
Pengenalan Langsung untuk Validasi dan Regularisasi Model dalam Pembelajaran Mendalam menggunakan TensorFlow
Diterbitkan: 2020-10-28Daftar isi
pengantar
Praktik mesin untuk mengasimilasi informasi melalui paradigma algoritma pembelajaran yang diawasi telah merevolusi beberapa tugas seperti pembuatan urutan, pemrosesan bahasa alami, dan bahkan visi komputer. Pendekatan ini didasarkan pada pemanfaatan kumpulan data yang memiliki serangkaian fitur input dan serangkaian label yang sesuai. Mesin kemudian menggunakan informasi yang ada dalam bentuk fitur dan label untuk mempelajari distribusi dan pola data untuk membuat prediksi statistik pada input yang tidak terlihat.
Langkah terpenting dalam merancang model pembelajaran mendalam adalah mengevaluasi kinerja model, terutama pada titik data baru dan tidak terlihat. Tujuan utamanya adalah untuk mengembangkan model yang menggeneralisasi di luar data yang mereka latih. Kami menginginkan model yang dapat membuat prediksi yang baik dan dapat diandalkan di dunia nyata. Konsep penting yang membantu kita dalam hal ini adalah validasi dan regularisasi model yang akan kita bahas hari ini.
Validasi Model
Membangun model pembelajaran mesin selalu bermuara pada pemisahan data yang tersedia menjadi tiga set: pelatihan, validasi, dan set pengujian. Data pelatihan digunakan oleh model untuk mempelajari kebiasaan dan karakteristik distribusi.
Titik fokus yang perlu diketahui di sini adalah bahwa kinerja model yang memuaskan pada set pelatihan tidak berarti model juga akan menggeneralisasi data baru dengan kinerja serupa, ini karena model telah menjadi bias terhadap set pelatihan. Oleh karena itu, konsep validasi dan set pengujian digunakan untuk melaporkan seberapa baik model menggeneralisasi pada titik data baru.
Prosedur standarnya adalah menggunakan data pelatihan agar sesuai dengan model, mengevaluasi kinerja model menggunakan data validasi dan terakhir data uji digunakan untuk menilai seberapa baik model akan tampil pada contoh-contoh baru.
Set validasi digunakan untuk menyetel hyperparameter (jumlah hidden layer, learning rate, dropout rate, dll) sehingga model dapat digeneralisasi dengan baik. Teka-teki umum yang dihadapi oleh pemula pembelajaran mesin adalah memahami perlunya validasi dan set pengujian yang terpisah.

Kebutuhan untuk dua set yang berbeda dapat dipahami dengan intuisi berikut: untuk setiap jaringan saraf dalam yang perlu dirancang, terdapat beberapa jumlah hyperparameter yang perlu disesuaikan untuk kinerja yang memuaskan.
Beberapa model dapat dilatih menggunakan salah satu hiperparameter dan kemudian model dengan metrik kinerja terbaik dapat dipilih berdasarkan kinerja model tersebut pada set validasi. Sekarang, setiap kali hyperparameter di-tweak untuk kinerja yang lebih baik pada set validasi, beberapa informasi bocor/dimasukkan ke dalam model, oleh karena itu, bobot akhir jaringan saraf mungkin menjadi bias terhadap set validasi.
Setelah setiap penyesuaian hyperparameter, model kami terus berkinerja baik pada set validasi karena untuk itulah kami mengoptimalkannya. Inilah alasan mengapa uji validasi tidak dapat secara akurat menunjukkan kemampuan generalisasi model. Untuk mengatasi kelemahan ini, perangkat tes ikut bermain.
Representasi yang paling akurat dari kemampuan generalisasi model diberikan oleh kinerja pada set tes karena kami tidak mengoptimalkan model untuk kinerja yang lebih baik pada set ini dan karenanya, ini akan menunjukkan perkiraan paling pragmatis dari kemampuan model.
Harus Dibaca: Teknik Pembelajaran Mendalam Terbaik yang Harus Anda Ketahui
Menerapkan Strategi Validasi menggunakan TensorFlow 2.0
TensorFlow 2.0 menyediakan solusi yang sangat mudah untuk melacak kinerja model kami pada uji validasi yang terpisah. Kita dapat meneruskan argumen kata kunci validasi_split dalam metode model.fit() .
Kata kunci validasi_split mengambil input sebagai angka mengambang antara 0 & 1 yang mewakili sebagian kecil dari data pelatihan untuk digunakan sebagai data validasi. Jadi, melewati nilai 0,1 dalam kata kunci berarti menyisakan 10% dari data pelatihan untuk validasi.
Implementasi praktis dari validasi split dapat ditunjukkan dengan mudah menggunakan Dataset Diabetes dari sklearn. Dataset memiliki 442 kejadian dengan 10 variabel dasar (usia, jenis kelamin, BMI, dll.) sebagai fitur pelatihan dan ukuran perkembangan penyakit setelah satu tahun sebagai labelnya.
Kami mengimpor dataset menggunakan TensorFlow dan sklearn:

Langkah mendasar setelah pra-pemrosesan data adalah membangun jaringan saraf umpan maju sekuensial dengan lapisan padat:

Di sini, kami memiliki jaringan saraf dengan enam lapisan tersembunyi dengan aktivasi relu dan satu lapisan keluaran dengan aktivasi linier .
Kami kemudian mengkompilasi model dengan pengoptimal Adam dan fungsi kehilangan kesalahan kuadrat rata -rata.


Metode model.fit() kemudian digunakan untuk melatih model selama 100 epoch dengan validasi_split sebesar 15%.

