
數據科學家如何在 Python Notebook 上輕鬆使用 ScRapy
已發表: 2020-11-30目錄
介紹
網絡抓取是訪問互聯網上大量可用數據的最簡單、最便宜的方法之一。 我們可以輕鬆構建結構化數據集,這些數據可以進一步用於定量分析、預測、情緒分析等。下載網站數據的最佳方法是使用其公共數據 API(最快且可靠),但並非全部網站提供 API。 有時 API 沒有定期更新,我們可能會錯過重要數據。
因此,我們可以使用像 Scrapy 或 Selenium 這樣的工具來進行網絡爬取和抓取。 Scrapy 是一個用 Python 編寫的免費開源網絡爬蟲框架。 使用 scrapy 的最常見方式是在 Python 終端上,有很多文章可以指導您完成整個過程。
儘管上述過程在 python 開發人員中非常流行,但對數據科學家來說並不是很直觀。 有一種更簡單但不受歡迎的方式可以在 Jupyter 筆記本上使用 scrapy 即。 正如我們所知,Python notebook 相當新,主要用於數據分析目的,在同一個工具上創建 scrapy 函數相對容易和直接。
HTML標籤基礎
在 Python Notebook 上安裝 Scrapy
以下代碼塊安裝並導入在 python notebook 上開始使用 scrapy 所需的必要包:
!pip 安裝scrapy
導入scrapy
從 scrapy.crawler 導入 CrawlerRunner
!pip 安裝鉤針
從鉤針導入設置
設置()
導入請求
從 scrapy.http 導入 TextResponse
Crawler Runner 將用於運行我們創建的蜘蛛。 TextResponse 作為一個scrapy shell,可用於抓取一個URL並調查HTML標籤以從網頁中提取數據。 我們稍後可以創建一個蜘蛛來自動化整個過程並抓取多達n個頁面的數據。
鉤針設置為處理ReactorNotRestartable錯誤。 現在讓我們看看如何使用CSS 選擇器和 X-path從網頁中實際提取數據。 我們將以搜索字符串為tesla為例來抓取yahoo 新聞網站。 我們將抓取網頁以獲取文章的標題。
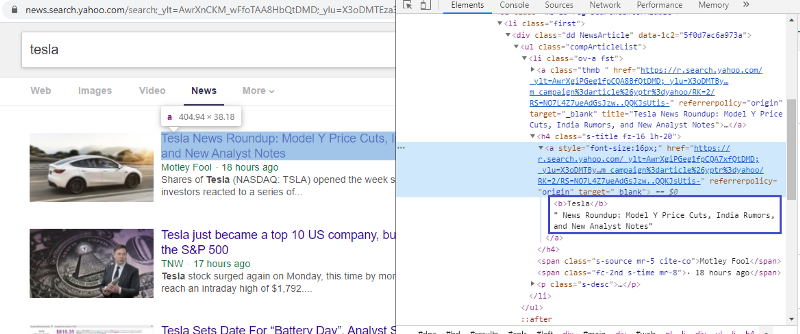
檢查元素以檢查 HTML 標記
右鍵單擊第一個鏈接並選擇檢查元素將為我們提供上述結果。 我們可以看到標題是 <a> 類的一部分。 我們將使用這個標籤並嘗試在 python 上提取標題信息。 下面的代碼將在 python 對像中加載雅虎新聞網站。
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
response = TextResponse(r.url, body=r.text, encoding='utf-8')
響應變量以 html 格式存儲網頁。 讓我們嘗試使用 <a> 標籤提取信息。 下面的代碼行使用 CSS 提取器,它使用 <a> 標籤從網頁中提取標題。
response.css('a').extract()
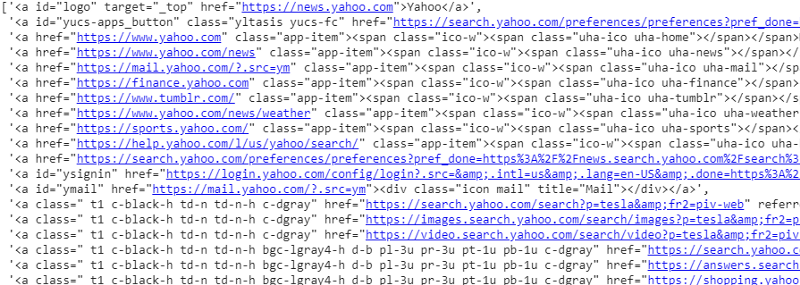
CSS 選擇器在響應變量上的輸出
正如我們所見,<a> 標籤下不僅僅是文章的詳細信息。 因此 <a> 標籤無法正確提取標題。 獲取特定標籤的更直觀和精確的方法是使用選擇器小工具。 在 chrome 上安裝選擇器小工具後,我們可以使用它來查找要提取的網頁的任何特定部分的標籤。 下面我們可以看到 Selector Gadget 建議的標籤:
