
Analyse de données à l'aide de Python [Tout ce que vous devez savoir]
Publié: 2020-09-02Pour tous ceux qui veulent se lancer dans l'analyse de données, le premier langage qui vient à l'esprit est R ou Python. Et la raison pour laquelle les développeurs sont désormais plus enclins à Python est due à sa grande adaptabilité dans le domaine générique du développement logiciel. Par conséquent, l'analyse de données à l'aide de python est l'un des termes les plus entendus pour quelqu'un qui commence son voyage dans la science des données.
Table des matières
Pourquoi l'analyse des données ?
Tout d'abord, pourquoi l'analyse de données ? Eh bien, c'est la première étape pour savoir avec quel type de données vous travaillez. C'est l'étape où vous trouvez des modèles précieux dans les données, que vous ne verriez peut-être pas autrement. Dans l'ensemble, il fournit une compréhension intuitive de l'ensemble de données en main.
Ici, nous devons tracer une ligne entre l'analyse des données et le prétraitement des données. Le prétraitement des données traite de la modélisation de votre jeu de données pour s'assurer qu'il est prêt pour la formation. L'analyse des données consiste à comprendre l'ensemble de données, qui est une étape préalable au prétraitement des données. Dans l'analyse des données, nous essayons de modéliser les données pour mieux les visualiser et, par conséquent, obtenir des informations sur l'ensemble de données en main.
Pourquoi Python ?
La deuxième question est, pourquoi Python ? Eh bien, nous avons déjà déclaré que Python est un langage largement adapté. Oui, ce n'est pas le seul choix en matière d'analyse de données, mais c'est un très bon choix. Une autre raison est qu'il est plus utilisé ! Python est simple et dispose d'une grande communauté de développeurs pour vous aider concernant l'analyse de données à l'aide de python . De plus, l'analyse de données à l'aide de Python est assez agréable en raison du grand nombre de bibliothèques créatives qu'il propose pour l'analyse et la visualisation de données.
En Python, la bibliothèque de base pour l'analyse des données est Pandas. Il s'agit d'une bibliothèque de haut niveau, construite sur la bibliothèque NumPy, qui est destinée au calcul scientifique et à l'analyse numérique. Les pandas facilitent le travail avec les données en proposant leur structure de données, connue sous le nom de DataFrame. DataFrame aide à lire et à stocker votre ensemble de données. Il fournit les fonctions de base pour la lecture et l'écriture de l'ensemble de données, ainsi que l'affichage des métadonnées et des fonctions d'interrogation pour extraire toutes les informations de l'ensemble de données.
Il est important de noter que la visualisation des données est une partie considérable de l'analyse globale des données. Parce que cela aide non seulement à mieux comprendre les données vous-même, mais aussi à ceux à qui vous fournissez les informations. Nous discuterions des deux bibliothèques les plus utilisées pour la visualisation : Matplotlib et Seaborn. Matplotlib est la bibliothèque de base pour toutes les visualisations en Python. Seaborn est également conçu sur Matplotlib, qui offre certaines des fonctions de visualisation de données les plus créatives.
Configurer l'environnement
La première étape consiste à configurer votre environnement. Lors de l'analyse de données à l'aide de python , il est important de disposer d'un environnement approprié pour conserver tout votre travail. L'analyse de données à l'aide de python ne sera pas simplement un script, mais ce sera une interaction de vous-même avec l'ensemble de données, et pour cela, vous avez besoin d'un lieu de travail approprié.
En python, ce service est fourni par la distribution Anaconda. Le principal lieu de travail d'Anaconda est le bloc-notes Jupyter. Alors, maintenant pourquoi Jupyter ? Eh bien, cela vous permet d'avoir les visualisations directement dans votre ordinateur portable. Il a également des fonctions magiques qui vous permettent de voir directement la sortie sans indiquer explicitement où vous la voulez.
Les bibliothèques, Pandas et Matplotlib, sont préinstallées et, par conséquent, aucune configuration supplémentaire n'est requise pour les utiliser.
