
Utilizzo della rete neurale convoluzionale per la classificazione delle immagini
Pubblicato: 2020-08-14La classificazione delle immagini si rinnova. Grazie alla CNN.
Le reti neurali convoluzionali (CNN) sono la spina dorsale della classificazione delle immagini, un fenomeno di deep learning che prende un'immagine e le assegna una classe e un'etichetta che la rendono unica. La classificazione delle immagini tramite la CNN costituisce una parte significativa degli esperimenti di apprendimento automatico.
Insieme all'utilizzo della CNN e delle sue capacità indotte, ora è ampiamente utilizzato per una vasta gamma di applicazioni, dall'etichettatura delle immagini di Facebook ai consigli sui prodotti Amazon e alle immagini sanitarie fino alle auto automatiche. Il motivo per cui la CNN è così popolare è che richiede pochissima pre-elaborazione, il che significa che può leggere immagini 2D applicando filtri che altri algoritmi convenzionali non possono. Approfondiremo il processo di come funziona la classificazione delle immagini utilizzando la CNN .
Sommario
Come funziona la CNN?
Le CNN sono dotate di un livello di input, un livello di output e livelli nascosti, che aiutano tutti a elaborare e classificare le immagini. I livelli nascosti comprendono livelli convoluzionali, livelli ReLU, livelli di pooling e livelli completamente connessi, che svolgono tutti un ruolo cruciale. Ulteriori informazioni sulla rete neurale convoluzionale.
Diamo un'occhiata a come funziona la classificazione delle immagini utilizzando la CNN :
Immagina che l'immagine in ingresso sia quella di un elefante. Questa immagine, con i pixel, viene prima inserita nei livelli convoluzionali. Se si tratta di un'immagine in bianco e nero, l'immagine viene interpretata come un livello 2D, con ogni pixel assegnato un valore compreso tra '0' e '255', '0' è completamente nero e '255' completamente bianco. Se invece è un'immagine a colori, questa diventa un array 3D, con uno strato blu, verde e rosso, con ogni valore di colore compreso tra 0 e 255.

Inizia quindi la lettura della matrice, per la quale il software seleziona un'immagine più piccola, nota come 'filtro' (o kernel). La profondità del filtro è la stessa della profondità dell'input. Il filtro produce quindi un movimento di convoluzione insieme all'immagine in ingresso, spostandosi lungo l'immagine di 1 unità.
Quindi moltiplica i valori con i valori dell'immagine originale. Tutte le cifre moltiplicate vengono sommate e viene generato un unico numero. Il processo viene ripetuto insieme all'intera immagine e si ottiene una matrice, più piccola dell'immagine di input originale.
L'array finale è chiamato mappa delle caratteristiche di una mappa di attivazione. La convoluzione di un'immagine aiuta a eseguire operazioni come il rilevamento dei bordi, la nitidezza e la sfocatura, applicando diversi filtri. Basta specificare aspetti come la dimensione del filtro, il numero di filtri e/o l'architettura della rete.
Dal punto di vista umano, questa azione è simile all'identificazione dei colori e dei confini semplici di un'immagine. Tuttavia, per classificare l'immagine e riconoscere le caratteristiche che la rendono, ad esempio, quella di un elefante e non di un gatto, è necessario identificare caratteristiche uniche come le grandi orecchie e la proboscide dell'elefante. È qui che entrano in gioco i livelli non lineari e di pooling.
Il livello non lineare (ReLU) segue il livello di convoluzione, dove viene applicata una funzione di attivazione alle mappe delle caratteristiche per aumentare la non linearità dell'immagine. Il livello ReLU rimuove tutti i valori negativi e aumenta la precisione dell'immagine. Sebbene ci siano altre operazioni come tanh o sigmoid, ReLU è la più popolare poiché può addestrare la rete molto più velocemente.
Il passaggio successivo consiste nel creare più immagini dello stesso oggetto in modo che la rete possa sempre riconoscere quell'immagine, qualunque sia la sua dimensione o posizione. Ad esempio, nell'immagine dell'elefante, la rete deve riconoscere l'elefante, sia che stia camminando, sia fermo o correndo. Ci deve essere flessibilità dell'immagine, ed è qui che entra in gioco il livello di pooling.
Funziona con le misure dell'immagine (altezza e larghezza) per ridurre progressivamente le dimensioni dell'immagine di input in modo che gli oggetti nell'immagine possano essere individuati e identificati ovunque si trovi.
Il pooling aiuta anche a controllare il "overfitting" dove ci sono troppe informazioni senza possibilità di nuove. Forse l'esempio più comune di pooling è il max pooling, in cui l'immagine è divisa in una serie di aree non sovrapposte.
Il raggruppamento massimo consiste nell'identificare il valore massimo in ciascuna area in modo da escludere tutte le informazioni aggiuntive e ridurre le dimensioni dell'immagine. Questa azione aiuta anche a tenere conto delle distorsioni nell'immagine.
