
Praktische Einführung in die Modellvalidierung und Regularisierung im Deep Learning mit TensorFlow
Veröffentlicht: 2020-10-28Inhaltsverzeichnis
Einführung
Die Praxis von Maschinen, Informationen über das Paradigma überwachter Lernalgorithmen zu assimilieren, hat mehrere Aufgaben wie die Sequenzgenerierung, die Verarbeitung natürlicher Sprache und sogar Computer Vision revolutioniert. Dieser Ansatz basiert auf der Verwendung eines Datensatzes, der einen Satz von Eingabemerkmalen und einen entsprechenden Satz von Beschriftungen aufweist. Die Maschine verwendet dann diese in Form von Merkmalen und Bezeichnungen vorhandenen Informationen, um die Verteilung und Muster der Daten zu lernen, um statistische Vorhersagen über unsichtbare Eingaben zu treffen.
Ein wichtiger Schritt beim Entwerfen von Deep-Learning-Modellen ist die Bewertung der Modellleistung, insbesondere bei neuen und unsichtbaren Datenpunkten. Das Hauptziel besteht darin, Modelle zu entwickeln, die über die Daten hinaus verallgemeinern, mit denen sie trainiert wurden. Wir wollen Modelle, die in der realen Welt gute und verlässliche Vorhersagen treffen können. Ein wichtiges Konzept, das uns dabei hilft, ist die Modellvalidierung und -regularisierung, die wir heute behandeln werden.
Modell Bestätigung
Das Erstellen eines Modells für maschinelles Lernen läuft immer darauf hinaus, die verfügbaren Daten in drei Sätze aufzuteilen: Training, Validierung und Testsatz. Die Trainingsdaten werden vom Modell verwendet, um die Macken und Eigenschaften der Verteilung zu lernen.
Ein wichtiger Punkt, der hier zu wissen ist, ist, dass eine zufriedenstellende Leistung des Modells im Trainingssatz nicht bedeutet, dass das Modell auch auf neue Daten mit ähnlicher Leistung generalisiert, da das Modell gegenüber dem Trainingssatz verzerrt ist. Das Konzept der Validierung und des Testsatzes wird daher verwendet, um zu berichten, wie gut das Modell auf neue Datenpunkte generalisiert.
Das Standardverfahren besteht darin, die Trainingsdaten zu verwenden, um das Modell anzupassen, die Modellleistung anhand der Validierungsdaten zu bewerten und schließlich die Testdaten zu verwenden, um festzustellen, wie gut das Modell bei völlig neuen Beispielen abschneiden wird.
Das Validierungsset wird verwendet, um die Hyperparameter (Anzahl der verborgenen Schichten, Lernrate, Dropout-Rate usw.) so abzustimmen , dass das Modell gut verallgemeinern kann. Ein häufiges Rätsel, mit dem Anfänger im maschinellen Lernen konfrontiert sind, ist das Verständnis der Notwendigkeit separater Validierungs- und Testsätze.

