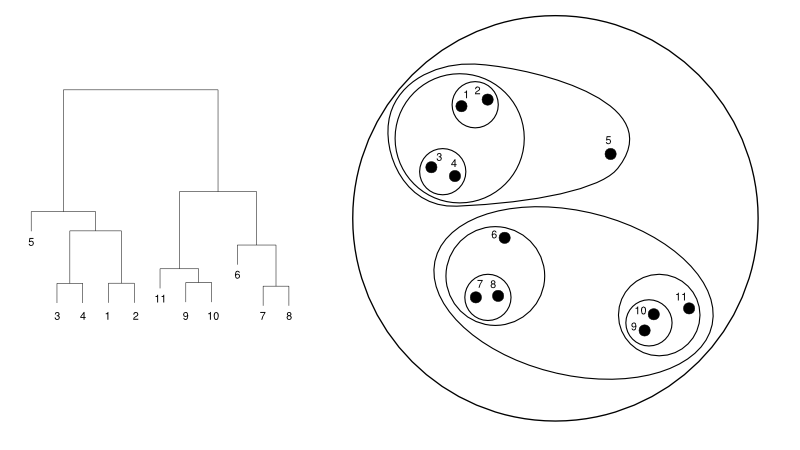
ソース
ここでは、クラスタリングはどちらの方法でも機能しますが、結果はクラスターのコレクションになります。 データポイント1、2、3、4、5、および6は、一度に2つにクラスター化されます。 そして、階層の形成は、同じの樹状図を扱っている左の図で見ることができます。 同じ分析は、クラスターの決定を理解するのに役立ちます。
クラスター数の決定
このアルゴリズムの最も便利な機能の1つは、アルゴリズムが終了したら、必要な数のクラスターを抽出できることです。 これは、K-meansアルゴリズムとはまったく異なります。 K-meansでは、no-of-clustersハイパーパラメーターを渡す必要があります。 これは、アルゴリズムが計算を完了すると、その数のクラスターが存在することを意味します。 ただし、後でさらにクラスターが必要になった場合、それを簡単に調整することはできません。 唯一のオプションは、パラメーターを変更してモデルを再トレーニングすることです。
一方、階層的クラスタリングに関しては、後でクラスターの数を設定できます。 最後に2つのクラスターを取ることができます。 満足できない場合は、最後から2番目またはそれ以上のレベルのステップで形成された5つのクラスターを使用できます。 あなた次第です。 したがって、一度トレーニングすると、クラスターを増やしたり減らしたりするためにモデルを再トレーニングする必要はありません。 樹状図を希望のレベルにカットするだけで実現できます。
概念がわかったので、 Pythonでの階層的クラスタリングの動作について説明しましょう。
実験では、クラスタリングアルゴリズムにsci-kitlearnライブラリを使用します。 また、SciPyのcluster.dendrogramモジュールを使用して、クラスターの数を制限するための「カット」プロセスを視覚化して理解します。
numpyをnpとしてインポートします
X = np.array([[3,5]、
[12,9]、
[13,17]、
[14,14]、
[60,52]、
[55,63]、
[69,59]、])
プロットでは次のようになります。
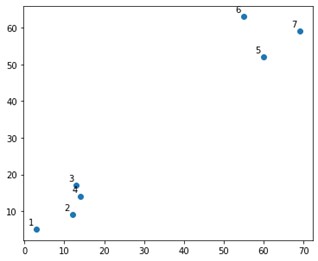
さて、上隅と下隅に2つの決定的なクラスターがあることがわかります。 アルゴリズムがそれを理解できるかどうかを見てみましょう。
sklearn.clusteringモジュールのAgglomerativeClustering関数を使用します。
sklearn.clusterからインポートAgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters = 2、affinity ='euclidean'、linkage ='ward')
cluster.fit_predict(X)
ここでは、ハイパーパラメータではないクラスタを指定します。 ただし、予測クラスを明確にするために渡すだけです。 fit_predict関数を使用して、X上のクラスをトレーニングおよび予測します。
実行が簡単なため、凝集クラスタリングは分割よりも使用されることに注意することが重要です。 近接行列に基づいてクラスターをマージするというアイデアは、何らかのメカニズムを介してクラスターを2つに分割するよりも簡単に思えます。
読む: Scikit-Pythonで学ぶ:機能、前提条件、長所と短所
