
画像分類のための畳み込みニューラルネットワークの使用
公開: 2020-08-14画像分類はイメージチェンジを取得します。 CNNに感謝します。
畳み込みニューラルネットワーク(CNN)は、画像分類のバックボーンです。これは、画像を取得して、それを一意にするクラスとラベルを割り当てる深層学習現象です。 CNNを使用した画像分類は、機械学習実験の重要な部分を形成します。
CNNとその誘導機能を使用するとともに、Facebookの画像タグ付けから、Amazon製品の推奨事項、ヘルスケア画像、オートマチック車まで、さまざまなアプリケーションで広く使用されています。 CNNが非常に人気がある理由は、前処理がほとんど必要ないためです。つまり、他の従来のアルゴリズムでは不可能なフィルターを適用することで2D画像を読み取ることができます。 CNNを使用した画像分類がどのように機能するかについてのプロセスをさらに深く掘り下げます。
目次
CNNはどのように機能しますか?
CNNには、入力レイヤー、出力レイヤー、および非表示レイヤーが装備されており、これらはすべて画像の処理と分類に役立ちます。 隠れ層は、畳み込み層、ReLU層、プーリング層、および完全に接続された層で構成され、これらすべてが重要な役割を果たします。 畳み込みニューラルネットワークの詳細をご覧ください。
CNNを使用した画像分類がどのように機能するかを見てみましょう。
入力画像が象の画像であると想像してください。 ピクセルを含むこの画像は、最初に畳み込み層に入力されます。 白黒画像の場合、画像は2Dレイヤーとして解釈され、すべてのピクセルに「0」から「255」までの値が割り当てられ、「0」は完全に黒、「255」は完全に白になります。 一方、カラー画像の場合、これは3D配列になり、青、緑、赤のレイヤーがあり、各カラー値は0〜255です。

次に、マトリックスの読み取りが開始され、ソフトウェアは「フィルター」(またはカーネル)と呼ばれる小さな画像を選択します。 フィルタの深さは、入力の深さと同じです。 次に、フィルターは入力画像とともに畳み込み移動を生成し、画像に沿って1単位だけ右に移動します。
次に、値に元の画像の値を掛けます。 乗算されたすべての数値が合計され、単一の数値が生成されます。 このプロセスが画像全体とともに繰り返され、元の入力画像よりも小さい行列が取得されます。
最終的な配列は、アクティベーションマップの機能マップと呼ばれます。 画像の畳み込みは、さまざまなフィルターを適用することにより、エッジ検出、シャープニング、ブラーなどの操作を実行するのに役立ちます。 フィルタのサイズ、フィルタの数、ネットワークのアーキテクチャなどの側面を指定するだけです。
人間の観点からは、このアクションは画像の単純な色と境界を識別することに似ています。 ただし、画像を分類して、たとえば猫ではなく象の特徴を認識するためには、大きな耳や象の胴体などの固有の特徴を特定する必要があります。 これが、非線形層とプーリング層の出番です。
非線形層(ReLU)は畳み込み層の後に続き、画像の非線形性を高めるために活性化関数が特徴マップに適用されます。 ReLUレイヤーはすべての負の値を削除し、画像の精度を高めます。 tanhやsigmoidのような他の操作もありますが、ReLUはネットワークをはるかに高速にトレーニングできるため、最も人気があります。
次のステップは、同じオブジェクトの複数の画像を作成して、ネットワークがそのサイズや場所に関係なく、常にその画像を認識できるようにすることです。 たとえば、象の写真では、ネットワークは象が歩いているか、立っているか、走っているのかを認識している必要があります。 画像の柔軟性が必要であり、それがプーリングレイヤーの出番です。
画像の測定値(高さと幅)と連動して、入力画像のサイズを段階的に縮小し、画像内のオブジェクトをどこに配置しても見つけて識別できるようにします。
プーリングは、新しい情報の範囲がなく、情報が多すぎる場合の「過剰適合」の制御にも役立ちます。 おそらく、プーリングの最も一般的な例は、画像が一連の重複しない領域に分割される最大プーリングです。
最大プーリングとは、各領域の最大値を特定して、余分な情報をすべて除外し、画像のサイズを小さくすることです。 このアクションは、画像の歪みも考慮するのに役立ちます。
次に、CNNを使用するための人工ニューラルネットワークを追加する完全に接続されたレイヤーが登場します。 この人工ニューラルネットワークは、さまざまな機能を組み合わせて、画像クラスをより正確に予測するのに役立ちます。 この段階で、ニューラルネットワークの重みに関する誤差関数の勾配が計算されます。 重みと特徴検出器は、パフォーマンスを最適化するように調整され、このプロセスが繰り返し繰り返されます。
CNNアーキテクチャは次のようになります。
ソース
CNNアプリケーションのデータセットの活用-MNIST
