
数据科学家如何在 Python Notebook 上轻松使用 ScRapy
已发表: 2020-11-30目录
介绍
网络抓取是访问互联网上大量可用数据的最简单、最便宜的方法之一。 我们可以轻松构建结构化数据集,这些数据可以进一步用于定量分析、预测、情绪分析等。下载网站数据的最佳方法是使用其公共数据 API(最快且可靠),但并非全部网站提供 API。 有时 API 没有定期更新,我们可能会错过重要数据。
因此,我们可以使用像 Scrapy 或 Selenium 这样的工具来进行网络爬取和抓取。 Scrapy 是一个用 Python 编写的免费开源网络爬虫框架。 使用 scrapy 的最常见方式是在 Python 终端上,有很多文章可以指导您完成整个过程。
尽管上述过程在 python 开发人员中非常流行,但对数据科学家来说并不是很直观。 有一种更简单但不受欢迎的方式可以在 Jupyter 笔记本上使用 scrapy 即。 正如我们所知,Python notebook 相当新,主要用于数据分析目的,在同一个工具上创建 scrapy 函数相对容易和直接。
HTML标签基础
在 Python Notebook 上安装 Scrapy
以下代码块安装并导入在 python notebook 上开始使用 scrapy 所需的必要包:
!pip 安装scrapy
导入scrapy
从 scrapy.crawler 导入 CrawlerRunner
!pip 安装钩针
从钩针导入设置
设置()
导入请求
从 scrapy.http 导入 TextResponse
Crawler Runner 将用于运行我们创建的蜘蛛。 TextResponse 作为一个scrapy shell,可用于抓取一个URL并调查HTML标签以从网页中提取数据。 我们稍后可以创建一个蜘蛛来自动化整个过程并抓取多达n个页面的数据。
钩针设置为处理ReactorNotRestartable错误。 现在让我们看看如何使用CSS 选择器和 X-path从网页中实际提取数据。 我们将以搜索字符串为tesla为例来抓取yahoo 新闻网站。 我们将抓取网页以获取文章的标题。
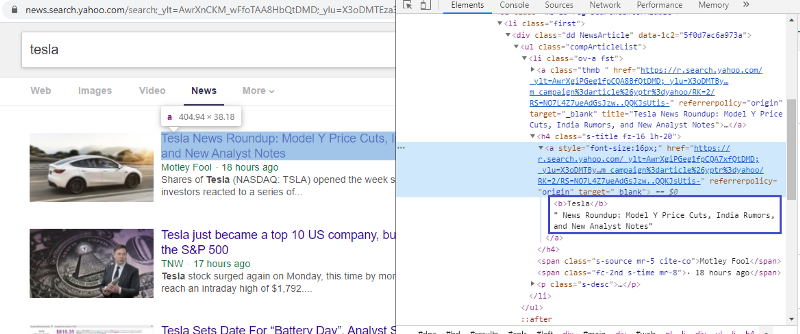
检查元素以检查 HTML 标记
右键单击第一个链接并选择检查元素将为我们提供上述结果。 我们可以看到标题是 <a> 类的一部分。 我们将使用这个标签并尝试在 python 上提取标题信息。 下面的代码将在 python 对象中加载雅虎新闻网站。
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
response = TextResponse(r.url, body=r.text, encoding='utf-8')
响应变量以 html 格式存储网页。 让我们尝试使用 <a> 标签提取信息。 下面的代码行使用 CSS 提取器,它使用 <a> 标签从网页中提取标题。
response.css('a').extract()
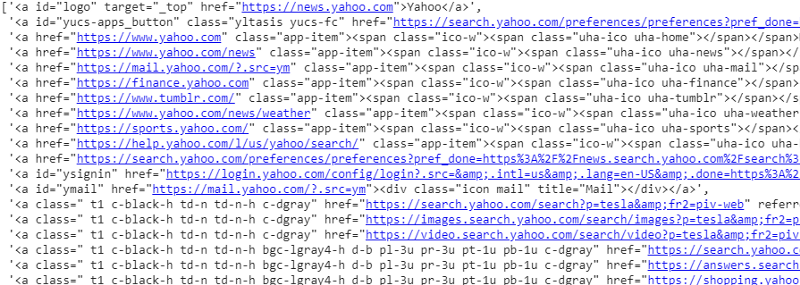
CSS 选择器在响应变量上的输出
正如我们所见,<a> 标签下不仅仅是文章的详细信息。 因此 <a> 标签无法正确提取标题。 获取特定标签的更直观和精确的方法是使用选择器小工具。 在 chrome 上安装选择器小工具后,我们可以使用它来查找要提取的网页的任何特定部分的标签。 下面我们可以看到 Selector Gadget 建议的标签:
