
Introduzione pratica alla convalida e alla regolarizzazione del modello nell'apprendimento profondo utilizzando TensorFlow
Pubblicato: 2020-10-28Sommario
introduzione
La pratica delle macchine per assimilare le informazioni attraverso il paradigma degli algoritmi di apprendimento supervisionato ha rivoluzionato diversi compiti come la generazione di sequenze, l'elaborazione del linguaggio naturale e persino la visione artificiale. Questo approccio si basa sull'utilizzo di un set di dati che dispone di un insieme di funzioni di input e di un corrispondente insieme di etichette. La macchina utilizza quindi queste informazioni presenti sotto forma di caratteristiche ed etichette per apprendere la distribuzione e gli schemi dei dati per fare previsioni statistiche su input invisibili.
Un passaggio fondamentale nella progettazione di modelli di deep learning è la valutazione delle prestazioni del modello, in particolare su punti dati nuovi e invisibili. L'obiettivo principale è sviluppare modelli che si generalizzino al di là dei dati su cui sono stati addestrati. Vogliamo modelli che possano fare previsioni valide e affidabili nel mondo reale. Un concetto importante che ci aiuta in questo è la convalida e la regolarizzazione del modello di cui parleremo oggi.
Convalida del modello
La creazione di un modello di machine learning si riduce sempre alla suddivisione dei dati disponibili in tre set: training, validazione e set di test. I dati di addestramento vengono utilizzati dal modello per apprendere le stranezze e le caratteristiche della distribuzione.
Un punto focale da sapere qui è che una performance soddisfacente del modello sul training set non significa che il modello si generalizzerà anche su nuovi dati con prestazioni simili, questo perché il modello è diventato distorto rispetto al training set. Il concetto di validazione e set di test viene quindi utilizzato per segnalare quanto bene il modello si generalizza su nuovi punti dati.
La procedura standard consiste nell'utilizzare i dati di addestramento per adattarsi al modello, valutare le prestazioni del modello utilizzando i dati di convalida e infine i dati del test vengono utilizzati per valutare quanto bene il modello funzionerà su esempi assolutamente nuovi.
Il set di validazione viene utilizzato per ottimizzare gli iperparametri (numero di livelli nascosti, tasso di apprendimento, tasso di abbandono, ecc.) in modo che il modello possa generalizzarsi bene. Un enigma comune affrontato dai principianti dell'apprendimento automatico è comprendere la necessità di una convalida separata e set di test.

La necessità di due insiemi distinti può essere compresa dalla seguente intuizione: per ogni rete neurale profonda che deve essere progettata, esistono più numeri di iperparametri che devono essere regolati per prestazioni soddisfacenti.
È possibile eseguire il training di più modelli utilizzando uno degli iperparametri, quindi è possibile selezionare il modello con la metrica delle prestazioni migliori in base alle prestazioni di quel modello sul set di convalida. Ora, ogni volta che gli iperparametri vengono modificati per prestazioni migliori sul set di convalida, alcune informazioni vengono trapelate/inserite nel modello, quindi i pesi finali della rete neurale potrebbero essere distorti rispetto al set di convalida.
Dopo ogni regolazione dell'iperparametro, il nostro modello continua a funzionare bene sul set di convalida perché è per questo che lo abbiamo ottimizzato. Questo è il motivo per cui il test di validazione non può denotare accuratamente la capacità di generalizzazione del modello. Per ovviare a questo inconveniente, entra in gioco il test set.
La rappresentazione più accurata dell'abilità di generalizzazione di un modello è data dalle prestazioni sul set di test poiché non abbiamo ottimizzato il modello per prestazioni migliori su questo set e, quindi, questo indicherà la stima più pragmatica dell'abilità del modello.
Da leggere: le migliori tecniche di deep learning che dovresti conoscere
Implementazione di strategie di convalida utilizzando TensorFlow 2.0
TensorFlow 2.0 fornisce una soluzione estremamente semplice per monitorare le prestazioni del nostro modello in un test di convalida separato. Possiamo passare l' argomento della parola chiave validation_split nel metodo model.fit() .
La parola chiave validation_split accetta l'input come un numero mobile compreso tra 0 e 1 che rappresenta la frazione di dati di addestramento da utilizzare come dati di convalida. Quindi, passare il valore di 0,1 nella parola chiave significa riservare il 10% dei dati di addestramento per la convalida.
L'implementazione pratica della suddivisione della convalida può essere facilmente dimostrata utilizzando il Diabetes Dataset di sklearn. Il set di dati ha 442 istanze con 10 variabili di riferimento (età, sesso, BMI, ecc.) come caratteristiche di allenamento e la misura della progressione della malattia dopo un anno come etichetta.
Importiamo il set di dati utilizzando TensorFlow e sklearn:

Il passaggio fondamentale dopo la pre-elaborazione dei dati è costruire una rete neurale feedforward sequenziale con strati densi:

Qui abbiamo una rete neurale con sei livelli nascosti con attivazione relu e uno strato di output con attivazione lineare .
Quindi compiliamo il modello con l' ottimizzatore Adam e la funzione di perdita dell'errore quadratico medio .


Il metodo model.fit() viene quindi utilizzato per addestrare il modello per 100 epoche con un validation_split del 15%.