上記で何が起こったかを明確に理解するには、アルゴリズムに含まれる手順を確認してください。
アルゴリズムの動作
凝集的クラスタリングを実行する手順は次のとおりです。
- 各データポイントをクラスターとして定義する
- 初期近接メトリックを計算します
- メトリックに基づいて「最も近い」または類似した2つのクラスターをマージします
- 近接メトリックを修正し、単一のクラスターが残るまで3番目の手順を繰り返します。
したがって、ここで理解する必要があるのは、さまざまな近接方法の影響だけです。 ご存知のように、階層的クラスタリングには主に4種類の近接法があります。 これは、クラスター間類似性とも呼ばれます。
メソッド(またはコードで定義されているリンケージ)には、次のものが含まれます。
- MINまたはシングルリンケージ
- MAXまたは完全なリンケージ
- 平均リンケージ
- セントロイドリンケージ
- 目的関数の排他関数
樹状図の作成中にリンケージオプションを適用することで、同じ結果を簡単に視覚化できます。
モデルの出力を視覚化するには、次のような小さなコードスニペットが必要です。
plt.scatter(X [:、0]、X [:、1]、c = cluster.labels_、cmap ='winter')
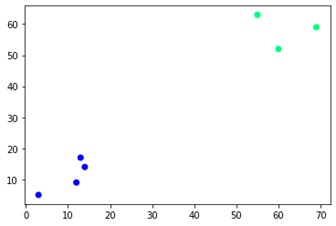
ご覧のとおり、反対側の角には2つの異なるクラスターがあります。 クラスター番号をいじって、さまざまな結果を確認することもできます。 樹状図をカットすることで、すべてを動かすことができます。 それを理解するために、樹状図の作成を視覚化するための小さなスニペットを書いてみましょう。
scipy.cluster.hierarchyモジュールの樹状図とリンケージ関数を使用します。 ここでは、使用するリンケージを定義します。 階層を生成するには、そのオブジェクトを樹状図関数に渡す必要があります。
scipy.cluster.hierarchyからインポート樹状図、リンケージ
リンク=linkage(X、'complete')
labelList = range(1、8)
plt.figure(figsize =(10、7))
樹状図(リンク、
方向='上'、
labels = labelList、
distance_sort ='descending'、
show_leaf_counts = True)
plt.show()
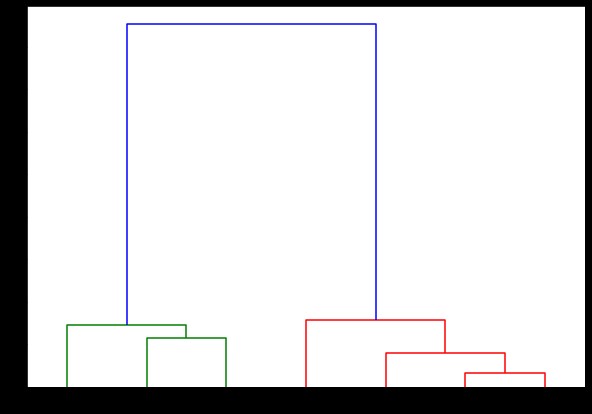
ここでは、各反復でクラスターがどのように形成されるかを視覚化できます。 したがって、樹状図を任意のレベルでカットすることができ、最終的にはその数のクラスターになります。 したがって、この階層の作成により、アルゴリズムとデータを1回実行しただけで、クラスターの数を変えることができます。 これは、階層的クラスタリングにK-meansなどの他のアルゴリズムの優位性を与えるものです。
次に、一般的に使用されるデータセットであるIRISでPythonで階層的クラスタリングを使用する方法を見てみましょう。 ローカルcsvからデータセットを読み取ります。 データセットがどのように見えるか、そして何を分類する必要があるかを一瞥してください。
numpyをnpとしてインポートします
パンダをpdとしてインポートします
matplotlib.pyplotをpltとしてインポートします
%matplotlibインライン
データ=pd.read_csv('iris.csv')
