
Comment un Data Scientist peut-il facilement utiliser ScRapy sur Python Notebook
Publié: 2020-11-30Table des matières
introduction
Le Web-Scraping est l'un des moyens les plus simples et les moins chers d'accéder à une grande quantité de données disponibles sur Internet. Nous pouvons facilement créer des ensembles de données structurés et ces données peuvent être utilisées pour l'analyse quantitative, la prévision, l'analyse des sentiments, etc. La meilleure méthode pour télécharger les données d'un site Web consiste à utiliser son API de données publiques (la plus rapide et la plus fiable), mais pas toutes les sites Web fournissent des API. Parfois, les API ne sont pas mises à jour régulièrement et nous pouvons manquer des données importantes.
Par conséquent, nous pouvons utiliser des outils tels que Scrapy ou Selenium pour explorer et gratter le Web comme alternative. Scrapy est un framework d'exploration Web gratuit et open-source écrit en Python. La manière la plus courante d'utiliser scrapy est sur le terminal Python et de nombreux articles peuvent vous guider tout au long du processus.
Bien que le processus ci-dessus soit très populaire parmi les développeurs Python, il n'est pas très intuitif pour un data scientist. Il existe un moyen plus simple mais impopulaire d'utiliser scrapy, c'est-à-dire sur le bloc-notes Jupyter. Comme nous savons que les notebooks Python sont relativement nouveaux et principalement utilisés à des fins d'analyse de données, la création de fonctions scrapy sur le même outil est relativement simple et directe.
Bases des balises HTML
Installer Scrapy sur Python Notebook
Le bloc de code suivant installe et importe les packages nécessaires pour démarrer avec scrapy sur python notebook :
!pip installer scrapy
importer scrapy
de scrapy.crawler importer CrawlerRunner
!pip installer crochet
à partir de la configuration d'importation au crochet
mettre en place()
demandes d'importation
de scrapy.http importer TextResponse
Crawler Runner sera utilisé pour exécuter l'araignée que nous créons. TextResponse fonctionne comme un shell scrapy qui peut être utilisé pour gratter une URL et enquêter sur les balises HTML pour l'extraction de données à partir de la page Web. Nous pouvons ensuite créer une araignée pour automatiser l'ensemble du processus et récupérer les données jusqu'à un nombre n de pages.
Crochet est configuré pour gérer l' erreur ReactorNotRestartable . Voyons maintenant comment nous pouvons réellement extraire des données d'une page Web à l'aide du sélecteur CSS et du X-path. Nous allons gratter le site d' actualités yahoo avec la chaîne de recherche comme tesla dans cet exemple. Nous allons gratter la page Web pour obtenir le titre des articles.
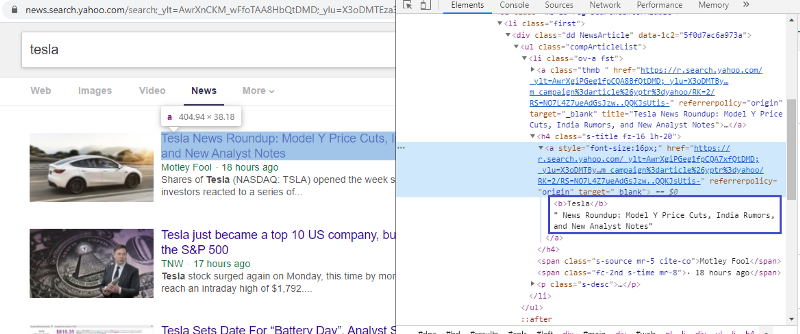
Inspecter l'élément pour vérifier la balise HTML
Un clic droit sur le premier lien et la sélection de l'élément d'inspection nous donneront le résultat ci-dessus. Nous pouvons voir que le titre fait partie de la classe <a>. Nous allons utiliser cette balise et essayer d'extraire les informations du titre sur python. Le code ci-dessous chargera le site Web Yahoo News dans un objet python.
r=requests.get("https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0")
réponse = TextResponse(r.url, body=r.text, encoding='utf-8′)
La variable de réponse stocke la page Web au format html. Essayons d'extraire des informations en utilisant la balise <a>. La ligne de code ci-dessous utilise un extracteur CSS qui utilise la balise <a> pour extraire les titres de la page Web.