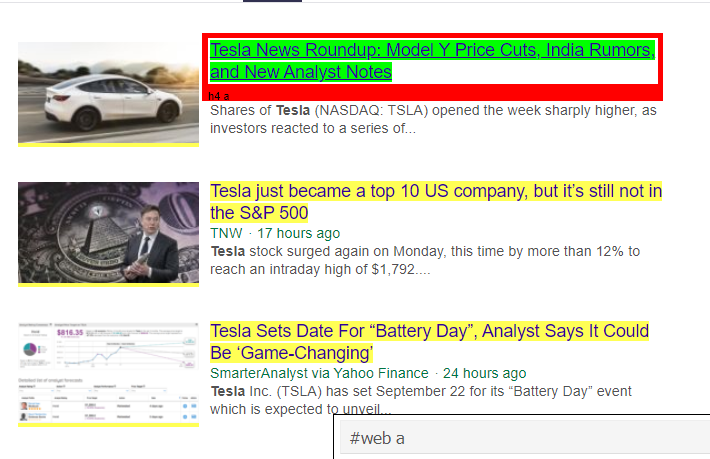
選擇器小工具建議的 HTML 標記
讓我們嘗試使用“#web a”選擇器提取信息。 下面的代碼將使用 CSS 提取器提取標題信息。
response.css('#web a').extract()

使用“#web a”標籤後的輸出
使用 Gadget Selector 建議的標籤後,我們可以使用此標籤獲得更簡潔的結果。 但是,我們只需要提取文章的標題並將其他信息分開即可。 我們可以在上面添加X-path選擇器並做同樣的事情。 下面的代碼將從 CSS 標籤中提取標題文本:
response.css('#web a').xpath('@title').extract()

所有標題的列表
正如我們所見,我們成功地從雅虎新聞網站中提取了文章的標題。 雖然這是一個試錯過程,但我們絕對可以理解流程歸結為從網頁中提取任何特定信息所需的正確標籤和 xpath 地址。
我們可以通過使用檢查元素和選擇器小工具類似地提取鏈接、描述、日期和發布者。 這是一個迭代過程,可能需要一些時間才能獲得理想的結果。 我們可以使用此代碼片段從雅虎新聞網頁中提取數據。
title = response.css('#web a').xpath(“@title”).extract()
media = response.css('.cite-co::text').extract()
desc = response.css('ps-desc').extract()
日期 = response.css('#web .mr-8::text').extract()
鏈接 = response.css('h4.s-title a').xpath(“@href”).extract()
閱讀:數據科學職業
構建蜘蛛
我們現在知道如何使用標籤來使用響應變量和 css 提取器來提取特定的信息。 我們現在必須用 Scrapy Spider 把它串起來。 Scrapy Spiders 是具有預定義結構的類,用於從網站上抓取和抓取信息。 蜘蛛可以控制的東西有很多:
- 要從響應變量中提取的數據。
- 結構化和返回數據。
- 如果提取的數據中有不需要的信息,則清理數據。
- 抓取網站直到某個頁碼的選項。
因此,蜘蛛本質上是使用 Scrapy 構建網絡抓取功能的核心。 讓我們仔細看看蜘蛛的每個部分。 上面已經介紹了要提取的數據部分,我們使用響應變量從網頁中提取特定數據。
清理數據
下面的代碼塊將清理描述數據。
TAG_RE = re.compile(r'<[^>]+>') # 去除html標籤
j = 0
#cleaning 描述字符串
對於我在 desc 中:
desc[j] = TAG_RE.sub(”, i)
j = j + 1
此代碼使用正則表達式並從文章描述中刪除不需要的 html 標籤。
前:
<p class=”s-desc”>在最近接受 Motley Fool Live 採訪時,Motley Fool 聯合創始人兼 CEO
湯姆加德納回憶起與肯德爾馬斯克的會面——<b>特斯拉</b>(納斯達克股票代碼:TSLA)的兄弟……</p>
正則表達式之後:
在最近接受 Motley Fool Live 採訪時,Motley Fool 聯合創始人兼首席執行官湯姆·加德納回憶起與特斯拉(納斯達克股票代碼:TSLA)的兄弟肯德爾·馬斯克的會面。
我們現在可以看到額外的 html 標記已從文章描述中刪除。
結構化和返回數據
