
Come può un data scientist utilizzare facilmente ScRapy su Python Notebook
Pubblicato: 2020-11-30Sommario
introduzione
Il Web-Scraping è uno dei modi più semplici ed economici per accedere a una grande quantità di dati disponibili su Internet. Possiamo facilmente costruire set di dati strutturati e che i dati possono essere ulteriormente utilizzati per analisi quantitativa, previsione, analisi del sentimento, ecc. Il metodo migliore per scaricare i dati di un sito Web è utilizzare la sua API di dati pubblici (la più veloce e affidabile), ma non tutti i siti Web forniscono API. A volte le API non vengono aggiornate regolarmente e potremmo perdere dati importanti.
Quindi possiamo utilizzare strumenti come Scrapy o Selenium per la scansione del Web e lo scraping in alternativa. Scrapy è un framework di scansione web gratuito e open source scritto in Python. Il modo più comune di usare scrapy è sul terminale Python e ci sono molti articoli che possono guidarti attraverso il processo.
Sebbene il processo di cui sopra sia molto popolare tra gli sviluppatori Python, non è molto intuitivo per un data scientist. C'è un modo più semplice ma impopolare per usare scrapy ie sul notebook Jupyter. Come sappiamo i notebook Python sono abbastanza nuovi e utilizzati principalmente per scopi di analisi dei dati, la creazione di funzioni scrapy sullo stesso strumento è relativamente facile e diretta.
Nozioni di base sui tag HTML
Installazione di Scrapy su Python Notebook
Il seguente blocco di codice installa e importa i pacchetti necessari per iniziare con scrapy su Python Notebook:
!pip install scrapy
import scrapy
da scrapy.crawler import CrawlerRunner
!pip installa uncinetto
dalla configurazione di importazione all'uncinetto
impostare()
richieste di importazione
da scrapy.http importa TextResponse
Crawler Runner verrà utilizzato per eseguire il ragno che creiamo. TextResponse funziona come una shell scrapy che può essere utilizzata per raschiare un URL e analizzare i tag HTML per l'estrazione di dati dalla pagina web. Successivamente possiamo creare uno spider per automatizzare l'intero processo e raccogliere dati fino a n numero di pagine.
Crochet è impostato per gestire l' errore ReactorNotRestartable . Vediamo ora come possiamo effettivamente estrarre i dati da una pagina web utilizzando il selettore CSS e X-path. Raschieremo il sito di notizie di yahoo con la stringa di ricerca come tesla in questo come esempio. Raschieremo la pagina web per ottenere il titolo degli articoli.
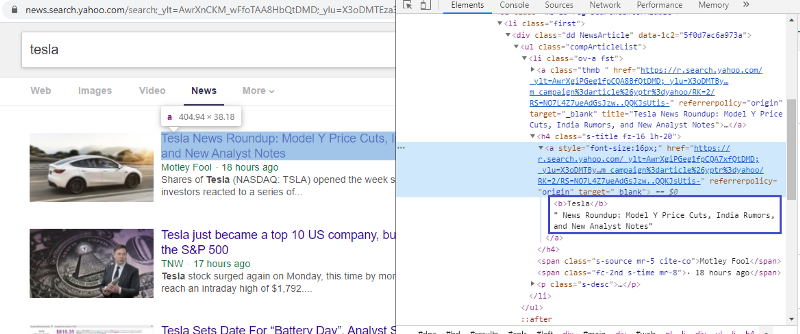
Ispeziona l'elemento per controllare il tag HTML
Fare clic con il pulsante destro del mouse sul primo collegamento e selezionare l'elemento ispeziona ci darà il risultato sopra. Possiamo vedere che il titolo fa parte della classe <a>. Useremo questo tag e proveremo ad estrarre le informazioni sul titolo su Python. Il codice seguente caricherà il sito Web di Yahoo News in un oggetto python.
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
response = TextResponse(r.url, body=r.text, encoding='utf-8')
La variabile response memorizza la pagina web in formato html. Proviamo ad estrarre informazioni usando il tag <a>. La riga di codice seguente utilizza l'estrattore CSS che utilizza il tag <a> per estrarre i titoli dalla pagina web.