data.head()
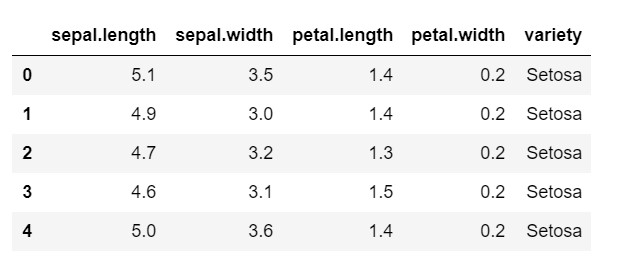
ご覧のとおり、ターゲット変数は「variety」クラスです。 モデルにはエンコードされたラベルが必要なため、これは文字列形式であり、数値に変換する必要があります。 これを行うには、sklearnの前処理ライブラリのラベルエンコーダーを使用します。 それらを数値に変換するための単純な近似と変換。
sklearnインポート前処理から
le = preprocessing.LabelEncoder()
le.fit(data ['variety'])
data ['variety'] = le.transform(data ['variety'])
ここで、これに樹状図を作成すると、さまざまな反復とマップが見つかります。 これは、単一のリンケージでどのように見えるかです。 同じコードを使用して、完全または重心のリンケージで実行すると、樹状図は少し異なります。 ロジックは同じままですが、異なるリンケージはクラスターのマージの順序に確実に影響します。
scipy.cluster.hierarchyからインポート樹状図、リンケージ
リンク=リンケージ(データ、'ワード')

plt.figure(figsize =(10、7))
樹状図(リンク)
plt.show()
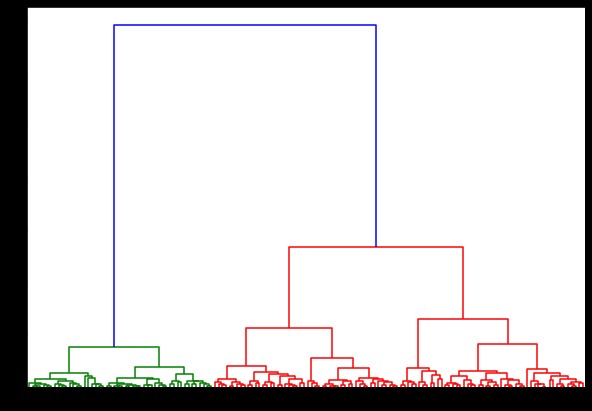
ここで、データセットにクラスタリングを適用すると、2つの異なるリンケージを使用し、クラスターを定義するときに実際にどのような違いがあるかが明確にわかります。 ラベルエンコーダーからすでに3つの異なるクラスがあることがわかったので、最初に3つのクラスターを適用できます。
sklearn.clusterからインポートAgglomerativeClustering
cluster = AgglomerativeClustering(n_clusters = 3、affinity ='euclidean'、linkage ='complete')
cluster.fit_predict(data)
plt.figure(figsize =(10、7))
plt.scatter(data ['sepal.length']、data ['petal.length']、c = cluster.labels_)

上の図からわかるように、3クラスター分類では、リンケージは予測の目に見える変化を示しています。 最初に病棟のつながりを見てください。 2つのクラスターの値がわずかに混ざっていても、上記のクラスターを定義したままにして、ラベルを正しく予測します。 しかし、完全なリンケージを見ると、クラスターが破壊され、一部の値が誤って分類されています。
近接法で知っているように、上で見ることができるように、完全なリンケージはより大きなクラスターを壊す傾向があります。 ウォード法またはシングルリンケージ法は、これらの問題に対する脆弱性が低くなります。 これは単純なデータセット用でした。 アルゴリズムがどのように影響を受け、ノイズの多いデータセットの影響を受けるかを見てみましょう。
そのようなデータセットの1つは、パルサー予測データセットまたはHTRU2データセットです。 データセットには約18,000のサンプルが含まれているため、より大きくなります。 MLパースペクティブで見た場合、データセットはかなり通常のサイズか、それよりも小さくなります。 ただし、比較的、IRISデータセットよりも重いです。 さまざまなデータセットに実装する必要があるのは、Pythonでの階層的クラスタリングのパフォーマンスを分析することです。 実装の方法と特典を明確に理解するには、