# 逐行給出提取的內容
對於 zip 中的項目(標題、媒體、鏈接、描述、日期):
# 創建一個字典來存儲抓取的信息
刮取信息 = {
'標題':項目[0],
'媒體':項目[1],
'鏈接':項目[2],
'描述':項目[3],
'日期':項目[4],
“搜索字符串”:搜索字符串,
“來源”:“雅虎新聞”,

}
# yield 或將抓取的信息提供給scrapy
產生 scraped_info
從網頁中提取的數據存儲在不同的列表變量中。 我們正在創建一個字典,然後在蜘蛛之外返回。 Yield 函數是任何蜘蛛類的函數,用於將數據返回給函數。 然後可以將這些數據保存為 json、csv 或不同類型的數據集。
必讀:印度數據科學家的薪水
導航到 n 個頁面
下面的代碼塊在嘗試轉到雅虎新聞的下一頁結果時使用該鏈接。 迭代頁碼變量,直到達到 page_limit 並且對於每個頁碼,都會創建一個唯一鏈接,因為該變量用於鏈接字符串。 然後下面的命令跟隨到新頁面並從該頁面產生信息。
總而言之,我們能夠使用基本超鏈接導航頁面並編輯頁碼和關鍵字等信息。 為某些頁面提取基本超鏈接可能有點複雜,但通常需要了解鏈接如何在下一頁更新的模式。
pagenumber = 1 #初始化頁碼
page_limit = 5 #要抓取的頁面
#follow on page url初始化 next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.pagenumber)+”1&pz=10&bct=0&xargs=0”
如果(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
產生 response.follow(next_page,callback=self.parse)
#導航到下一頁
最終功能
下面的代碼塊是最後一個函數,調用時會將搜索字符串的數據導出為 .csv 格式。
def yahoo_news ( searchstr,lim ):
TAG_RE =重新。 compile (r '<[^>]+>' ) # 移除 html 標籤
MySpider類( scrapy.Spider ) : _
cnt = 1
名稱 = '雅虎新聞' #蜘蛛的名字
頁碼 = 1 #初始化頁碼
res_limit =限制 #要抓取的頁面
關鍵字 = searchstr #搜索字符串
start_urls = [ “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=
“ +keyword+ “&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def解析(自我,響應):
#要從HTML中提取的數據
title = response.css( '#web a' ).xpath( “@title” ).extract()
media = response.css( '.cite-co::text' ).extract()
desc = response.css( 'ps-desc' ).extract()
日期 = response.css( '#web .mr-8::text' ).extract()
鏈接 = response.css( 'h4.s-title a' ).xpath( “@href” ).extract()
j = 0
#cleaning 描述字符串
對於我在desc 中:
desc[j] = TAG_RE.sub( ” , i)