Kami juga dapat memplot hilangnya model seperti yang diamati untuk data pelatihan dan data validasi:
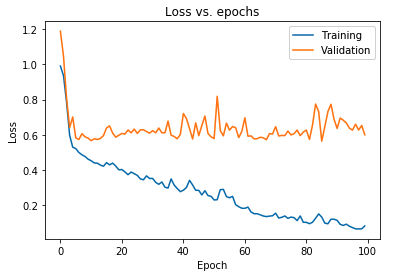
Plot yang ditampilkan di atas menunjukkan bahwa kehilangan validasi terus meningkat setelah 10 epoch sementara kehilangan pelatihan terus menurun. Tren ini adalah contoh buku teks dari masalah yang sangat signifikan dalam pembelajaran mesin yang disebut overfitting .
Banyak penelitian mani telah dilakukan untuk mengatasi masalah ini dan secara kolektif solusi ini disebut teknik regularisasi . Bagian berikut akan membahas aspek regularisasi dan prosedur untuk mengatur model deep learning apa pun.
Mengatur Model kami
Pada bagian sebelumnya kami mengamati tren sebaliknya dalam plot kerugian dari set pelatihan dan validasi di mana plot fungsi biaya dari set terakhir tampaknya naik dan set sebelumnya terus menurun dan karenanya, menciptakan kesenjangan ( generalization gap ). Pelajari lebih lanjut tentang regularisasi dalam machine learning.
Fakta bahwa ada kesenjangan antara dua plot kerugian melambangkan bahwa model tidak dapat menggeneralisasi dengan baik pada set validasi ( data yang tidak terlihat) dan karenanya nilai biaya/kerugian yang dikeluarkan pada set data tersebut juga pasti akan tinggi.
Keunikan ini terjadi karena bobot dan bias model yang dilatih beradaptasi untuk mempelajari distribusi data pelatihan dengan sangat baik, sehingga gagal memprediksi label fitur baru dan yang tidak terlihat yang menyebabkan peningkatan kehilangan validasi.
Alasannya adalah bahwa mengonfigurasi model yang kompleks akan menghasilkan anomali seperti itu karena parameter model tumbuh menjadi sangat kuat untuk data pelatihan. Oleh karena itu, menyederhanakan atau mengurangi kapasitas/kompleksitas model akan mengurangi efek overfitting. Salah satu cara untuk mencapai ini adalah dengan menggunakan putus sekolah dalam model pembelajaran mendalam kami yang akan kami bahas di bagian berikutnya.
Memahami dan Menerapkan Dropout di TensorFlow
Persepsi utama di balik penggunaan dropout adalah secara acak menjatuhkan unit tersembunyi dan terlihat untuk mendapatkan model yang tidak terlalu rumit yang membatasi parameter model agar tidak meningkat dan oleh karena itu, membuat model lebih kokoh untuk kinerja pada kumpulan data umum.
Praktik yang baru-baru ini diterima ini adalah pendekatan kuat yang digunakan oleh praktisi pembelajaran mesin untuk mendorong efek pengaturan dalam model pembelajaran mendalam apa pun. Dropout dapat diimplementasikan dengan mudah menggunakan Keras API melalui TensorFlow dengan mengimpor lapisan dropout dan meneruskan argumen rate di dalamnya untuk menentukan fraksi unit yang perlu dihapus.
Lapisan putus sekolah ini umumnya ditumpuk tepat setelah setiap lapisan padat untuk menghasilkan gelombang bolak-balik dari arsitektur lapisan putus padat .
Kami dapat memodifikasi jaringan saraf umpan maju yang telah ditentukan sebelumnya untuk memasukkan enam lapisan putus sekolah , satu untuk setiap lapisan tersembunyi:


Di sini, tingkat putus _ telah diatur ke 0,2 yang menandakan bahwa 20% dari node akan dijatuhkan saat melatih model. Kami mengkompilasi dan melatih model dengan pengoptimal, fungsi kerugian, metrik, dan jumlah epoch yang sama untuk membuat perbandingan yang adil.
Dampak utama dari regularisasi model menggunakan putus sekolah dapat diinterpretasikan dengan memplot kembali kurva kerugian model yang diperoleh pada set pelatihan dan validasi:
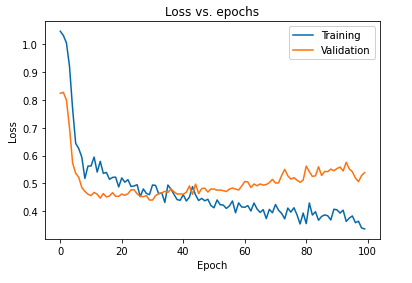
Hal ini terbukti dari plot di atas bahwa kesenjangan generalisasi yang diperoleh setelah regularisasi model jauh lebih sedikit yang membuat model kurang rentan terhadap overfit data pelatihan.
Baca Juga: Ide Proyek Pembelajaran Mendalam
Kesimpulan
Aspek validasi dan regularisasi model merupakan bagian penting dalam merancang alur kerja untuk membangun solusi pembelajaran mesin apa pun. Banyak penelitian sedang dilakukan untuk mengimprovisasi pembelajaran yang diawasi dan tutorial langsung ini memberikan wawasan singkat tentang beberapa praktik dan teknik yang paling diterima saat merakit algoritma pembelajaran apa pun.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang teknik pembelajaran mendalam , pembelajaran mesin, lihat Sertifikasi PG IIIT-B & upGrad dalam Pembelajaran Mesin & Pembelajaran Mendalam yang dirancang untuk profesional yang bekerja dan menawarkan 240+ jam pelatihan ketat, 5+ studi kasus & penugasan, status Alumni IIIT-B & bantuan pekerjaan dengan perusahaan papan atas.