pulsar_data = pd.read_csv('pulsar_stars.csv')
pulsar_data.head()
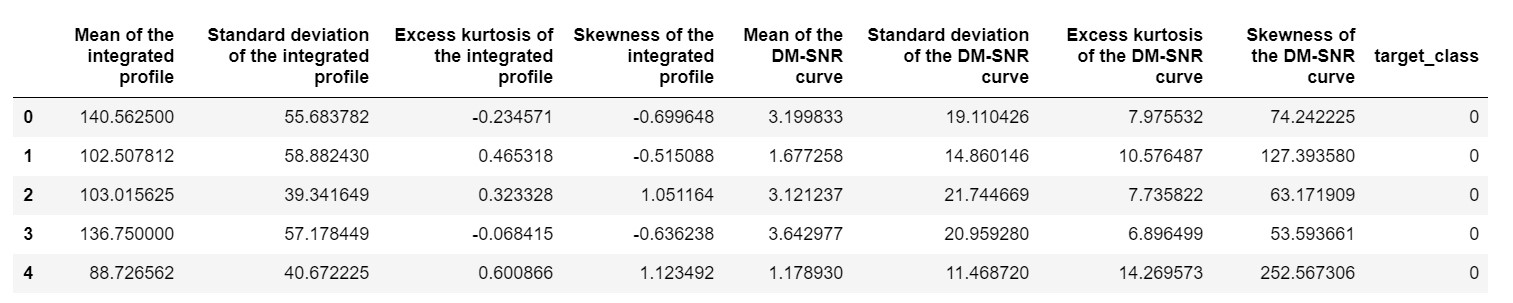
極端な値が原因でバイアスがかからないように、データセットを正規化する必要があります。
sklearn.preprocessingインポートから正規化
pulsar_data = normalize(pulsar_data)
標準コードを使用しますが、今回は両方の計算のタイミングを調整します。
%%時間
scipy.cluster.hierarchyからインポート樹状図、リンケージ
リンク=linkage(pulsar_data、'ward')
plt.figure(figsize =(10、7))
樹状図(リンク)
plt.show()
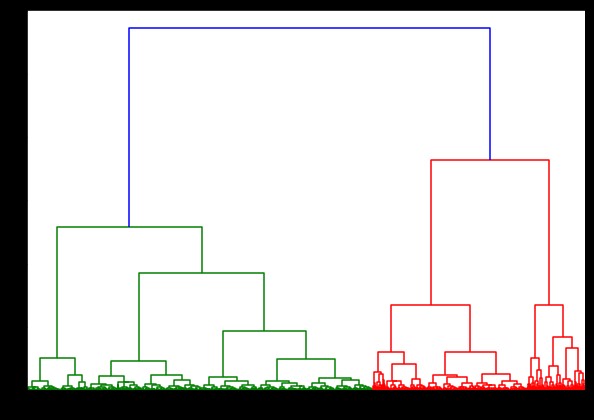
IRISデータセットで樹状図を生成するタイミングは6秒でした。 HTRU2データセットで樹状図を生成するタイミングは13分54秒でした。 ただし、これは、HTRU2データセットでトレーニングされたモデルで観察されるさまざまなリンケージによる予測の変化と比較して何もありません。
以前と同じ手順に従いましょう。 今回は、すべてのリンケージについて予測を行います。
次の図は、各リンケージを使用したクラスタリングの予測を示しています。
cluster = AgglomerativeClustering(n_clusters = 2、affinity ='euclidean'、linkage ='average')#また、complete、ward、single
cluster.fit_predict(pulsar_data)
plt.figure(figsize =(10、7))
plt.scatter(pulsar_data [:、1]、pulsar_data [:、7]、c = cluster.labels_)
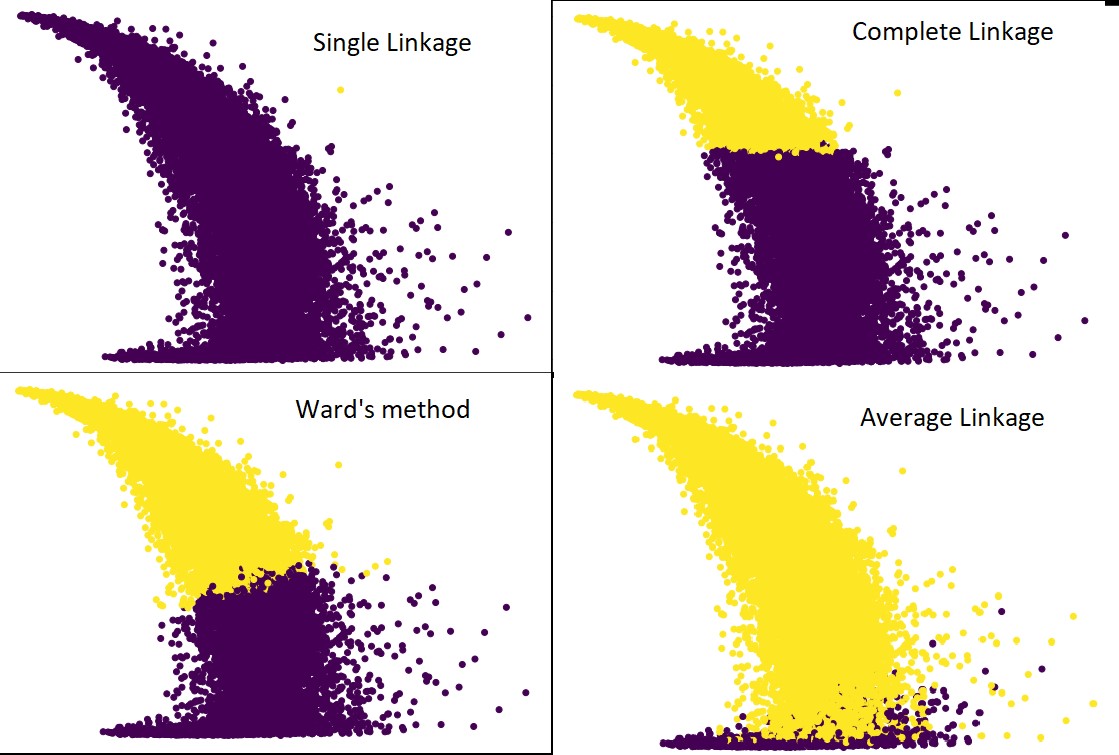
はい、予測が互いにどれほど異なるかは確かに驚くべきことです。 これは、階層的クラスタリングにおける近接行列の重要性を示しています。
ご覧のとおり、2つのクラスター間の最小距離が近接メトリックを定義するため、単一のリンケージはほぼすべてのポイントを取り込みます。 これにより、ノイズの多いデータに対して脆弱になります。 完全なリンケージを確認すると、データは確実に2つのクラスターに分割されますが、近接しているという理由だけで大きなクラスターが壊れている可能性があります。
平均リンケージは、2つの間のトレードオフです。 ノイズの影響は少ないですが、それでも大きなクラスターを壊す可能性がありますが、確率は低くなります。 そして、それは分類をよりよく処理します。
ウォード法のような目的関数は、K-meansのような他のクラスタリング手法を初期化するために使用されることがあります。 この方法は、平均リンケージと同様に、単一リンケージ方法と完全リンケージ方法の間にトレードオフがあります。 ウォード法のような目的関数は、誤分類の可能性を減らすために、主にカスタマイズされたソリューションで使用されます。 そして、私たちはそれがうまく機能しているのを見ています。