response.css('a').extract()
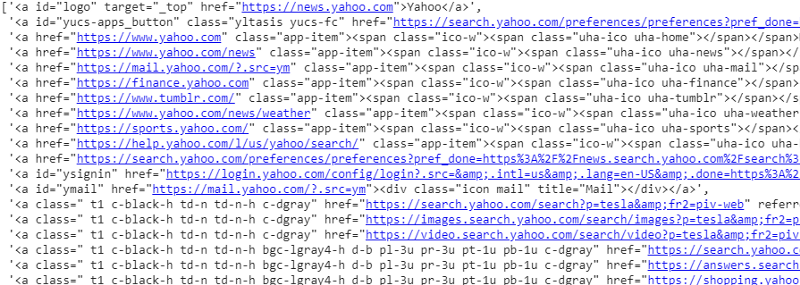
Output del selettore CSS sulla variabile di risposta
Come possiamo vedere, ci sono più di semplici dettagli sull'articolo sotto il tag <a>. Quindi il tag <a> non è in grado di estrarre correttamente i titoli. Il modo più intuitivo e preciso per ottenere tag specifici è utilizzare il gadget selettore . Dopo aver installato il gadget selettore su Chrome, possiamo usarlo per trovare i tag per qualsiasi parte specifica della pagina web che vogliamo estrarre. Di seguito possiamo vedere il tag suggerito dal Selector Gadget:
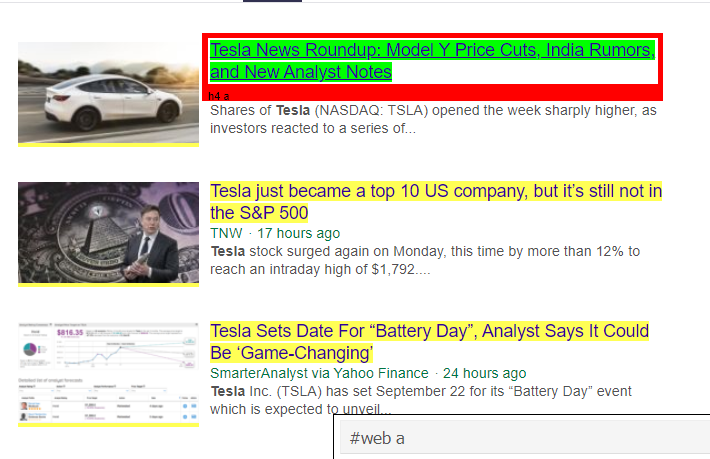
Tag HTML suggerito da Selector Gadget
Proviamo ad estrarre informazioni utilizzando il selettore '#web a'. Il codice seguente estrarrà le informazioni sul titolo utilizzando l'estrattore CSS.
response.css('#web a').extract()

Output dopo aver utilizzato il tag '#web a'
Dopo aver utilizzato il tag suggerito da Gadget Selector, otteniamo risultati più concisi utilizzando questo tag. Tuttavia, dobbiamo solo estrarre il titolo dell'articolo e lasciare altre informazioni a parte. Possiamo aggiungere il selettore X-path su questo e fare lo stesso. Il codice seguente estrarrà il testo del titolo dai tag CSS:
response.css('#web a').xpath('@title').extract()

Elenco di tutti i titoli
Come possiamo vedere siamo in grado di estrarre con successo i titoli degli articoli dal sito web di Yahoo News. Sebbene sia un po' di procedura per tentativi ed errori, possiamo sicuramente capire il flusso del processo per ridurre i tag e l'indirizzo xpath necessari per estrarre qualsiasi informazione specifica da una pagina web.
Allo stesso modo, possiamo estrarre il link, la descrizione, la data e l'editore utilizzando l'elemento ispeziona e il gadget selettore. È un processo iterativo e potrebbe richiedere del tempo per ottenere risultati desiderabili. Possiamo usare questo frammento di codice per estrarre i dati dalla pagina web di yahoo news.
title = response.css('#web a').xpath(“@title”).extract()
media = response.css('.cite-co::text').extract()
desc = response.css('ps-desc').extract()
data = response.css('#web .mr-8::text').extract()
link = response.css('h4.s-title a').xpath(“@href”).extract()
Leggi: Carriera nella scienza dei dati
Costruire il ragno
Ora sappiamo come utilizzare i tag per estrarre bit e informazioni specifiche utilizzando la variabile di risposta e l'estrattore CSS. Ora dobbiamo legarlo insieme a Scrapy Spider. Gli Scrapy Spider sono classi con una struttura predefinita costruite per eseguire la scansione e raschiare le informazioni dai siti Web. Ci sono molte cose che possono essere controllate dai ragni:
- Dati da estrarre dalle variabili di risposta.
- Strutturazione e restituzione dei dati.
- Pulizia dei dati se sono presenti informazioni indesiderate nei dati estratti.
- Possibilità di raschiare i siti web fino a un certo numero di pagina.