Voici le synopsis de la façon de se déplacer dans l'analyse de données à l'aide de Python :
- Chargement du jeu de données
- Affichage des métadonnées du jeu de données à l'aide de Pandas
- Visualisations de données avec Matplotlib
- Recueillir des informations sur les données
Importer les bibliothèques nécessaires
Avant de commencer à examiner le code pour les étapes, importez simplement les bibliothèques nécessaires avec des pseudo-balises, comme avec le nom que nous les appellerions pour l'ensemble du programme.
importer numpy en tant que np
importer des pandas en tant que pd
# pour les visualisations de données
importer matplotlib.pyplot en tant que plt
importer seaborn en tant que sns
Nous allons maintenant examiner chaque étape et discuter des fonctions disponibles et de la manière de les utiliser.
Tout d'abord, lire des ensembles de données. Les pandas fournissent quelques fonctions de base pour charger l'ensemble de données dans sa structure de données de base : DataFrame. Nous pouvons l'utiliser comme suit.
data_df = pd.read_csv('coeur.csv')
La sortie de toute fonction de lecture sera un DataFrame. Outre les lecteurs CSV, les pandas fournissent des lecteurs pour presque tous les types de données. De HTML à JSON et excel.
En dehors de cela, si vous n'avez pas de données en tant que telles et que vous souhaitez créer votre jeu de données, vous pouvez facilement utiliser les fonctions d'objet Series et DataFrame de Pandas.
Donc, une fois que vous avez les données en main, passons à la visualisation de quoi il s'agit. Pour obtenir la première vue des données, vous pouvez utiliser des fonctions telles que df.info ou df.describe pour connaître la structure de votre jeu de données.
data_df.info()
data_df.describe()
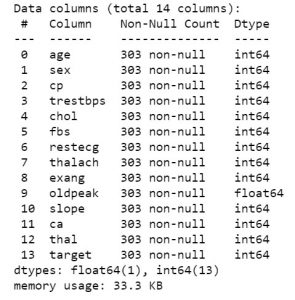
Une fois que vous savez quelles caractéristiques contient votre jeu de données, vous voudrez peut-être en examiner les valeurs. Vous pouvez utiliser la fonction df.head() pour obtenir les 5 premiers échantillons.
data_df.head()
#ou
data_df.head(3)
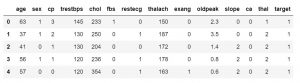
Vous pouvez également spécifier le nombre d'échantillons pour remplacer la valeur par défaut de 5. Vous pouvez également utiliser la fonction df.tail() pour obtenir les 5 dernières valeurs de l'ensemble de données.
data_df.tail()
Il s'agit simplement d'obtenir un aperçu de haut niveau de ce à quoi vos données pourraient ressembler. Une fois prêt, vous pouvez démarrer les principales tâches de visualisation de données, en utilisant Matplotlib. Tapez le code suivant pour rendre le traçage interactif et afficher le même dans votre bloc-notes lui-même.
%matplotlib en ligne
Nous verrions les fonctionnalités des 5 meilleures visualisations dans matplotlib. Avant d'y entrer, nous devons connaître quelques autres fonctions qui contrôlent nos parcelles. Les fonctions comme :
- Libellés : xlabel(), ylabel(). Ils sont pour les étiquettes de l'axe des x et de l'axe des y.
- Légende : Il est utilisé pour créer la légende de l'intrigue.
- Titre : Pour attribuer un titre à votre tracé
- Et enfin, afficher la fonction pour afficher l'intrigue.