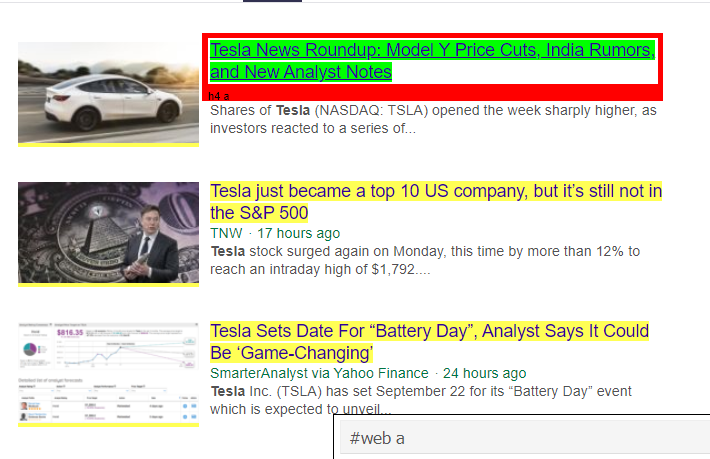
选择器小工具建议的 HTML 标记
让我们尝试使用“#web a”选择器提取信息。 下面的代码将使用 CSS 提取器提取标题信息。
response.css('#web a').extract()

使用“#web a”标签后的输出
使用 Gadget Selector 建议的标签后,我们可以使用此标签获得更简洁的结果。 但是,我们只需要提取文章的标题并将其他信息分开即可。 我们可以在上面添加X-path选择器并做同样的事情。 下面的代码将从 CSS 标签中提取标题文本:
response.css('#web a').xpath('@title').extract()

所有标题的列表
正如我们所见,我们成功地从雅虎新闻网站中提取了文章的标题。 虽然这是一个试错过程,但我们绝对可以理解流程归结为从网页中提取任何特定信息所需的正确标签和 xpath 地址。
我们可以通过使用检查元素和选择器小工具类似地提取链接、描述、日期和发布者。 这是一个迭代过程,可能需要一些时间才能获得理想的结果。 我们可以使用此代码片段从雅虎新闻网页中提取数据。
title = response.css('#web a').xpath(“@title”).extract()
media = response.css('.cite-co::text').extract()
desc = response.css('ps-desc').extract()
日期 = response.css('#web .mr-8::text').extract()
链接 = response.css('h4.s-title a').xpath(“@href”).extract()
阅读:数据科学职业
构建蜘蛛
我们现在知道如何使用标签来使用响应变量和 css 提取器来提取特定的信息。 我们现在必须用 Scrapy Spider 把它串起来。 Scrapy Spiders 是具有预定义结构的类,用于从网站上抓取和抓取信息。 蜘蛛可以控制的东西有很多:
- 要从响应变量中提取的数据。
- 结构化和返回数据。
- 如果提取的数据中有不需要的信息,则清理数据。
- 抓取网站直到某个页码的选项。
因此,蜘蛛本质上是使用 Scrapy 构建网络抓取功能的核心。 让我们仔细看看蜘蛛的每个部分。 上面已经介绍了要提取的数据部分,我们使用响应变量从网页中提取特定数据。
清理数据
下面的代码块将清理描述数据。
TAG_RE = re.compile(r'<[^>]+>') # 去除html标签
j = 0
#cleaning 描述字符串
对于我在 desc 中:
desc[j] = TAG_RE.sub(”, i)
j = j + 1
此代码使用正则表达式并从文章描述中删除不需要的 html 标签。
前:
<p class=”s-desc”>在最近接受 Motley Fool Live 采访时,Motley Fool 联合创始人兼 CEO
汤姆加德纳回忆起与肯德尔马斯克的会面——<b>特斯拉</b>(纳斯达克股票代码:TSLA)的兄弟……</p>
正则表达式之后:
在最近接受 Motley Fool Live 采访时,Motley Fool 联合创始人兼首席执行官汤姆·加德纳回忆起与特斯拉(纳斯达克股票代码:TSLA)的兄弟肯德尔·马斯克的会面。
我们现在可以看到额外的 html 标记已从文章描述中删除。
结构化和返回数据