学習:データマイニングにおけるクラスター分析:アプリケーション、方法、要件
時間と空間の複雑さ
理解を深めるために、近接メトリックの定義と計算の方法を検討してください。 近接メトリックでは、データマップ内のクラスターのすべてのペア間の距離を保存する必要があります。 それはスペースの複雑さをもたらします:O(n2)。 多数です。 概観すると、1,000,000ポイントあると想像してください。 これにより、必要なスペースが1012ポイントになります。 1ポイントのサイズを1バイトとして概算することにより、大まかな平均をとると、1TBのデータサイズが得られます。 そして、これはハードドライブではなくRAMに保存する必要があります。
次に、時間の複雑さが生じます。 反復ごとに近接行列をスキャンする必要があり、nステップを実行することを考慮すると、複雑さはO(n3)として得られます。 特に大きなデータセットでは、計算コストが高くなります。
O(n2logn)まで下げることは可能かもしれませんが、それでもK-meansなどの他のクラスタリングアルゴリズムと比較するとコストがかかりすぎます。 アルゴリズムの空間と時間の複雑さの分析とコスト関数の最適化について詳しく知りたい場合は、データサイエンスと機械学習のupGradのプログラムに進んでください。
制限事項
- 最初の制限である空間と時間の複雑さについては、すでに説明しました。 大きなデータセットの場合、階層的クラスタリングが好ましくないことは明らかです。 より高速な計算機で時間計算量を管理したとしても、空間計算量は高すぎます。 特にRAMにロードするとき。 また、 Pythonで階層的クラスタリングを実装すると、速度の問題がさらに大きくなります。 Pythonは低速であり、大きなタスクが関係している場合、それは間違いなく苦しむでしょう。
- 第二に、近接性を備えた最適化された手法はありません。 それぞれに複数の問題と制限があることがわかった場合、これによりアルゴリズムの内部メカニズムが最適化されなくなります。
- クラスタリングの決定を見ると、それらは撤回可能ではありません。 意味-クラスタリングが一定の反復に適用されると、終了するまでそれ以降の反復で変更されることはありません。 したがって、構造の不正確さが原因で、アルゴリズムがいつでも間違ったクラスターを選択して結合または分割した場合、それは取り消すことができません。
- アルゴリズムを詳しく見ると、最小化されている明確な目的関数がありません。 他のアルゴリズムでは、最適化しようとする明確な関数があります。 たとえば、K-meansでは、階層的クラスタリングの場合とは異なり、最小化する明確なコスト関数があります。
チェックアウト:すべてのデータサイエンティストが知っておくべきトップ9のデータサイエンスアルゴリズム
結論
大規模なデータセットに関しては一定の制限がありますが、このタイプのクラスタリングアルゴリズムは、小規模から中規模のデータセットを処理する場合に魅力的です。 Pythonの階層的クラスタリングアルゴリズムは、時間と空間の複雑さに対する驚くべき必要性のため、アーキテクチャやスキーマの開発はあまり進んでいません。
そして、今がビッグデータの時代であることは事実です。 これは、より適切にスケーリングするアルゴリズムが必要であることを意味します。 ただし、それでも、クラスターの数がわからない場合、または分析を効率的に絞り込む必要がある場合は、Pythonでの階層的クラスタリングが適切な選択になる可能性があります。
