
Introducción práctica a la validación y regularización de modelos en aprendizaje profundo con TensorFlow
Publicado: 2020-10-28Tabla de contenido
Introducción
La práctica de las máquinas para asimilar información a través del paradigma de los algoritmos de aprendizaje supervisado ha revolucionado varias tareas como la generación de secuencias, el procesamiento del lenguaje natural e incluso la visión artificial. Este enfoque se basa en utilizar un conjunto de datos que tiene un conjunto de características de entrada y un conjunto de etiquetas correspondiente. Luego, la máquina usa esta información presente en forma de características y etiquetas para aprender la distribución y los patrones de los datos para hacer predicciones estadísticas sobre entradas no vistas.
Un paso primordial en el diseño de modelos de aprendizaje profundo es evaluar el rendimiento del modelo, especialmente en puntos de datos nuevos e invisibles. El objetivo clave es desarrollar modelos que generalicen más allá de los datos en los que fueron entrenados. Queremos modelos que puedan hacer predicciones buenas y confiables en el mundo real. Un concepto importante que nos ayuda con esto es la validación y regularización del modelo que trataremos hoy.
Modelo de validación
La creación de un modelo de aprendizaje automático siempre se reduce a dividir los datos disponibles en tres conjuntos: entrenamiento, validación y conjunto de prueba. El modelo utiliza los datos de entrenamiento para aprender las peculiaridades y características de la distribución.
Un punto focal que debe saber aquí es que un rendimiento satisfactorio del modelo en el conjunto de entrenamiento no significa que el modelo también generalizará en datos nuevos con un rendimiento similar, esto se debe a que el modelo se ha sesgado hacia el conjunto de entrenamiento. Por lo tanto, el concepto de conjunto de validación y prueba se utiliza para informar qué tan bien el modelo generaliza nuevos puntos de datos.
El procedimiento estándar es usar los datos de entrenamiento para ajustar el modelo, evaluar el rendimiento del modelo usando los datos de validación y, finalmente, los datos de prueba se usan para evaluar qué tan bien funcionará el modelo en ejemplos totalmente nuevos.
El conjunto de validación se utiliza para ajustar los hiperparámetros (número de capas ocultas, tasa de aprendizaje, tasa de abandono, etc.) para que el modelo pueda generalizarse bien. Un enigma común que enfrentan los novatos en aprendizaje automático es comprender la necesidad de conjuntos de validación y prueba separados.

La necesidad de dos conjuntos distintos puede entenderse por la siguiente intuición: por cada red neuronal profunda que necesita diseñarse, existe una cantidad múltiple de hiperparámetros que deben ajustarse para un rendimiento satisfactorio.
Se pueden entrenar varios modelos utilizando cualquiera de los hiperparámetros y luego se puede seleccionar el modelo con la mejor métrica de rendimiento en función del rendimiento de ese modelo en el conjunto de validación. Ahora, cada vez que los hiperparámetros se ajustan para un mejor rendimiento en el conjunto de validación, se filtra/alimenta cierta información al modelo, por lo tanto, los pesos finales de la red neuronal pueden verse sesgados hacia el conjunto de validación.
Después de cada ajuste del hiperparámetro, nuestro modelo continúa funcionando bien en el conjunto de validación porque para eso lo optimizamos. Esta es la razón por la que la prueba de validación no puede denotar con precisión la capacidad de generalización del modelo. Para superar este inconveniente, entra en juego el conjunto de prueba.
La representación más precisa de la capacidad de generalización de un modelo viene dada por el rendimiento en el conjunto de prueba, ya que no optimizamos el modelo para un mejor rendimiento en este conjunto y, por lo tanto, esto indicará la estimación más pragmática de la capacidad del modelo.
Debe leer: Las principales técnicas de aprendizaje profundo que debe conocer
Implementación de estrategias de validación con TensorFlow 2.0
TensorFlow 2.0 proporciona una solución extremadamente sencilla para realizar un seguimiento del rendimiento de nuestro modelo en una prueba de validación independiente. Podemos pasar el argumento de la palabra clave validation_split en el método model.fit() .
La palabra clave validation_split toma la entrada como un número flotante entre 0 y 1 que representa la fracción de datos de entrenamiento que se usará como datos de validación. Entonces, pasar el valor de 0.1 en la palabra clave significa reservar el 10% de los datos de entrenamiento para la validación.
La implementación práctica de la división de validación se puede demostrar fácilmente utilizando el conjunto de datos de diabetes de sklearn. El conjunto de datos tiene 442 instancias con 10 variables de referencia (edad, sexo, IMC, etc.) como características de entrenamiento y la medida de progresión de la enfermedad después de un año como su etiqueta.
Importamos el conjunto de datos usando TensorFlow y sklearn:

El paso fundamental después del preprocesamiento de datos es construir una red neuronal feedforward secuencial con capas densas:

Aquí tenemos una red neuronal con seis capas ocultas con activación relu y una capa de salida con activación lineal .
Luego compilamos el modelo con el optimizador de Adam y la función de pérdida de error cuadrático medio .


Luego, se usa el método model.fit() para entrenar el modelo durante 100 épocas con una división de validación del 15 %.