Quindi il ragno è essenzialmente il cuore della creazione di una funzione di raschiamento del web utilizzando Scrapy. Diamo un'occhiata più da vicino a ogni parte del ragno. La parte dei dati da estrarre è già trattata in precedenza in cui stavamo utilizzando variabili di risposta per estrarre dati specifici dalla pagina Web.
Dati di pulizia
Il blocco di codice seguente pulirà i dati della descrizione.
TAG_RE = re.compile(r'<[^>]+>') # rimozione dei tag html
j = 0
#pulizia Stringa di descrizione
per io in desc:
desc[j] = TAG_RE.sub(", i)
j = j + 1
Questo codice utilizza l'espressione regolare e rimuove i tag html indesiderati dalla descrizione degli articoli.
Prima:
<p class=”s-desc”>In una recente intervista su Motley Fool Live, co-fondatore e CEO di Motley Fool
Tom Gardner ha ricordato di aver incontrato Kendal Musk, il fratello di <b>Tesla</b> (NASDAQ: TSLA)... </p>
Dopo l'espressione regolare:
In una recente intervista su Motley Fool Live, il co-fondatore e CEO di Motley Fool Tom Gardner ha ricordato di aver incontrato Kendal Musk, il fratello di Tesla (NASDAQ: TSLA)..
Ora possiamo vedere che i tag html extra vengono rimossi dalla descrizione dell'articolo.
Strutturazione e restituzione dei dati
# Assegna saggiamente la riga del contenuto estratto

per l'elemento in zip(titolo, media, collegamento, desc, data):
# crea un dizionario per memorizzare le informazioni raschiate
scraped_info = {
'Titolo': elemento[0],
'Media': elemento[1],
'Link' : elemento[2],
'Descrizione' : articolo[3],
'Data' : elemento[4],
'Search_string' : searchstr,
'Fonte': “Yahoo News”,
}
# cedere o dare le informazioni raschiate a scrapy
resa scraped_info
I dati estratti dalle pagine web sono memorizzati in diverse variabili di elenco. Stiamo creando un dizionario che viene poi restituito al di fuori del ragno. La funzione Yield è una funzione di qualsiasi classe spider e viene utilizzata per restituire i dati alla funzione. Questi dati possono quindi essere salvati come json, csv o diversi tipi di set di dati.
Da leggere: Stipendio per data scientist in India
Navigazione verso n numero di pagine
Il blocco di codice seguente utilizza il collegamento quando si tenta di andare alla pagina successiva dei risultati sulle notizie di Yahoo. La variabile del numero di pagina viene ripetuta fino a raggiungere page_limit e per ogni numero di pagina viene creato un collegamento univoco poiché la variabile viene utilizzata nella stringa di collegamento. Il comando seguente segue quindi la nuova pagina e fornisce le informazioni da quella pagina.
Tutto sommato siamo in grado di navigare tra le pagine utilizzando un collegamento ipertestuale di base e modificare informazioni come il numero di pagina e la parola chiave. Potrebbe essere un po' complicato estrarre il collegamento ipertestuale di base per alcune pagine, ma generalmente richiede la comprensione del modello su come il collegamento viene aggiornato nelle pagine successive.
numeropagina = 1 #numero di pagina iniziale
page_limit = 5 #Pagine da raschiare
Inizializzazione URL #follow on page next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.pagenumber)+”1&pz=10&bct=0&xargs=0″
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
yield response.follow(pagina_successiva, callback=self.parse)
#navigazione alla pagina successiva
Funzione finale
Il blocco di codice seguente è la funzione finale quando viene chiamato esporterà i dati della stringa di ricerca in formato .csv.