réponse.css('a').extract()
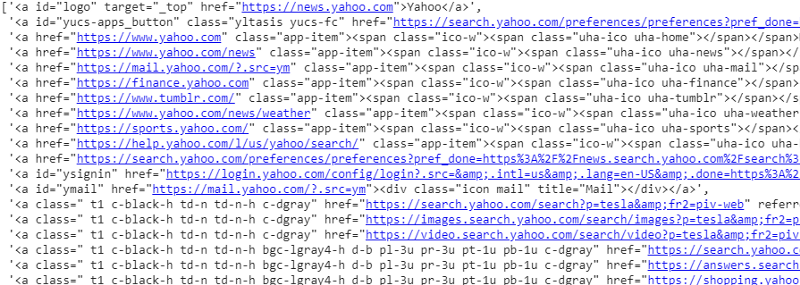
Sortie du sélecteur CSS sur la variable de réponse
Comme nous pouvons le voir, il n'y a pas que les détails de l'article sous la balise <a>. Par conséquent, la balise <a> n'est pas en mesure d'extraire correctement les titres. Le moyen le plus intuitif et le plus précis d'obtenir des balises spécifiques consiste à utiliser le gadget sélecteur . Après avoir installé le gadget de sélection sur chrome, nous pouvons l'utiliser pour rechercher les balises de toutes les parties spécifiques de la page Web que nous souhaitons extraire. Ci-dessous, nous pouvons voir la balise suggérée par le gadget de sélection :
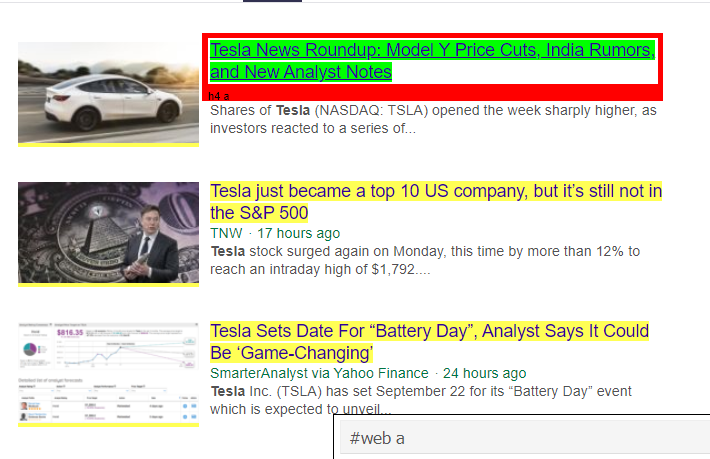
Balise HTML suggérée par Selector Gadget
Essayons d'extraire des informations en utilisant le sélecteur '#web a'. Le code ci-dessous extraira les informations de titre à l'aide de l'extracteur CSS.
réponse.css('#web a').extract()

Sortie après utilisation de la balise '#web a'
Après avoir utilisé la balise suggérée par Gadget Selector, nous obtenons des résultats plus concis en utilisant cette balise. Mais encore, nous avons juste besoin d'extraire le titre de l'article et de laisser les autres informations de côté. Nous pouvons ajouter un sélecteur X-path à ce sujet et faire de même. Le code ci-dessous extraira le texte du titre des balises CSS :
réponse.css('#web a').xpath('@title').extract()

Liste de tous les titres
Comme nous pouvons le constater, nous réussissons à extraire les titres des articles du site Web Yahoo News. Bien qu'il s'agisse d'un peu de procédure d'essais et d'erreurs, nous pouvons certainement comprendre le flux de processus pour se résumer à corriger les balises et l'adresse XPath nécessaires pour extraire des informations spécifiques d'une page Web.
Nous pouvons également extraire le lien, la description, la date et l'éditeur en utilisant l'élément d'inspection et le gadget de sélection. Il s'agit d'un processus itératif qui peut prendre un certain temps avant d'obtenir les résultats souhaités. Nous pouvons utiliser cet extrait de code pour extraire les données de la page Web Yahoo News.
titre = réponse.css('#web a').xpath(“@titre”).extract()
média = réponse.css('.cite-co::text').extract()
desc = réponse.css('ps-desc').extract()
date = réponse.css('#web .mr-8::text').extract()
lien = réponse.css('h4.s-titre a').xpath(“@href”).extract()
Lire : Carrière en science des données
Construire l'araignée
Nous savons maintenant comment utiliser des balises pour extraire des informations spécifiques à l'aide de la variable de réponse et de l'extracteur css. Nous devons maintenant enchaîner cela avec Scrapy Spider. Scrapy Spiders sont des classes avec une structure prédéfinie qui sont conçues pour explorer et récupérer des informations sur les sites Web. Il y a beaucoup de choses qui peuvent être contrôlées par les araignées :
- Données à extraire des variables de réponse.
- Structuration et Restitution des données.
- Nettoyer les données s'il y a des éléments d'information indésirables dans les données extraites.
- Possibilité de gratter des sites Web jusqu'à un certain nombre de pages.
