
Introduction pratique à la validation et à la régularisation de modèles dans le Deep Learning à l'aide de TensorFlow
Publié: 2020-10-28Table des matières
introduction
La pratique des machines à assimiler l'information via le paradigme des algorithmes d'apprentissage supervisé a révolutionné plusieurs tâches comme la génération de séquences, le traitement du langage naturel et même la vision par ordinateur. Cette approche est basée sur l'utilisation d'un ensemble de données qui a un ensemble d'entités d'entrée et un ensemble correspondant d'étiquettes. La machine utilise ensuite ces informations présentes sous la forme de caractéristiques et d'étiquettes pour apprendre la distribution et les modèles des données afin de faire des prédictions statistiques sur des entrées invisibles.
Une étape primordiale dans la conception de modèles d'apprentissage en profondeur consiste à évaluer les performances du modèle, en particulier sur des points de données nouveaux et invisibles. L'objectif principal est de développer des modèles qui généralisent au-delà des données sur lesquelles ils ont été formés. Nous voulons des modèles capables de faire des prédictions bonnes et fiables dans le monde réel. Un concept important qui nous aide dans cette tâche est la validation et la régularisation du modèle que nous aborderons aujourd'hui.
Validation du modèle
Construire un modèle d'apprentissage automatique revient toujours à diviser les données disponibles en trois ensembles : formation, validation et ensemble de test. Les données d'apprentissage sont utilisées par le modèle pour apprendre les bizarreries et les caractéristiques de la distribution.
Un point central à savoir ici est qu'une performance satisfaisante du modèle sur l'ensemble d'apprentissage ne signifie pas que le modèle généralisera également sur de nouvelles données avec des performances similaires, c'est parce que le modèle est devenu biaisé par rapport à l'ensemble d'apprentissage. Le concept de validation et d'ensemble de test est donc utilisé pour indiquer dans quelle mesure le modèle se généralise sur de nouveaux points de données.
La procédure standard consiste à utiliser les données d'entraînement pour ajuster le modèle, à évaluer les performances du modèle à l'aide des données de validation et enfin les données de test sont utilisées pour évaluer les performances du modèle sur de nouveaux exemples.
L'ensemble de validation est utilisé pour ajuster les hyperparamètres (nombre de couches cachées, taux d'apprentissage, taux d'abandon, etc.) afin que le modèle puisse bien généraliser. Une énigme commune à laquelle sont confrontés les novices en apprentissage automatique est de comprendre la nécessité d'ensembles de validation et de test distincts.

La nécessité de deux ensembles distincts peut être comprise par l'intuition suivante : pour chaque réseau de neurones profonds qui doit être conçu, il existe plusieurs nombres d'hyperparamètres qui doivent être ajustés pour des performances satisfaisantes.
Plusieurs modèles peuvent être formés à l'aide de l'un des hyperparamètres, puis le modèle avec la meilleure métrique de performance peut être sélectionné en fonction des performances de ce modèle sur l'ensemble de validation. Maintenant, chaque fois que les hyperparamètres sont modifiés pour de meilleures performances sur l'ensemble de validation, certaines informations sont divulguées/alimentées dans le modèle, par conséquent, les poids finaux du réseau de neurones peuvent être biaisés en faveur de l'ensemble de validation.
Après chaque ajustement de l'hyperparamètre, notre modèle continue de bien fonctionner sur l'ensemble de validation car c'est pour cela que nous l'avons optimisé. C'est la raison pour laquelle le test de validation ne peut pas dénoter avec précision la capacité de généralisation du modèle. Pour pallier cet inconvénient, le jeu de test entre en jeu.
La représentation la plus précise de la capacité de généralisation d'un modèle est donnée par les performances sur l'ensemble de test car nous n'avons pas optimisé le modèle pour de meilleures performances sur cet ensemble et, par conséquent, cela indiquera l'estimation la plus pragmatique de la capacité du modèle.
Doit lire : Les meilleures techniques d'apprentissage en profondeur que vous devez connaître
Mettre en œuvre des stratégies de validation à l'aide de TensorFlow 2.0
TensorFlow 2.0 fournit une solution extrêmement simple pour suivre les performances de notre modèle lors d'un test de validation séparé. Nous pouvons passer l' argument du mot-clé validation_split dans la méthode model.fit() .
Le mot-clé validation_split prend en entrée un nombre flottant entre 0 et 1 qui représente la fraction des données d'apprentissage à utiliser comme données de validation. Ainsi, passer la valeur de 0,1 dans le mot-clé signifie réserver 10 % des données d'apprentissage pour la validation.
La mise en œuvre pratique de la division de validation peut être démontrée facilement à l'aide de l'ensemble de données sur le diabète de sklearn. L'ensemble de données comporte 442 instances avec 10 variables de base (âge, sexe, IMC, etc.) comme caractéristiques d'entraînement et la mesure de la progression de la maladie après un an comme étiquette.
Nous importons l'ensemble de données à l'aide de TensorFlow et sklearn :

L'étape fondamentale après le prétraitement des données consiste à construire un réseau de neurones séquentiel à anticipation avec des couches denses :

Ici, nous avons un réseau de neurones avec six couches cachées avec activation relu et une couche de sortie avec activation linéaire .

Nous compilons ensuite le modèle avec l' optimiseur Adam et la fonction de perte d'erreur quadratique moyenne .

La méthode model.fit() est ensuite utilisée pour entraîner le modèle pendant 100 époques avec un validation_split de 15 %.