def yahoo_news ( searchstr,lim ):
TAG_RE = rif. compile (r '<[^>]+>' ) # rimuovendo i tag html
classe MySpider ( scrapy . Spider ):
cnt = 1
nome = 'yahoonews' #nome del ragno
numero di pagina = 1 #Numero di pagina iniziale
res_limit = lim #Pagine da raschiare
parola chiave = searchstr #Stringa di ricerca
start_urls = [ “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=
“ +parola chiave+ “&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def parse ( self , response ):
#Dati da estrarre da HTML
title = response.css( '#web a' ).xpath( “@title” ).extract()
media = response.css( '.cite-co::text' ).extract()
desc = response.css( 'ps-desc' ).extract()
data = response.css( '#web .mr-8::text' ).extract()
link = response.css( 'h4.s-title a' ).xpath( “@href” ).extract()
j = 0
#pulizia Stringa di descrizione
per io in desc:
desc[j] = TAG_RE.sub( ” , i)
j = j + 1
# Assegna saggiamente la riga del contenuto estratto
per l' elemento in zip (titolo, media, link, desc, data):
# crea un dizionario per memorizzare le informazioni raschiate
scraped_info = {
'Titolo' : elemento[ 0 ],
'Media' : elemento[ 1 ],
'Link' : elemento[ 2 ],
'Descrizione' : articolo[ 3 ],
'Data' : elemento[ 4 ],
'Search_string' : searchstr,
'Fonte' : "Notizie Yahoo" ,
}
# cedere o dare le informazioni raschiate a scrapy
resa scraped_info
#follow sull'inizializzazione dell'URL della pagina
next_page= “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
“8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.keyword+ “&nojs=1&ei=” \
“UTF-8&b=” +str(MySpider.pagenumber)+ “1&pz=10&bct=0&xargs=0”
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
yield response.follow(next_page,callback= self .parse) #navigazione alla pagina successiva
if __name__ == “__main__” :
#iniziare il processo di scansione
corridore = CrawlerRunner(impostazioni={
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }, #set output nelle impostazioni
},
})
d=runner.crawl(MySpider) # lo script si bloccherà qui fino al termine della scansione
Possiamo individuare diversi blocchi di codici che sono integrati per creare lo spider. La parte principale viene effettivamente utilizzata per avviare lo spider e configurare il formato di output. Esistono diverse impostazioni che possono essere modificate per quanto riguarda il crawler. Si possono usare middleware o proxy per saltare.
runner.crawl(spider) eseguirà l'intero processo e otterremo l'output come file separato da virgole.
Produzione
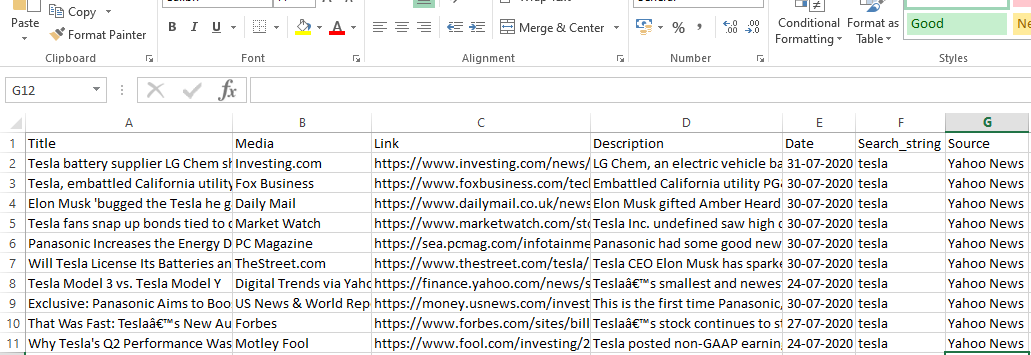
Conclusione
Ora possiamo utilizzare Scrapy come API sui notebook Python e creare spider per eseguire la scansione e raschiare diversi siti Web. Abbiamo anche esaminato come è possibile utilizzare tag e X-path diversi per accedere alle informazioni da una pagina Web.
Impara i corsi di scienza dei dati dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.
Cos'è ScRapy?
Qual è il caso d'uso reale di ScRapy?
ScRapy viene utilizzato per decidere i prezzi. Le aziende raccolgono informazioni e dati sui prezzi da siti Web concorrenti per aiutare a prendere diverse importanti decisioni aziendali. Quindi salvano e analizzano tutti i dati, apportando modifiche ai prezzi necessarie per ottimizzare vendite e profitti. Diverse aziende sono state in grado di ottenere informazioni sulla domanda di vendita stagionale raccogliendo dati dai siti della concorrenza. Hanno quindi utilizzato i dati per identificare la necessità di più strutture o personale per soddisfare la crescente domanda. ScRapy viene utilizzato anche per servizi di reclutamento, mantenimento della leadership dei costi e della logistica, creazione di directory ed eCommerce.
Come funziona ScRapy?
ScRapy utilizza l'elaborazione controllata dal tempo e dagli impulsi, il che significa che il processo di richiesta non attende la risposta e passa invece al lavoro successivo in base al tempo. Quando viene ricevuta una risposta, il processo di richiesta passa a modificare la risposta. ScRapy può svolgere facilmente compiti di grandi dimensioni. Può eseguire la scansione di un gruppo di URL in meno di un minuto, a seconda delle dimensioni del gruppo, e lo fa in modo incredibilmente rapido poiché utilizza Twister per il parallelismo, che opera in modo asincrono (non bloccante).