Die Notwendigkeit von zwei unterschiedlichen Sätzen kann durch die folgende Intuition verstanden werden: Für jedes tiefe neuronale Netzwerk, das entworfen werden muss, gibt es eine Vielzahl von Hyperparametern, die für eine zufriedenstellende Leistung angepasst werden müssen.
Mehrere Modelle können mit einem der Hyperparameter trainiert werden, und dann kann das Modell mit der besten Leistungsmetrik basierend auf der Leistung dieses Modells im Validierungssatz ausgewählt werden. Jedes Mal, wenn die Hyperparameter für eine bessere Leistung im Validierungssatz optimiert werden, werden einige Informationen in das Modell eingespeist/eingesickert , daher können die endgültigen Gewichtungen des neuronalen Netzwerks in Richtung des Validierungssatzes verzerrt werden.
Nach jeder Anpassung des Hyperparameters schneidet unser Modell auf dem Validierungssatz weiterhin gut ab, weil wir es dafür optimiert haben. Aus diesem Grund kann der Validierungstest die Verallgemeinerungsfähigkeit des Modells nicht genau bezeichnen. Um diesen Nachteil zu überwinden, kommt das Testset ins Spiel.
Die genaueste Darstellung der Verallgemeinerungsfähigkeit eines Modells wird durch die Leistung auf dem Testsatz gegeben, da wir das Modell nicht für eine bessere Leistung auf diesem Satz optimiert haben, und daher wird dies die pragmatischste Schätzung der Fähigkeit des Modells anzeigen.
Muss gelesen werden: Die besten Deep-Learning-Techniken, die Sie kennen sollten
Implementierung von Validierungsstrategien mit TensorFlow 2.0
TensorFlow 2.0 bietet eine extrem einfache Lösung, um die Leistung unseres Modells in einem separaten, ausgehaltenen Validierungstest zu verfolgen. Wir können das Schlüsselwort-Argument „ validation_split “ in der Methode „model.fit() “ übergeben .
Das Schlüsselwort „ validation_split “ akzeptiert eine Eingabe als Fließkommazahl zwischen 0 und 1 , die den Bruchteil der Trainingsdaten darstellt, die als Validierungsdaten verwendet werden sollen. Das Übergeben des Werts 0,1 im Schlüsselwort bedeutet also, dass 10 % der Trainingsdaten für die Validierung reserviert werden.
Die praktische Umsetzung des Validierungssplits lässt sich einfach anhand des Diabetes -Datensatzes von sklearn demonstrieren. Der Datensatz hat 442 Instanzen mit 10 Baseline-Variablen (Alter, Geschlecht, BMI usw.) als Trainingsmerkmale und das Maß der Krankheitsprogression nach einem Jahr als Bezeichnung.
Wir importieren den Datensatz mit TensorFlow und sklearn:

Der grundlegende Schritt nach der Datenvorverarbeitung besteht darin, ein sequentielles neuronales Feedforward-Netzwerk mit dichten Schichten aufzubauen:

Hier haben wir ein neuronales Netzwerk mit sechs verborgenen Schichten mit Relu- Aktivierung und einer Ausgabeschicht mit linearer Aktivierung.
Wir kompilieren dann das Modell mit dem Adam - Optimierer und der mittleren quadratischen Fehlerverlustfunktion .


Die Methode model.fit() wird dann verwendet, um das Modell für 100 Epochen mit einer Validierungssplit von 15 % zu trainieren.

Wir können auch den Verlust des Modells darstellen, wie er sowohl für die Trainingsdaten als auch für die Validierungsdaten beobachtet wurde:
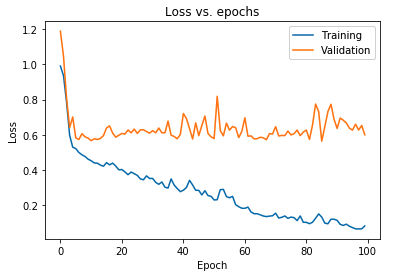
Das oben angezeigte Diagramm zeigt, dass der Validierungsverlust nach 10 Epochen kontinuierlich ansteigt, während der Trainingsverlust weiter abnimmt. Dieser Trend ist ein Lehrbuchbeispiel für ein unglaublich wichtiges Problem beim maschinellen Lernen, das als Overfitting bezeichnet wird .
Um dieses Problem zu lösen, wurde viel bahnbrechende Forschung betrieben, und zusammenfassend werden diese Lösungen als Regularisierungstechniken bezeichnet . Der folgende Abschnitt behandelt den Aspekt der Regularisierung und das Verfahren zur Regularisierung eines beliebigen Deep-Learning-Modells.
Regularisierung unseres Modells
Im vorherigen Abschnitt haben wir einen umgekehrten Trend in den Verlustdiagrammen der Trainings- und Validierungssätze beobachtet, bei denen das Kostenfunktionsdiagramm des letzteren Satzes zu steigen scheint und der des ersteren Satzes weiter abnimmt und somit eine Lücke ( Generalisierungslücke ) erzeugt. Erfahren Sie mehr über die Regularisierung beim maschinellen Lernen.
Die Tatsache, dass zwischen den beiden Verlustdiagrammen eine solche Lücke besteht, symbolisiert, dass das Modell auf dem Validierungssatz ( nicht sichtbare Daten) nicht gut verallgemeinern kann und daher der Kosten-/Verlustwert, der bei diesem Datensatz anfällt, ebenfalls unvermeidlich hoch wäre.
Diese Besonderheit tritt auf, weil die Gewichtungen und Vorspannungen des trainierten Modells koadaptiert werden, um die Verteilung der Trainingsdaten so gut zu lernen, dass es die Labels neuer und unsichtbarer Merkmale nicht vorhersagen kann, was zu einem erhöhten Validierungsverlust führt.
Der Grund dafür ist, dass das Konfigurieren eines komplexen Modells solche Anomalien erzeugt, da die Modellparameter wachsen, um für die Trainingsdaten sehr robust zu werden. Daher reduziert eine Vereinfachung oder Verringerung der Kapazität/Komplexität des Modells den Overfitting-Effekt. Eine Möglichkeit, dies zu erreichen, ist die Verwendung von Dropouts in unserem Deep-Learning-Modell, das wir im nächsten Abschnitt behandeln werden.
Dropouts in TensorFlow verstehen und implementieren
Die Schlüsselüberlegung hinter der Verwendung von Dropouts besteht darin, versteckte und sichtbare Einheiten zufällig zu löschen, um ein weniger komplexes Modell zu erhalten, das die Erhöhung der Parameter des Modells einschränkt und das Modell daher robuster für die Leistung eines verallgemeinerten Datensatzes macht.
Diese kürzlich akzeptierte Praxis ist ein leistungsstarker Ansatz, der von Praktikern des maschinellen Lernens verwendet wird, um einen Regularisierungseffekt in jedem Deep-Learning-Modell hervorzurufen. Dropouts können mühelos mit der Keras-API über TensorFlow implementiert werden, indem die Dropout - Schicht importiert und das Rate- Argument darin übergeben wird, um den Anteil der Einheiten anzugeben, die gelöscht werden müssen.
Diese Dropout-Schichten werden im Allgemeinen direkt nach jeder dichten Schicht gestapelt, um eine abwechselnde Flut einer Architektur mit dichten Dropout- Schichten zu erzeugen .
Wir können unser zuvor definiertes neuronales Feedforward-Netzwerk so modifizieren, dass es sechs Dropout - Schichten enthält, eine für jede verborgene Schicht:


Hier wurde die dropout _ rate auf 0,2 gesetzt, was bedeutet, dass 20 % der Knoten beim Trainieren des Modells fallen gelassen werden. Wir kompilieren und trainieren das Modell mit dem gleichen Optimierer, der gleichen Verlustfunktion, Metriken und der Anzahl der Epochen, um einen fairen Vergleich zu ermöglichen.
Die primäre Auswirkung der Regularisierung des Modells unter Verwendung von Dropouts kann interpretiert werden, indem die Verlustkurve des Modells, das auf den Trainings- und Validierungssets erhalten wurde, erneut aufgetragen wird:
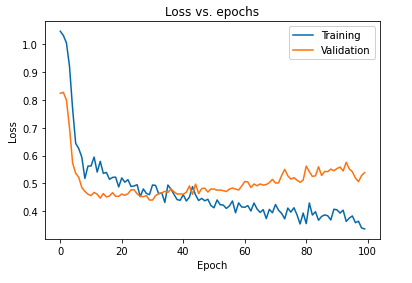
Aus dem obigen Diagramm ist ersichtlich, dass die nach der Regularisierung des Modells erhaltene Generalisierungslücke viel kleiner ist, was das Modell weniger anfällig für eine Überanpassung der Trainingsdaten macht.
Lesen Sie auch: Deep-Learning-Projektideen
Fazit
Der Aspekt der Modellvalidierung und -regularisierung ist ein wesentlicher Bestandteil des Entwurfs des Workflows zum Erstellen einer Lösung für maschinelles Lernen. Es wird viel geforscht, um überwachtes Lernen zu improvisieren, und dieses praktische Tutorial bietet einen kurzen Einblick in einige der am meisten akzeptierten Praktiken und Techniken beim Zusammenstellen eines Lernalgorithmus.
Wenn Sie mehr über Deep-Learning-Techniken und maschinelles Lernen erfahren möchten, sehen Sie sich die PG-Zertifizierung von IIIT-B & upGrad für maschinelles Lernen und Deep Learning an, die für Berufstätige konzipiert ist und mehr als 240 Stunden strenge Schulungen und mehr als 5 Fallstudien bietet & Aufgaben, IIIT-B Alumni-Status & Jobassistenz bei Top-Firmen.