Ora arriva il livello completamente connesso che aggiunge una rete neurale artificiale per l'utilizzo della CNN. Questa rete artificiale combina diverse funzionalità e aiuta a prevedere le classi di immagini con maggiore precisione. A questo punto viene calcolato il gradiente della funzione di errore rispetto al peso della rete neurale. I pesi e i rilevatori di funzioni vengono regolati per ottimizzare le prestazioni e questo processo viene ripetuto ripetutamente.
Ecco come appare l'architettura della CNN:
Fonte
Sfruttare i set di dati per CNN Application-MNIST
È possibile utilizzare diversi set di dati per applicare la CNN in modo efficace. I tre più popolari vitali nella classificazione delle immagini utilizzando la CNN sono MNIST, CIFAR-10 e ImageNet. Diamo prima un'occhiata a MNIST.
1. MNIST
MNIST è l'acronimo di Modified National Institute of Standards and Technology set di dati e comprende 60.000 piccole immagini quadrate in scala di grigi 28 × 28 di singole cifre scritte a mano comprese tra 0 e 9. MNIST è un set di dati popolare e ben compreso, per la maggiore parte, 'risolta.' Può essere utilizzato nella visione artificiale e nell'apprendimento profondo per esercitarsi, sviluppare e valutare la classificazione delle immagini utilizzando la CNN . Tra le altre cose, ciò include passaggi per valutare le prestazioni del modello, esplorare possibili miglioramenti e utilizzarlo per prevedere nuovi dati.
Il suo USP è che ha già un treno ben definito e un set di dati di test che possiamo usare. Questo set di addestramento può essere ulteriormente suddiviso in un treno e un set di dati di convalida se è necessario valutare le prestazioni di un modello di esecuzione dell'addestramento. Le sue prestazioni nel treno e il set di convalida a ogni corsa possono essere registrate come curve di apprendimento per una maggiore comprensione di quanto bene il modello sta imparando il problema.
Keras, una delle principali API di reti neurali, supporta questo prevedendo l'argomento "validation_data " nel modello. Funzione Fit() durante il training del modello, che alla fine restituisce un oggetto che menziona le prestazioni del modello per la perdita e le metriche su ogni esecuzione di training. Fortunatamente, MNIST è dotato di Keras per impostazione predefinita e il treno e i file di test possono essere caricati utilizzando solo poche righe di codice.
È interessante notare che un articolo di Yann LeCun, professore al Courant Institute of Mathematical Sciences della New York University e Corinna Cortes, ricercatrice presso i Google Labs di New York, sottolinea che lo Special Database 3 (SD-3) del MNIST è stato originariamente assegnato come insieme di allenamento. Il database speciale 1 (SD-1) è stato designato come set di prova.

Tuttavia, credono che l'SD-3 sia molto più facile da identificare e riconoscere rispetto all'SD-1 perché l'SD-3 è stato raccolto dai dipendenti che lavorano nel Census Bureau, mentre l'SD-1 è stato acquistato tra gli studenti delle scuole superiori. Poiché le conclusioni accurate degli esperimenti di apprendimento richiedono che il risultato debba essere indipendente dal set di formazione e dal test, si è ritenuto necessario sviluppare un nuovo database mancando i set di dati.
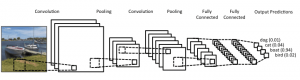
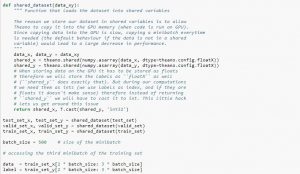
Quando si utilizza il set di dati, si consiglia di dividerlo in minibatch, archiviarlo in variabili condivise e accedervi in base all'indice minibatch. Potresti chiederti della necessità di variabili condivise, ma questo è collegato all'uso della GPU. Quello che succede è che quando si copiano i dati nella memoria della GPU, se si copia ogni minibatch separatamente come e quando necessario, il codice della GPU rallenterà e non sarà molto più veloce del codice della CPU. Se hai i tuoi dati nelle variabili condivise di Theano, ci sono buone possibilità di copiare tutti i dati sulla GPU in una volta sola quando le variabili condivise vengono create.
Successivamente la GPU può utilizzare il minibatch accedendo a queste variabili condivise senza dover copiare le informazioni dalla memoria della CPU. Inoltre, poiché i punti dati sono solitamente numeri reali ed etichette intere, sarebbe utile utilizzare variabili diverse per questi così come per il set di convalida, un set di addestramento e un set di test, per rendere il codice più facile da leggere.
Il codice seguente mostra come memorizzare i dati e accedere a un minibatch:
Fonte
2. Set di dati CIFAR-10
CIFAR sta per Canadian Institute for Advanced Research e il set di dati CIFAR-10 è stato sviluppato dai ricercatori dell'istituto CIFAR, insieme al set di dati CIFAR-100. Il set di dati CIFAR-10 è costituito da 60.000 immagini a colori 32×32 pixel di oggetti appartenenti a dieci classi come gatti, navi, uccelli, rane, ecc. Queste immagini sono molto più piccole di una fotografia media e sono destinate a scopi di visione artificiale.
CIFAR è un set di dati semplice e ben compreso che è accurato all'80% nella classificazione delle immagini utilizzando il processo CNN e al 90% nel set di dati di test. Inoltre, fino a 1.000 immagini distribuite su un batch di prova e cinque batch di addestramento.