Checkout: Salaire d'analyste de données en Inde
Visualisations
Voyons maintenant les visualisations. Nous commencerions par l'intrigue de base. Le plt.plot() est utilisé pour générer un simple tracé linéaire pour vos données. La fonction nécessite deux paramètres en compulsion, et ce sont des données d'axe x et des données d'axe y. Vous pouvez éventuellement fournir les styles, le nom et la couleur du tracé. Voici à quoi cela ressemble dans le code.
plt.plot(data_df['chol'])
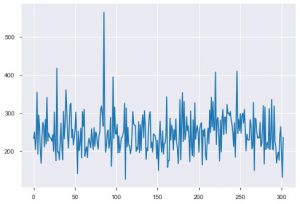
Le deuxième graphique est l'histogramme. Un histogramme vous aide à visualiser la fréquence ou la distribution d'une caractéristique particulière. Il vous aide à voir comment les quantités sont liées les unes aux autres. Plt.hist() est la fonction de base pour créer un histogramme sur vos données. Vous pouvez mentionner le paramètre bins pour contrôler le nombre sur le tracé. Vous n'avez besoin de transmettre qu'une seule donnée d'axe si vous souhaitez une analyse univariée.
plt.hist(data_df['âge'])
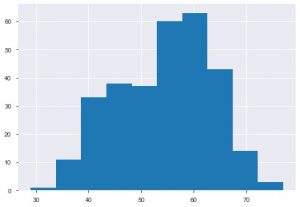

Un autre graphique que vous verriez souvent est le graphique à barres. Il aide à analyser et à comparer différentes fonctionnalités. Contrairement aux histogrammes, les diagrammes à barres sont utilisés pour travailler avec des données catégorielles.
Vous pouvez appliquer directement le tracé sur le DataFrame, ou vous pouvez spécifier les paramètres dans la fonction plt.bar(). Voici comment nous l'utilisons.
df = pd.DataFrame(np.random.rand(15, 5), colonnes=['t1', 't2', 't3', 't4', 't5'])
df.plot.bar()
Vous pouvez également utiliser le diagramme à barres horizontalement en utilisant la fonction barh().
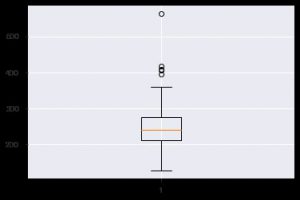
Un autre graphique perspicace est le boxplot. Cela aide à comprendre la distribution des valeurs au sein de chaque fonctionnalité. Vous pouvez utiliser la fonction plt.boxplot() pour spécifier les données sur lesquelles vous souhaitez générer un boxplot. Le tracé est particulièrement utile lorsque vous devez afficher rapidement la dispersion dans le jeu de données ou l'asymétrie. Voici comment vous pouvez l'utiliser.
plt.boxplot(data_df['chol'])
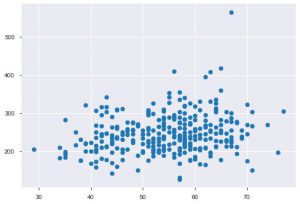
Chaque fois que vous travaillez avec des données statistiques, vous verrez certainement un nuage de points. Un nuage de points aide à observer la relation entre deux caractéristiques. Le tracé nécessite des valeurs numériques pour les données de l'axe des x ainsi que pour l'axe des y. Vous pouvez simplement fournir ces deux valeurs dans la fonction plt.scatter() ou vous pouvez les appliquer directement sur le DataFrame en spécifiant les noms de colonne dans les attributs x et y. Voici comment vous pouvez l'utiliser :
plt.scatter(data_df['age'], data_df['chol'])
Le moment est venu de vous présenter les fonctions de Seaborn. Le nuage de points dans seaborn est plus intuitif que le matplotlib car il fournit également par défaut une ligne de régression dans le tracé, pour mieux visualiser le tracé. Vous pouvez utiliser la fonction sns.lmplot() pour créer ce tracé.
sns.lmplot('age', 'chol', data=data_df)
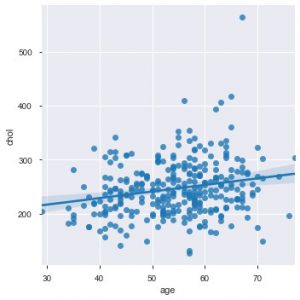
Comme vous pouvez le voir dans le graphique ci-dessus, la droite de régression permet de mieux comprendre la distribution.