Par conséquent, l'araignée est essentiellement au cœur de la création d'une fonction de grattage Web à l'aide de Scrapy. Examinons de plus près chaque partie de l'araignée. La partie des données à extraire est déjà couverte ci-dessus où nous utilisions des variables de réponse pour extraire des données spécifiques de la page Web.
Données de nettoyage
Le bloc de code ci-dessous nettoiera les données de description.
TAG_RE = re.compile(r'<[^>]+>') # suppression des balises html
j = 0
#nettoyage Chaîne de description
pour moi dans desc :
desc[j] = TAG_RE.sub(", je)
j = j + 1
Ce code utilise une expression régulière et supprime les balises html indésirables de la description des articles.
Avant de:
<p class=”s-desc”>Dans une récente interview sur Motley Fool Live, Motley Fool co-fondateur et PDG
Tom Gardner se souvient avoir rencontré Kendal Musk, le frère de <b>Tesla</b> (NASDAQ : TSLA)… </p>
Après Regex :
Dans une récente interview sur Motley Fool Live, le co-fondateur et PDG de Motley Fool, Tom Gardner, s'est souvenu d'avoir rencontré Kendal Musk, le frère de Tesla (NASDAQ : TSLA).
Nous pouvons maintenant voir que les balises html supplémentaires sont supprimées de la description de l'article.

Structuration et restitution des données
# Donnez le contenu extrait par ligne
pour l'élément dans le zip (titre, média, lien, description, date) :
# créer un dictionnaire pour stocker les informations récupérées
scraped_info = {
'Titre' : élément[0],
'Média' : élément[1],
'Lien' : élément[2],
'Description' : élément[3],
'Date' : élément[4],
'Search_string' : chaîne de recherche,
'Source' : "Yahoo News",
}
# céder ou donner les informations grattées à scrapy
rendement scraped_info
Les données extraites des pages Web sont stockées dans différentes variables de liste. Nous créons un dictionnaire qui est ensuite renvoyé à l'extérieur de l'araignée. La fonction Yield est une fonction de n'importe quelle classe spider et est utilisée pour renvoyer des données à la fonction. Ces données peuvent ensuite être enregistrées au format json, csv ou différents types de jeux de données.
Doit lire: Salaire de Data Scientist en Inde
Navigation vers n nombre de pages
Le bloc de code ci-dessous utilise le lien lorsque l'on essaie d'aller à la page suivante de résultats sur Yahoo News. La variable de numéro de page est itérée jusqu'à ce que le page_limit atteigne et pour chaque numéro de page, un lien unique est créé car la variable est utilisée dans la chaîne de lien. La commande suivante suit ensuite la nouvelle page et fournit les informations de cette page.
Dans l'ensemble, nous sommes en mesure de naviguer dans les pages à l'aide d'un lien hypertexte de base et de modifier des informations telles que le numéro de page et le mot-clé. Il peut être un peu compliqué d'extraire le lien hypertexte de base pour certaines pages, mais cela nécessite généralement de comprendre le modèle de mise à jour du lien sur les pages suivantes.
pagenumber = 1 #numéro de page initial
page_limit = 5 #Pages à gratter
#follow on page url initialisation next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.pagenumber)+”1&pz=10&bct=0&xargs=0″
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
rendement réponse. suivre (page_suivante, rappel = self.parse)
#navigation vers la page suivante
Fonction finale
Le bloc de code ci-dessous est la fonction finale lorsqu'il est appelé, il exportera les données de la chaîne de recherche au format .csv.