Il set di dati CIFAR-10 è costituito da 1.000 immagini selezionate casualmente da ciascuna classe, ma alcuni batch potrebbero contenere più immagini di una classe rispetto a un'altra. Tuttavia, i batch di formazione contengono esattamente 5.000 immagini di ciascuna classe. Il set di dati CIFAR-10 è preferito per la sua facilità d'uso come punto di partenza per risolvere i problemi di classificazione delle immagini CNN utilizzando.
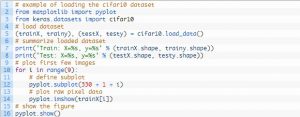
Il design del suo cablaggio di prova è modulare e può essere sviluppato con cinque elementi che includono il caricamento del set di dati, la definizione del modello, la preparazione del set di dati e la valutazione e la presentazione dei risultati. L'esempio seguente mostra il set di dati CIFAR-10 utilizzando l'API Keras con le prime nove immagini nel set di dati di addestramento:
Fonte
L'esecuzione dell'esempio carica il dataset CIFAR-10 e ne stampa la forma.
3. Rete di immagini
ImageNet mira a classificare ed etichettare le immagini in quasi 22.000 categorie basate su parole e frasi predefinite. Per fare ciò, segue la gerarchia di WordNet, dove ogni parola o frase è un sinonimo o synset (in breve). In ImageNet, tutte le immagini sono organizzate in base a questi synset, per avere oltre mille immagini per synset.
Tuttavia, quando si fa riferimento a ImageNet nella visione artificiale e nell'apprendimento profondo, ciò che in realtà si intende è ImageNet Large Scale Recognition Challenge o ILSVRC. L'obiettivo qui è classificare un'immagine in 1.000 diverse categorie utilizzando oltre 100.000 immagini di test poiché il set di dati di addestramento contiene circa 1,2 milioni di immagini.
Forse la sfida più grande qui è che le immagini in ImageNet misurano 224 × 224, quindi l'elaborazione di una così grande quantità di dati richiede un'enorme capacità di CPU, GPU e RAM. Questo potrebbe rivelarsi impossibile per un laptop medio, quindi come si fa a superare questo problema?
Un modo per farlo è utilizzare Imagenette, un set di dati estratto da ImageNet che non richiede troppe risorse. Questo set di dati ha due cartelle denominate "train" (formazione) e "Val" (convalida) con cartelle individuali per ogni classe. Tutte queste classi hanno lo stesso ID del set di dati originale, con ciascuna delle classi con circa 1.000 immagini, quindi l'intera configurazione è abbastanza bilanciata.
Un'altra opzione consiste nell'usare il transfer learning, un metodo che utilizza pesi pre-addestrati su grandi set di dati. Questo è un modo molto efficace per classificare le immagini usando la CNN perché possiamo usarlo per produrre modelli che funzionano bene per noi. L'unico aspetto che una classificazione delle immagini che utilizza il modello CNN dovrebbe essere in grado di fare è classificare le immagini appartenenti alla stessa classe e distinguere tra quelle diverse. È qui che possiamo utilizzare i pesi pre-allenati. Il vantaggio qui è che possiamo utilizzare metodi diversi a seconda del tipo di set di dati con cui stiamo lavorando.
Leggi anche: I 7 tipi di reti neurali artificiali che gli ingegneri ML devono conoscere
Riassumendo
Per riassumere, la classificazione delle immagini utilizzando la CNN ha reso il processo più semplice, più accurato e meno pesante. Se desideri approfondire l'apprendimento automatico, upGrad ha una gamma di corsi che ti aiutano a padroneggiarlo come un professionista!
upGrad offre vari corsi online con un'ampia gamma di sottocategorie; visitare il sito ufficiale per ulteriori informazioni.
Se sei interessato a saperne di più sull'apprendimento automatico, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, IIIT- B Status di Alumni, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Cosa sono le reti neurali convoluzionali?
Le reti neurali convoluzionali (CNN), o convnet, sono una categoria di reti neurali artificiali profonde e feed-forward, più comunemente applicate all'analisi delle immagini visive. Il design delle CNN è vagamente ispirato dall'organizzazione della corteccia visiva dei mammiferi, sebbene siano state applicate anche all'audio, alla parola e ad altri domini. Le CNN utilizzano una variazione di perceptron multistrato progettata per richiedere una preelaborazione minima. Ciò li rende meno soggetti a errori e più portabili a una serie diversificata di problemi, ma sacrifica la capacità di eseguire trasformazioni non lineari sui loro input.
Perché le reti neurali convoluzionali sono utili per la classificazione delle immagini?
Il grande limite della CNN è che non è in grado di cogliere il contesto in un'immagine. Inoltre non è in grado di fare facce e colorare. Ulteriori limitazioni della CNN: le tecniche di apprendimento utilizzate nelle reti neurali non sono sufficienti per riprodurre funzioni cognitive superiori come il riconoscimento degli oggetti, l'apprendimento, la consapevolezza spaziale e la capacità di trasferire l'esperienza. L'architettura delle reti neurali non è sufficientemente flessibile per superare queste limitazioni.