CNNを効果的に適用するために、いくつかのデータセットを使用できます。 CNNを使用した画像分類に不可欠な3つの最も人気のあるものは、MNIST、CIFAR-10、およびImageNetです。 最初にMNISTを見てみましょう。
1. MNIST
MNISTは、米国国立標準技術研究所のデータセットの頭字語であり、0から9までの単一の手書き数字の60,000個の小さな正方形の28×28グレースケール画像で構成されています。一部、「解決済み」。 これは、 CNNを使用して画像分類を実践、開発、および評価するためのコンピュータービジョンおよびディープラーニングで使用できます。 特に、これには、モデルのパフォーマンスを評価し、可能な改善を調査し、それを使用して新しいデータを予測する手順が含まれます。
そのUSPは、使用できる明確に定義されたトレインとテストのデータセットがすでにあるということです。 このトレーニングセットは、トレーニング実行モデルのパフォーマンスを評価する必要がある場合、さらにトレインに分割してデータセットを検証できます。 トレインでのパフォーマンスと各実行での検証セットは、モデルが問題をどの程度学習しているかについての洞察を深めるための学習曲線として記録できます。
主要なニューラルネットワークAPIの1つであるKerasは、モデルに「validation_data 」引数を指定することでこれをサポートしています。 モデルをトレーニングするときのFit()関数。最終的には、各トレーニング実行での損失とメトリックのモデルパフォーマンスに言及するオブジェクトを返します。 幸い、MNISTにはデフォルトでKerasが装備されており、トレインファイルとテストファイルはわずか数行のコードを使用してロードできます。
興味深いことに、ニューヨーク大学のCourant Institute of MathematicalSciencesの教授であるYannLeCunと、ニューヨークのGoogleLabsの研究科学者であるCorinnaCortesによる記事は、MNISTの特別データベース3(SD-3)が元々トレーニングセット。 特別データベース1(SD-1)がテストセットとして指定されました。

ただし、SD-3は国勢調査局で働く従業員から収集されたものであり、SD-1は高校生から調達されたものであるため、SD-3はSD-1よりもはるかに識別および認識しやすいと彼らは考えています。 学習実験からの正確な結論は、結果がトレーニングセットとテストから独立している必要があることを義務付けているため、データセットを欠落させて新しいデータベースを開発する必要があると見なされました。
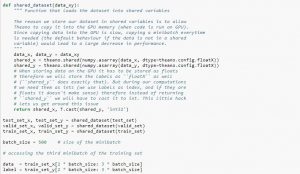
データセットを使用するときは、データセットをミニバッチに分割し、共有変数に格納し、ミニバッチインデックスに基づいてアクセスすることをお勧めします。 共有変数の必要性について疑問に思われるかもしれませんが、これはGPUの使用に関連しています。 データをGPUメモリにコピーするときに、必要に応じて各ミニバッチを個別にコピーすると、GPUコードの速度が低下し、CPUコードよりも大幅に高速化されなくなります。 Theano共有変数にデータがある場合、共有変数が作成されるときに、データ全体を一度にGPUにコピーする可能性が高くなります。
後でGPUは、CPUメモリから情報をコピーすることなく、これらの共有変数にアクセスすることでミニバッチを使用できます。 また、データポイントは通常、実数とラベル整数であるため、コードを読みやすくするために、これらと検証セット、トレーニングセット、およびテストセットに異なる変数を使用するとよいでしょう。
以下のコードは、データを保存してミニバッチにアクセスする方法を示しています。
ソース
2.CIFAR-10データセット
CIFARはカナダ先端研究機構の略で、CIFAR-10データセットは、CIFAR-100データセットとともにCIFAR研究所の研究者によって開発されました。 CIFAR-10データセットは、猫、船、鳥、カエルなどの10のクラスに属するオブジェクトの60,000個の32×32ピクセルカラー画像で構成されています。これらの画像は平均的な写真よりもはるかに小さく、コンピュータービジョンを目的としています。
CIFARは、 CNNプロセスを使用した画像分類で80%正確であり、テストデータセットで90%正確である、よく理解された単純なデータセットです。 また、1,000枚もの画像が1つのテストバッチと5つのトレーニングバッチに分散しています。
CIFAR-10データセットは、各クラスからランダムに選択された1,000枚の画像で構成されていますが、一部のバッチには、あるクラスの画像が別のクラスよりも多く含まれている場合があります。 ただし、トレーニングバッチには、各クラスの5,000枚の画像が含まれています。 CIFAR-10データセットは、問題を使用して画像分類CNNを解決するための開始点として使いやすいために推奨されます。