# 逐行给出提取的内容
对于 zip 中的项目(标题、媒体、链接、描述、日期):
# 创建一个字典来存储抓取的信息
刮取信息 = {
'标题':项目[0],
'媒体':项目[1],
'链接':项目[2],
'描述':项目[3],
'日期':项目[4],
“搜索字符串”:搜索字符串,
“来源”:“雅虎新闻”,

}
# yield 或将抓取的信息提供给scrapy
产生 scraped_info
从网页中提取的数据存储在不同的列表变量中。 我们正在创建一个字典,然后在蜘蛛之外返回。 Yield 函数是任何蜘蛛类的函数,用于将数据返回给函数。 然后可以将这些数据保存为 json、csv 或不同类型的数据集。
必读:印度数据科学家的薪水
导航到 n 个页面
下面的代码块在尝试转到雅虎新闻的下一页结果时使用该链接。 迭代页码变量,直到达到 page_limit 并且对于每个页码,都会创建一个唯一链接,因为该变量用于链接字符串。 然后下面的命令跟随到新页面并从该页面产生信息。
总而言之,我们能够使用基本超链接导航页面并编辑页码和关键字等信息。 为某些页面提取基本超链接可能有点复杂,但通常需要了解链接如何在下一页更新的模式。
pagenumber = 1 #初始化页码
page_limit = 5 #要抓取的页面
#follow on page url初始化 next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.pagenumber)+”1&pz=10&bct=0&xargs=0”
如果(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
产生 response.follow(next_page,callback=self.parse)
#导航到下一页
最终功能
下面的代码块是最后一个函数,调用时会将搜索字符串的数据导出为 .csv 格式。
def yahoo_news ( searchstr,lim ):
TAG_RE =重新。 compile (r '<[^>]+>' ) # 移除 html 标签
MySpider类( scrapy.Spider ) : _
cnt = 1
名称 = '雅虎新闻' #蜘蛛的名字
页码 = 1 #初始化页码
res_limit =限制 #要抓取的页面
关键字 = searchstr #搜索字符串
start_urls = [ “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=
“ +keyword+ “&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def解析(自我,响应):
#要从HTML中提取的数据
title = response.css( '#web a' ).xpath( “@title” ).extract()
media = response.css( '.cite-co::text' ).extract()
desc = response.css( 'ps-desc' ).extract()
日期 = response.css( '#web .mr-8::text' ).extract()
链接 = response.css( 'h4.s-title a' ).xpath( “@href” ).extract()
j = 0
#cleaning 描述字符串
对于我在desc 中:
desc[j] = TAG_RE.sub( ” , i)