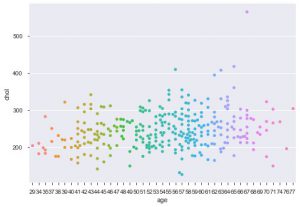
Une autre amélioration utilisant Seaborn est le diagramme en essaim. Il est utilisé pour dessiner un nuage de points catégoriel. L'un des avantages du tracé en essaim par rapport au tracé en bande similaire est qu'il utilise uniquement les points qui ne se chevauchent pas. C'est donc une intrigue plus propre et donne donc un meilleur aperçu.
sns.swarmplot(data_df['age'], data_df['chol'])
Voici donc les différents types de parcelles dans Matplotlib et Seaborn. Ce n'est que la pointe de l'iceberg, et il existe des centaines d'autres façons différentes de tracer vos données pour en extraire des informations créatives.
Maintenant que vous connaissez les tracés, voyons comment effectuer une analyse de données réelle à l'aide de python . Nous examinerions d'autres graphiques et verrions ce qu'ils nous montrent sur l'analyse des données à l'aide de python .
Commençons.
Après avoir chargé les données, la première chose que tout analyste de données fait maintenant est de créer un profil pandas. Maintenant, cela peut également être considéré comme un raccourci, mais si vous voulez voir toutes les relations, les décomptes et les histogrammes des variables dans l'ensemble de données, vous pouvez utiliser le profilage pandas. Il est très facile à générer, il suffit de télécharger le module pandas-profiling et de saisir le code suivant :
importer pandas_profiling
profile = pandas_profiling.ProfileReport(data_df)
profil
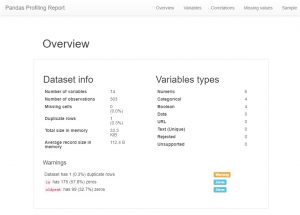
Comme vous pourrez le voir, il existe une énorme quantité d'informations sur les métadonnées et également des informations sur les fonctionnalités individuelles. Ceux-ci pourraient conduire à une grande compréhension.
La deuxième chose que nous pouvons faire est de générer une carte thermique. Maintenant, ce que fait une carte thermique, c'est qu'elle montre la corrélation de chaque fonctionnalité avec l'autre. Et si nous trouvons une valeur avec une corrélation plus élevée, cela signifie que les deux caractéristiques se ressemblent étroitement. Donc, nous pouvons laisser tomber l'une des fonctionnalités, et pourtant, le modèle fonctionnera bien.
sns.heatmap(data_df.corr(), annot = True , cmap='Oranges')
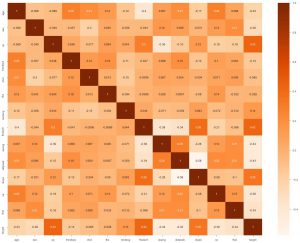
Ici, nous pouvons voir qu'aucune n'est très liée, nous pouvons donc dire à l'ingénieur modèle que nous aurions besoin de toutes les fonctionnalités en entrée.
Nous pouvons voir quelle est la répartition par âge parce que nous traitons de l'ensemble de données sur les maladies cardiaques, voyons la répartition, afin que nous puissions utiliser le diagramme de distribution de seaborn.
sns.distplot(data_df['age'], color = 'cyan')
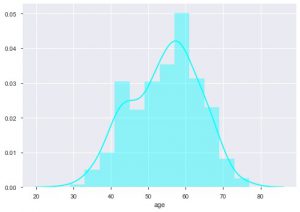
D'après l'intrigue, vous pouvez dire que la plupart des personnes souffrant de maladies cardiaques ont entre 50 et 60 ans. De la même manière, nous pouvons également voir d'autres caractéristiques importantes comme la pression artérielle au repos, qui est désignée par tresbps. Nous pouvons faire une boîte à moustaches pour voir la distribution, par rapport à la valeur cible, c'est-à-dire 0 et 1.