def yahoo_news ( searchstr,lim ):
TAG_RE = ré. compile (r '<[^>]+>' ) # suppression des balises html
class MySpider ( scrapy . Spider ):
nombre = 1
nom = 'yahoonews' #nom de l'araignée
numéro de page = 1 #numéro de page initial
res_limit = lim #Pages à gratter
mot-clé = searchstr #Chaîne de recherche
start_urls = [ "https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=
" +mot clé+ "&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0" ]
def analyse ( self , réponse ):
#Données à extraire du HTML
titre = réponse.css( '#web a' ).xpath( "@titre" ).extract()
média = réponse.css( '.cite-co::text' ).extract()
desc = réponse.css( 'ps-desc' ).extract()
date = réponse.css( '#web .mr-8::text' ).extract()
lien = réponse.css( 'h4.s-title a' ).xpath( "@href" ).extract()
j = 0
#nettoyage Chaîne de description
pour moi dans desc :
desc[j] = TAG_RE.sub( ” , je)
j = j + 1
# Donnez le contenu extrait par ligne
pour l'élément dans le zip (titre, média, lien, description, date) :
# créer un dictionnaire pour stocker les informations récupérées
scraped_info = {
'Titre' : élément[ 0 ],
'Média' : élément[ 1 ],
'Lien' : élément[ 2 ],
'Description' : élément[ 3 ],
'Date' : élément[ 4 ],
'Search_string' : chaîne de recherche,
'Source' : "Yahoo News" ,
}
# céder ou donner les informations grattées à scrapy
rendement scraped_info
#suivre l'initialisation de l'url de la page
next_page= "https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG" \
« 8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p= » +MySpider.keyword+ « &nojs=1&ei= » \
"UTF-8&b=" +str(MySpider.pagenumber)+ "1&pz=10&bct=0&xargs=0"
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
rendement response.follow(next_page,callback= self .parse) #navigation vers la page suivante
si __nom__ == "__main__" :
#initier le processus d'exploration
coureur = CrawlerRunner(settings={
"FEEDS" : { "yahoo_output.csv" : { "format" : "csv" }, #définir la sortie dans les paramètres
},
})
d=runner.crawl(MySpider) # le script bloquera ici jusqu'à ce que l'exploration soit terminée
On peut repérer différents blocs de codes qui sont intégrés pour fabriquer l'araignée. La partie principale est en fait utilisée pour démarrer l'araignée et configurer le format de sortie. Il existe différents paramètres qui peuvent être modifiés concernant le crawler. On peut utiliser des middlewares ou des proxies pour sauter.
runner.crawl(spider) exécutera l'ensemble du processus et nous obtiendrons la sortie sous forme de fichier séparé par des virgules.
Sortir
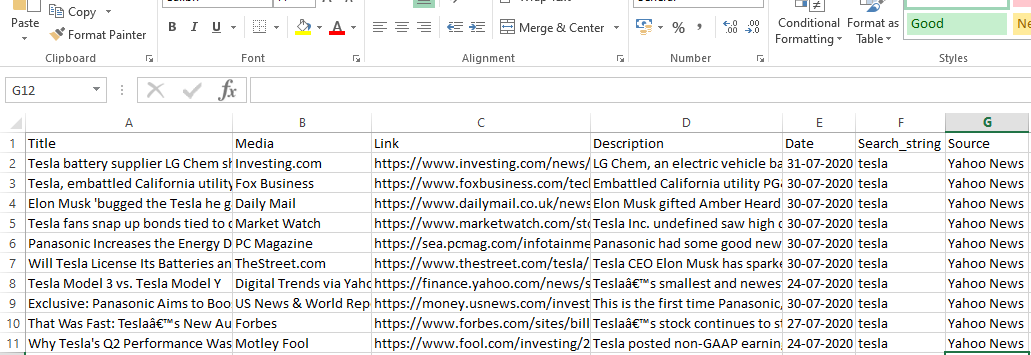
Conclusion
Nous pouvons désormais utiliser Scrapy comme API sur les notebooks Python et créer des araignées pour explorer et gratter différents sites Web. Nous avons également examiné comment différentes balises et X-path peuvent être utilisés pour accéder aux informations d'une page Web.
Apprenez des cours de science des données dans les meilleures universités du monde. Gagnez des programmes Executive PG, des programmes de certificat avancés ou des programmes de maîtrise pour accélérer votre carrière.
Qu'est-ce que ScRapy ?
Quel est le cas d'utilisation réel de ScRapy ?
ScRapy est utilisé pour décider des niveaux de prix. Les entreprises collectent des informations sur les prix et des données sur des sites Web concurrents pour les aider à prendre plusieurs décisions commerciales importantes. Ils enregistrent et analysent ensuite toutes les données, apportant les modifications de prix nécessaires pour optimiser les ventes et les bénéfices. Plusieurs entreprises ont pu obtenir des informations sur la demande de ventes saisonnières en collectant des données auprès de sites concurrents. Ils ont ensuite utilisé les données pour identifier le besoin de plus d'installations ou de personnel pour répondre à la demande croissante. ScRapy est également utilisé pour recruter des services, maintenir la maîtrise des coûts et la logistique, créer des annuaires et le commerce électronique.
Comment fonctionne ScRapy ?
ScRapy utilise un traitement contrôlé par le temps et les impulsions, ce qui signifie que le processus demandeur n'attend pas la réponse et passe à la place à la tâche suivante en fonction du temps. Lorsqu'une réponse est reçue, le processus demandeur passe à la modification de la réponse. ScRapy peut facilement effectuer de grandes tâches. Il peut explorer un groupe d'URL en moins d'une minute, selon la taille du groupe, et le fait incroyablement rapidement car il utilise Twister pour le parallélisme, qui fonctionne de manière asynchrone (non bloquant).