También podemos trazar la pérdida del modelo como se observa tanto para los datos de entrenamiento como para los datos de validación:
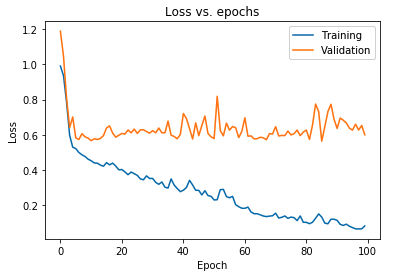
El gráfico que se muestra arriba muestra que la pérdida de validación aumenta continuamente después de 10 épocas, mientras que la pérdida de entrenamiento continúa disminuyendo. Esta tendencia es un ejemplo de libro de texto de un problema increíblemente significativo en el aprendizaje automático que se llama sobreajuste .
Se ha llevado a cabo una gran cantidad de investigación fundamental para superar este problema y, en conjunto, estas soluciones se denominan técnicas de regularización . La siguiente sección cubrirá el aspecto de la regularización y el procedimiento para regularizar cualquier modelo de aprendizaje profundo.
Regularizando nuestro Modelo
En la sección anterior observamos una tendencia inversa en los gráficos de pérdida de los conjuntos de entrenamiento y validación donde el gráfico de la función de costo del último conjunto parece aumentar y el del primero continúa disminuyendo y, por lo tanto, creando una brecha ( brecha de generalización ). Obtenga más información sobre la regularización en el aprendizaje automático.
El hecho de que exista tal brecha entre las dos gráficas de pérdida simboliza que el modelo no puede generalizarse bien en el conjunto de validación ( datos no vistos) y, por lo tanto, el valor de costo/pérdida incurrido en ese conjunto de datos también sería inevitablemente alto.
Esta peculiaridad se debe a que los pesos y sesgos del modelo entrenado se coadaptan para aprender tan bien la distribución de los datos de entrenamiento que no puede predecir las etiquetas de características nuevas e invisibles, lo que lleva a una mayor pérdida de validación.
La razón es que la configuración de un modelo complejo producirá tales anomalías, ya que los parámetros de los modelos crecen hasta volverse muy robustos para los datos de entrenamiento. Por lo tanto, simplificar o reducir la capacidad/complejidad de los modelos reducirá el efecto de sobreajuste. Una forma de lograr esto es mediante el uso de abandonos en nuestro modelo de aprendizaje profundo que trataremos en la siguiente sección.
Comprensión e implementación de abandonos en TensorFlow
La percepción clave detrás del uso de abandonos es descartar aleatoriamente unidades ocultas y visibles para obtener un modelo menos complejo que restringe el aumento de los parámetros del modelo y, por lo tanto, hace que el modelo sea más sólido para el rendimiento en un conjunto de datos generalizado.
Esta práctica recientemente aceptada es un enfoque poderoso utilizado por los profesionales del aprendizaje automático para inducir un efecto de regularización en cualquier modelo de aprendizaje profundo. Los abandonos se pueden implementar sin esfuerzo usando la API de Keras sobre TensorFlow importando la capa de abandono y pasando el argumento de tasa en ella para especificar la fracción de unidades que deben eliminarse.
Estas capas de abandono generalmente se apilan justo después de cada capa densa para producir una marea alterna de una arquitectura de capa de abandono densa .
Podemos modificar nuestra red neuronal feedforward previamente definida para incluir seis capas de abandono , una para cada capa oculta:


Aquí, la tasa de abandono _ se ha establecido en 0,2, lo que significa que el 20 % de los nodos se eliminarán mientras se entrena el modelo. Compilamos y entrenamos el modelo con el mismo optimizador, función de pérdida, métricas y el número de épocas para hacer una comparación justa.
El impacto principal de regularizar el modelo utilizando abandonos se puede interpretar trazando nuevamente la curva de pérdida del modelo obtenido en los conjuntos de entrenamiento y validación:
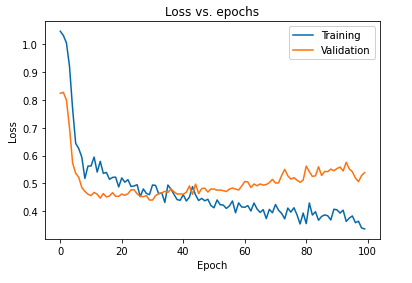
Es evidente a partir del gráfico anterior que la brecha de generalización obtenida después de regularizar el modelo es mucho menor, lo que hace que el modelo sea menos susceptible de sobreajustar los datos de entrenamiento.
Lea también: Ideas de proyectos de aprendizaje profundo
Conclusión
El aspecto de la validación y regularización del modelo es una parte esencial del diseño del flujo de trabajo para construir cualquier solución de aprendizaje automático. Se están realizando muchas investigaciones para improvisar el aprendizaje supervisado y este tutorial práctico proporciona una breve perspectiva de algunas de las prácticas y técnicas más aceptadas al ensamblar cualquier algoritmo de aprendizaje.
Si está interesado en obtener más información sobre técnicas de aprendizaje profundo , aprendizaje automático, consulte la certificación PG de IIIT-B y upGrad en aprendizaje automático y aprendizaje profundo, que está diseñada para profesionales que trabajan y ofrece más de 240 horas de capacitación rigurosa, más de 5 estudios de casos y asignaciones, estado de ex alumnos de IIIT-B y asistencia laboral con las mejores empresas.