sns.boxplot(data_df['target'], data_df['trestbps'], palette = 'twilight')
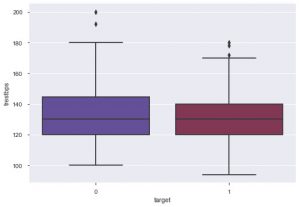
Nous pouvons conclure de l'intrigue que si la personne a un tres bps inférieur, alors les chances qu'elle souffre d'une maladie cardiaque sont plus faibles que celles avec une valeur tres bps plus élevée.
De la même manière, nous pouvons également voir la relation avec le taux de cholestérol. Nous constatons que les personnes ayant un taux de cholestérol inférieur ont moins de risques de souffrir d'une maladie cardiaque.
Vous pouvez documenter toutes ces informations et les fournir à l'ingénieur en apprentissage automatique qui peut ensuite les utiliser pour créer un modèle efficace.
Conclusion
Donc, voici comment vous pouvez effectuer une analyse de données en utilisant python . Ce n'est que la première étape du parcours de la science des données. Pour en savoir plus sur l'extraction d'idées créatives à partir de données et sur la science globale des données, dirigez-vous vers les cours proposés par upGrad ici . Vous trouverez un éventail de cours utiles qui guideront efficacement l'analyse des données à l'aide de Python.
Apprenez des cours de science des données dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
Comment dois-je apprendre Python pour l'analyse de données ?
Si vous êtes sur le point d'apprendre Python pour l'analyse de données, vous êtes au bon endroit. Vous devez avoir une approche étape par étape pour simplifier le processus d'apprentissage pour tout. Voici à quoi ressemble le processus :
1. Soyez clair dans le but d'apprendre Python et comment vous pourrez l'utiliser dans votre domaine.
2.Téléchargez le terminal Python requis et installez-le sur votre système.
3.Commencez à apprendre les bases de Python en suivant différents cours et en vous familiarisant avec les différentes bibliothèques Python.
4. Familiarisez-vous avec les expressions régulières utilisées en Python.
5. Optez pour une connaissance approfondie des différentes bibliothèques Python telles que Pandas, NumPy, Matplotlib et SciPy.
6. Commencez à apprendre les concepts d'analyse de données et comment vous pouvez y intégrer Python.
7. Maintenant, il vous suffit de continuer à pratiquer différents outils et techniques pour vous améliorer en Python pour l'analyse de données. En suivant cette approche étape par étape, vous trouverez assez facile d'apprendre Python et de vous améliorer pour travailler avec l'analyse de données.
Comment Python est-il utilisé pour l'analyse de données ?
Python est connu pour être une ressource très importante pour l'analyse des données. Python aide de différentes manières à effectuer l'analyse des données. Mais avant cela, vous devez préparer les données pour l'analyse, effectuer une analyse statistique, créer des visualisations de données qui pourraient fournir des informations, prédire les tendances futures en fonction des données disponibles, et bien plus encore.
Python s'avère être un élément crucial de l'analyse des données car il aide à :
1. Importation de jeux de données
2.Nettoyage et préparation des données pour effectuer l'analyse
3. Manipulation du DataFrame Pandas
4. Résumer les ensembles de données
5. Développer un modèle d'apprentissage automatique pour l'analyse de données avec Python
Puis-je apprendre Python en un mois ?
Oui, vous pouvez certainement y arriver si vous maîtrisez d'autres langages de programmation comme Java, C, C++, etc. Si votre base est claire, vous trouverez assez facile d'apprendre Python même en un seul mois. En dehors de cela, si vous faites des efforts et suivez une approche étape par étape de manière disciplinée, vous pouvez apprendre Python en un mois même si vous n'avez aucune connaissance préalable des autres langages de programmation. Il vous suffit de définir un calendrier et de vous consacrer à l'apprentissage de Python en un mois.