j = j + 1
# 逐行給出提取的內容
對於zip中的項目(標題、媒體、鏈接、描述、日期):
# 創建一個字典來存儲抓取的信息
刮取信息 = {
'標題' :項目[ 0 ],
'媒體' :項目[ 1 ],
'鏈接' :項目[ 2 ],
'描述' :項目[ 3 ],
'日期' :項目[ 4 ],
“搜索字符串” :搜索字符串,
“來源” : “雅虎新聞” ,
}
# yield 或將抓取的信息提供給scrapy
產生scraped_info
#follow on page url初始化
next_page= “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
“8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.keyword+ “&nojs=1&ei=” \
“UTF-8&b=” +str(MySpider.pagenumber)+ “1&pz=10&bct=0&xargs=0”
如果(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
yield response.follow(next_page,callback= self .parse) #navigation to next page
如果__name__ == “__main__” :
#啟動爬取過程
跑步者= CrawlerRunner(設置= {
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }, #set output in settings
},
})
d=runner.crawl(MySpider) # 腳本會在這裡阻塞,直到爬取完成
我們可以發現不同的代碼塊,這些代碼塊被集成來製作蜘蛛。 主要部分實際上用於啟動蜘蛛並配置輸出格式。 關於爬蟲,可以編輯各種不同的設置。 可以使用中間件或代理進行跳躍。
runner.crawl(spider) 將執行整個過程,我們將輸出作為逗號分隔的文件。
輸出
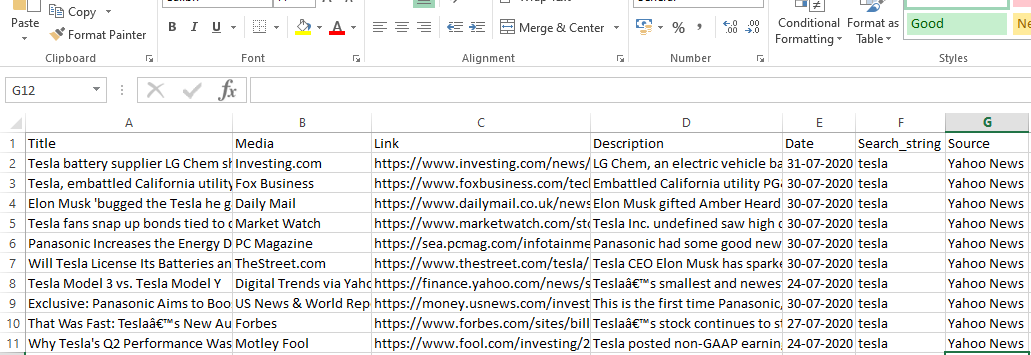
結論
我們現在可以在 Python 筆記本上使用 Scrapy 作為 api,並創建蜘蛛來抓取和抓取不同的網站。 我們還研究瞭如何使用不同的標籤和 X-path 從網頁訪問信息。
學習世界頂尖大學的數據科學課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
什麼是ScRapy?
ScRapy 的實際用例是什麼?
ScRapy 用於決定價格點。 公司從競爭對手的網站收集價格信息和數據,以幫助做出一些重要的商業決策。 然後,他們保存並分析所有數據,對優化銷售和利潤進行必要的定價修改。 幾家公司已經能夠通過從競爭對手網站收集數據來獲得有關季節性銷售需求的見解。 然後,他們利用這些數據來確定需要更多設施或人員來滿足不斷增長的需求。 ScRapy 還用於招聘服務、保持成本領先和物流、建立目錄和電子商務。
ScRapy 是如何工作的?
ScRapy 使用時間和脈衝控制的處理,這意味著請求進程不等待響應,而是根據時間移動到下一個作業。 當收到響應時,請求進程繼續更改響應。 ScRapy 可以毫不費力地完成大型任務。 它可以在一分鐘內抓取一組 URL,具體取決於組的大小,並且由於它利用 Twister 進行並行處理,它以異步方式(非阻塞)運行,因此速度非常快。