これで、Pythonで階層的クラスタリングを実装する方法がわかりました。
機械学習とデータサイエンスにおけるこのようなアルゴリズムとメソッドのアプリケーションをさらに理解するには、upGradが提供するコースをご覧ください。 私たちはあなたがたどりたいキャリアパスのいずれかのための累積的なプログラムを持っています。
プログラムは、IIIT-Bの教授だけでなく一流の専門家によってキュレーションされています。 詳細については、 upGradにアクセスしてください。 ペースの速い技術の進歩の最前線に立つためにデータサイエンスを学ぶことに興味がある場合は、upGrad&IIIT-BのデータサイエンスのエグゼクティブPGプログラムをチェックしてください。
Pythonで階層的クラスタリングを実行する方法は?
階層的クラスタリングは、データポイントのラベル付けに使用される教師なし機械学習アルゴリズムの一種です。 階層的クラスタリングは、特性の類似性に基づいて要素をグループ化します。 階層的クラスタリングを実行するには、以下の手順に従う必要があります。
最初は、すべてのデータポイントをクラスターとして扱う必要があります。 したがって、最初のクラスターの数はKになります。ここで、Kはデータポイントの総数を表す整数です。
最も近い2つのデータポイントを結合してクラスターを構築し、K-1クラスターを残します。
さらにクラスターを形成し続けると、K-2クラスターなどになります。
目の前に大きなクラスターが形成されていることがわかるまで、この手順を繰り返します。
大きなクラスターが1つだけ残ったら、樹状図を使用して、問題の説明に基づいてそれらのクラスターを複数のクラスターに分割します。
これは、Pythonで階層的クラスタリングを実行するためのプロセス全体です。
階層的クラスタリングの2つのタイプはどれですか?
階層的クラスタリングには主に2つのタイプがあります。 彼らです:
凝集的クラスタリング
このクラスタリング手法は、AGNES(Agglomerative Nesting)とも呼ばれます。 このアルゴリズムは、ボトムアップアプローチを使用します。 ここでは、すべてのオブジェクトが単一要素クラスターと見なされます。 同様の特性を持つ2つのクラスターを組み合わせて、より大きなクラスターを形成します。 この方法は、1つの大きなクラスターが残るまで続きます。
分割階層的クラスタリング
このクラスタリング手法は、DIANA(Divisive Analysis)とも呼ばれます。 このアルゴリズムは、AGNESで使用されるものの逆であるトップダウンアプローチに従います。 ここで、ルートノードはすべての要素の巨大なクラスターで構成されます。 すべてのステップの後、最も異種のクラスターが分割され、このプロセスは、単一のクラスターが残るまで続けられます。
どのタイプの階層的クラスタリングアルゴリズムがより広く使用されていますか?
ご存知のように、階層的クラスタリングアルゴリズムには、凝集型クラスタリングと分割型クラスタリングの2種類があります。 両方のアルゴリズムの中で、階層的クラスタリングを実行するには、凝集アルゴリズムがより一般的に好まれます。
この方法では、ボトムアップアプローチを使用して、類似性に基づいてすべてのオブジェクトをグループ化します。 単一のノードから始めて、同様の特性を持つノードで満たされた単一の大きなクラスターに到達します。