Possiamo anche tracciare la perdita del modello osservata sia per i dati di addestramento che per i dati di convalida:
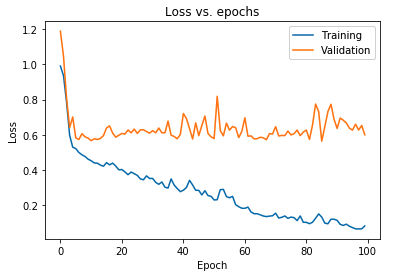
Il grafico visualizzato sopra mostra che la perdita di convalida aumenta continuamente dopo 10 epoche mentre la perdita di addestramento continua a diminuire. Questa tendenza è un esempio da manuale di un problema incredibilmente significativo nell'apprendimento automatico chiamato overfitting .
Sono state condotte molte ricerche seminali per superare questo problema e collettivamente queste soluzioni sono chiamate tecniche di regolarizzazione . La sezione seguente tratterà l'aspetto della regolarizzazione e la procedura per regolarizzare qualsiasi modello di deep learning.
Regolarizzare il nostro Modello
Nella sezione precedente abbiamo osservato una tendenza inversa nei diagrammi di perdita degli insiemi di addestramento e validazione in cui il diagramma della funzione di costo dell'ultimo insieme sembra aumentare e quello del primo insieme continua a diminuire e, quindi, creando un divario ( gap di generalizzazione ). Ulteriori informazioni sulla regolarizzazione nell'apprendimento automatico.
Il fatto che esista un tale divario tra i due diagrammi di perdita simboleggia che il modello non può generalizzare bene sul set di validazione ( dati non visti) e quindi anche il valore del costo/perdita sostenuto su quel set di dati sarebbe inevitabilmente elevato.
Questa particolarità si verifica perché i pesi e le distorsioni del modello addestrato vengono co-adattati per apprendere la distribuzione dei dati di addestramento così bene, che non riesce a prevedere le etichette di funzionalità nuove e invisibili portando a una maggiore perdita di convalida.
La logica è che la configurazione di un modello complesso produrrà tali anomalie poiché i parametri del modello crescono fino a diventare altamente robusti per i dati di addestramento. Quindi, semplificare o ridurre la capacità/complessità dei modelli ridurrà l'effetto di overfitting. Un modo per raggiungere questo obiettivo è utilizzare gli abbandoni nel nostro modello di deep learning, di cui parleremo nella prossima sezione.
Comprensione e implementazione dei dropout in TensorFlow
La percezione chiave alla base dell'utilizzo dei dropout è quella di eliminare casualmente le unità nascoste e visibili al fine di ottenere un modello meno complesso che limita l'aumento dei parametri del modello e, quindi, rende il modello più robusto per le prestazioni su un set di dati generalizzato.
Questa pratica recentemente accettata è un potente approccio utilizzato dai professionisti dell'apprendimento automatico per indurre un effetto regolarizzante in qualsiasi modello di apprendimento profondo. I dropout possono essere implementati senza sforzo utilizzando l'API Keras su TensorFlow importando il livello di dropout e passando l' argomento rate in esso per specificare la frazione di unità che deve essere eliminata.
Questi strati di dropout sono generalmente impilati subito dopo ogni strato denso per produrre una marea alternata di un'architettura di strato di dropout denso .
Possiamo modificare la nostra rete neurale feedforward precedentemente definita per includere sei livelli di abbandono , uno per ogni livello nascosto:


Qui, il tasso di abbandono _ è stato impostato su 0,2, il che significa che il 20% dei nodi verrà eliminato durante l'addestramento del modello. Compiliamo e formiamo il modello con lo stesso ottimizzatore, funzione di perdita, metriche e numero di epoche per fare un confronto equo.
L'impatto primario della regolarizzazione del modello mediante dropout può essere interpretato tracciando nuovamente la curva di perdita del modello ottenuto sui set di addestramento e validazione:
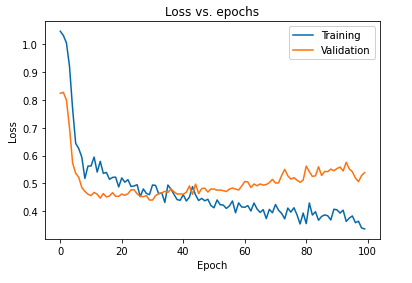
È evidente dal grafico di cui sopra che il gap di generalizzazione ottenuto dopo la regolarizzazione del modello è molto inferiore, il che rende il modello meno suscettibile all'overfit dei dati di addestramento.
Leggi anche: Idee per progetti di deep learning
Conclusione
L'aspetto della convalida e della regolarizzazione del modello è una parte essenziale della progettazione del flusso di lavoro per la creazione di qualsiasi soluzione di machine learning. Sono state condotte molte ricerche per improvvisare l'apprendimento supervisionato e questo tutorial pratico fornisce una breve panoramica di alcune delle pratiche e delle tecniche più accettate durante l'assemblaggio di qualsiasi algoritmo di apprendimento.
Se sei interessato a saperne di più sulle tecniche di deep learning e machine learning, dai un'occhiata alla certificazione PG di IIIT-B e upGrad in Machine Learning e Deep Learning, progettata per i professionisti che lavorano e offre oltre 240 ore di formazione rigorosa, oltre 5 casi di studio & incarichi, status di Alumni IIIT-B e assistenza al lavoro con le migliori aziende.