テストハーネスの設計はモジュール式であり、データセットの読み込み、モデルの定義、データセットの準備、評価と結果の表示を含む5つの要素で開発できます。 以下の例は、トレーニングデータセットの最初の9つの画像でKerasAPIを使用したCIFAR-10データセットを示しています。
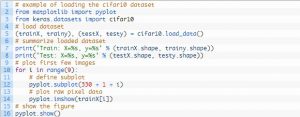
ソース
例を実行すると、CIFAR-10データセットが読み込まれ、その形状が出力されます。
3. ImageNet
ImageNetは、事前定義された単語やフレーズに基づいて、画像を22,000近くのカテゴリに分類してラベル付けすることを目的としています。 これを行うには、WordNet階層に従います。ここで、すべての単語または句は同義語または同義語(略して)です。 ImageNetでは、すべての画像がこれらのシンセットに従って編成され、シンセットごとに1,000を超える画像が含まれます。
ただし、ImageNetがコンピュータービジョンやディープラーニングで参照される場合、実際に意味されるのはImageNet Large ScaleRecognitionChallengeまたはILSVRCです。 ここでの目標は、トレーニングデータセットに約120万枚の画像が含まれているため、100,000を超えるテスト画像を使用して画像を1,000の異なるカテゴリに分類することです。
おそらくここでの最大の課題は、ImageNetの画像のサイズが224×224であるため、このような大量のデータを処理するには、CPU、GPU、およびRAMの大容量が必要になることです。 これは平均的なラップトップでは不可能であることがわかるかもしれませんが、この問題をどのように克服するのでしょうか。
これを行う1つの方法は、ImageNetから抽出されたデータセットであるImagenetteを使用することです。これは、あまり多くのリソースを必要としません。 このデータセットには、「train」(トレーニング)と「Val」(検証)という名前の2つのフォルダーがあり、クラスごとに個別のフォルダーがあります。 これらのクラスはすべて元のデータセットと同じIDを持ち、各クラスには約1,000の画像があるため、セットアップ全体はかなりバランスが取れています。
もう1つのオプションは、大規模なデータセットで事前にトレーニングされた重みを使用する方法である転移学習を使用することです。 これは、 CNNを使用した画像分類の非常に効果的な方法です。これを使用して、適切に機能するモデルを作成できるからです。 CNNモデルを使用した画像分類で実行できる必要がある1つの側面は、同じクラスに属する画像を分類し、異なる画像を区別することです。 ここで、事前にトレーニングされたウェイトを利用できます。 ここでの利点は、使用しているデータセットの種類に応じてさまざまな方法を使用できることです。
また読む: MLエンジニアが知っておくべき7種類の人工ニューラルネットワーク
まとめ
要約すると、 CNNを使用した画像分類により、プロセスがより簡単に、より正確になり、プロセスの負担が軽減されました。 機械学習をさらに深く掘り下げたい場合は、 upGradにプロのように習得するのに役立つさまざまなコースがあります。
upGradは、さまざまなサブカテゴリを備えたさまざまなコースをオンラインで提供しています。 詳細については、公式サイトをご覧ください。
機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディと課題、IIIT-を提供します。 B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。
畳み込みニューラルネットワークとは何ですか?
畳み込みニューラルネットワーク(CNN)、またはconvnetsは、深いフィードフォワード人工ニューラルネットワークのカテゴリであり、視覚的イメージの分析に最も一般的に適用されます。 CNNの設計は、哺乳類の視覚野の組織化に大まかに触発されていますが、オーディオ、スピーチ、およびその他のドメインにも適用されています。 CNNは、最小限の前処理を必要とするように設計された多層パーセプトロンのバリエーションを使用します。 これにより、エラーが発生しにくくなり、さまざまな問題に対応しやすくなりますが、入力に対して非線形変換を実行する機能が犠牲になります。
畳み込みニューラルネットワークが画像分類に適しているのはなぜですか?
CNNの大きな制限は、画像内のコンテキストを把握できないことです。 また、顔や色もできません。 CNNのその他の制限:ニューラルネットワークで使用される学習手法は、オブジェクト認識、学習、空間認識、経験を伝達する能力などのより高度な認知機能を再現するには不十分です。 ニューラルネットワークのアーキテクチャは、これらの制限を克服するのに十分な柔軟性がありません。