j = j + 1
# 逐行给出提取的内容
对于zip中的项目(标题、媒体、链接、描述、日期):
# 创建一个字典来存储抓取的信息
刮取信息 = {
'标题' :项目[ 0 ],
'媒体' :项目[ 1 ],
'链接' :项目[ 2 ],
'描述' :项目[ 3 ],
'日期' :项目[ 4 ],
“搜索字符串” :搜索字符串,
“来源” : “雅虎新闻” ,
}
# yield 或将抓取的信息提供给scrapy
产生scraped_info
#follow on page url初始化
next_page= “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
“8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.keyword+ “&nojs=1&ei=” \
“UTF-8&b=” +str(MySpider.pagenumber)+ “1&pz=10&bct=0&xargs=0”
如果(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
yield response.follow(next_page,callback= self .parse) #navigation to next page
如果__name__ == “__main__” :
#启动爬取过程
跑步者= CrawlerRunner(设置= {
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }, #set output in settings
},
})
d=runner.crawl(MySpider) # 脚本会在这里阻塞,直到爬取完成
我们可以发现不同的代码块,这些代码块被集成来制作蜘蛛。 主要部分实际上用于启动蜘蛛并配置输出格式。 关于爬虫,可以编辑各种不同的设置。 可以使用中间件或代理进行跳跃。
runner.crawl(spider) 将执行整个过程,我们将输出作为逗号分隔的文件。
输出
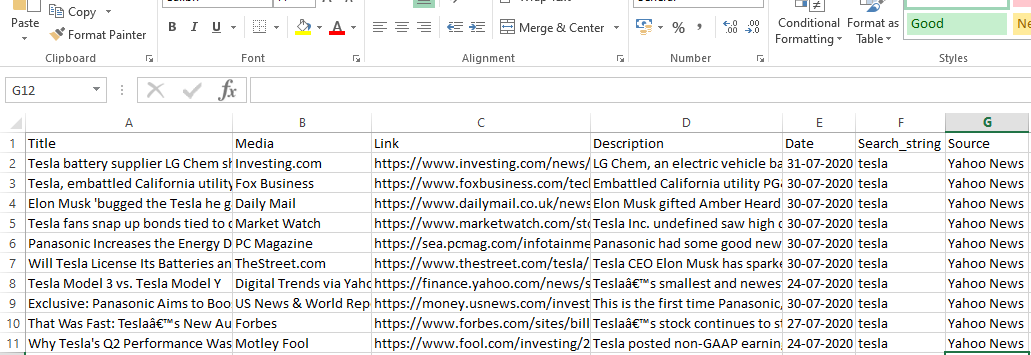
结论
我们现在可以在 Python 笔记本上使用 Scrapy 作为 api,并创建蜘蛛来抓取和抓取不同的网站。 我们还研究了如何使用不同的标签和 X-path 从网页访问信息。
学习世界顶尖大学的数据科学课程。 获得行政 PG 课程、高级证书课程或硕士课程,以加快您的职业生涯。
什么是ScRapy?
ScRapy 的实际用例是什么?
ScRapy 用于决定价格点。 公司从竞争对手的网站收集价格信息和数据,以帮助做出一些重要的商业决策。 然后,他们保存并分析所有数据,对优化销售和利润进行必要的定价修改。 几家公司已经能够通过从竞争对手网站收集数据来获得有关季节性销售需求的见解。 然后,他们利用这些数据来确定需要更多设施或人员来满足不断增长的需求。 ScRapy 还用于招聘服务、保持成本领先和物流、建立目录和电子商务。
ScRapy 是如何工作的?
ScRapy 使用时间和脉冲控制处理,这意味着请求进程不会等待响应,而是根据时间继续执行下一个作业。 当收到响应时,请求进程继续更改响应。 ScRapy 可以毫不费力地完成大型任务。 它可以在一分钟内抓取一组 URL,具体取决于组的大小,并且由于它利用 Twister 进行并行处理,它以异步方式(非阻塞)运行,因此速度非常快。