Nous pouvons également tracer la perte du modèle telle qu'observée à la fois pour les données d'entraînement et les données de validation :
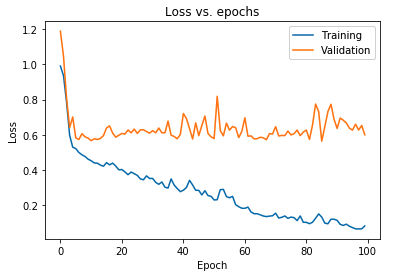
Le graphique affiché ci-dessus montre que la perte de validation augmente continuellement après 10 époques, tandis que la perte d'entraînement continue de diminuer. Cette tendance est un exemple classique d'un problème incroyablement important dans l'apprentissage automatique appelé surajustement .
De nombreuses recherches fondamentales ont été menées pour surmonter ce problème et, collectivement, ces solutions sont appelées techniques de régularisation . La section suivante couvrira l'aspect de la régularisation et la procédure de régularisation de tout modèle d'apprentissage en profondeur.
Régularisation de notre modèle
Dans la section précédente, nous avons observé une tendance inverse dans les tracés de perte des ensembles d'apprentissage et de validation où le tracé de la fonction de coût de ce dernier ensemble semble augmenter et celui du premier ensemble continue de diminuer, créant ainsi un écart ( écart de généralisation ). En savoir plus sur la régularisation dans l'apprentissage automatique.
Le fait qu'il existe un tel écart entre les deux diagrammes de perte symbolise que le modèle ne peut pas bien généraliser sur l'ensemble de validation ( données invisibles) et que, par conséquent, la valeur coût/perte encourue sur cet ensemble de données serait également inévitablement élevée.
Cette particularité se produit parce que les poids et les biais du modèle formé sont co-adaptés pour apprendre si bien la distribution des données de formation, qu'il ne parvient pas à prédire les étiquettes des fonctionnalités nouvelles et invisibles, ce qui entraîne une perte de validation accrue.
La logique est que la configuration d'un modèle complexe produira de telles anomalies puisque les paramètres des modèles deviennent très robustes pour les données d'apprentissage. Par conséquent, simplifier ou réduire la capacité/complexité des modèles réduira l'effet de surajustement. Une façon d'y parvenir consiste à utiliser les abandons dans notre modèle d'apprentissage en profondeur que nous aborderons dans la section suivante.
Comprendre et mettre en œuvre les abandons dans TensorFlow
La perception clé derrière l'utilisation des abandons est de supprimer au hasard des unités cachées et visibles afin d'obtenir un modèle moins complexe qui empêche les paramètres du modèle d'augmenter et, par conséquent, rend le modèle plus robuste pour les performances sur un ensemble de données généralisé.
Cette pratique récemment acceptée est une approche puissante utilisée par les praticiens de l'apprentissage automatique pour induire un effet de régularisation dans tout modèle d'apprentissage en profondeur. Les suppressions peuvent être implémentées sans effort à l'aide de l'API Keras sur TensorFlow en important la couche de suppression et en y transmettant l' argument de taux pour spécifier la fraction d'unités à supprimer.
Ces couches de décrochage sont généralement empilées juste après chaque couche dense pour produire une marée alternée d'une architecture de couche de décrochage dense .
Nous pouvons modifier notre réseau de neurones feedforward précédemment défini pour inclure six couches de suppression , une pour chaque couche cachée :


Ici, le taux d' abandon _ a été défini sur 0,2, ce qui signifie que 20 % des nœuds seront supprimés lors de la formation du modèle. Nous compilons et formons le modèle avec le même optimiseur, la fonction de perte, les métriques et le nombre d'époques pour faire une comparaison équitable.
L'impact principal de la régularisation du modèle à l'aide des abandons peut être interprété en traçant à nouveau la courbe de perte du modèle obtenu sur les ensembles d'apprentissage et de validation :
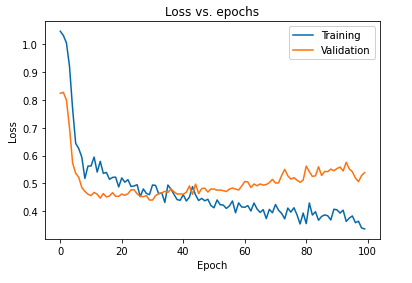
Il ressort du graphique ci-dessus que l'écart de généralisation obtenu après régularisation du modèle est bien moindre, ce qui rend le modèle moins susceptible de sur-ajuster les données d'apprentissage.
Lisez aussi : Idées de projets d'apprentissage en profondeur
Conclusion
L'aspect de la validation et de la régularisation du modèle est un élément essentiel de la conception du workflow de construction de toute solution d'apprentissage automatique. De nombreuses recherches sont menées afin d'improviser l'apprentissage supervisé et ce didacticiel pratique donne un bref aperçu de certaines des pratiques et techniques les plus acceptées lors de l'assemblage de tout algorithme d'apprentissage.
Si vous souhaitez en savoir plus sur les techniques d'apprentissage en profondeur , l'apprentissage automatique, consultez la certification PG d'IIIT-B et upGrad en apprentissage automatique et en apprentissage en profondeur, conçue pour les professionnels en activité et offrant plus de 240 heures de formation rigoureuse, plus de 5 études de cas. & affectations, statut IIIT-B Alumni & aide à l'emploi avec les meilleures entreprises.