
데이터 과학자가 Python 노트북에서 ScRapy를 쉽게 사용하는 방법
게시 됨: 2020-11-30목차
소개
웹 스크래핑은 인터넷에서 사용 가능한 많은 양의 데이터에 액세스하는 가장 쉽고 저렴한 방법 중 하나입니다. 우리는 구조화된 데이터셋을 쉽게 구축할 수 있으며 그 데이터는 정량적 분석, 예측, 감정 분석 등에 추가로 사용할 수 있습니다. 웹사이트의 데이터를 다운로드하는 가장 좋은 방법은 공개 데이터 API(가장 빠르고 신뢰할 수 있음)를 사용하는 것이지만 전부는 아닙니다. 웹사이트는 API를 제공합니다. 때때로 API가 정기적으로 업데이트되지 않아 중요한 데이터를 놓칠 수 있습니다.
따라서 대안으로 웹 크롤링 및 스크래핑을 위해 Scrapy 또는 Selenium과 같은 도구를 사용할 수 있습니다. Scrapy는 Python으로 작성된 무료 오픈 소스 웹 크롤링 프레임워크입니다. scrapy를 사용하는 가장 일반적인 방법은 Python 터미널에 있으며 프로세스를 안내할 수 있는 많은 기사 가 있습니다.
위의 프로세스는 파이썬 개발자들 사이에서 매우 인기가 있지만 데이터 과학자에게는 그다지 직관적이지 않습니다. Jupyter 노트북에서 scrapy ie를 사용하는 더 쉽지만 인기가 없는 방법이 있습니다. Python 노트북은 상당히 새롭고 주로 데이터 분석 목적으로 사용된다는 것을 알고 있듯이 동일한 도구에서 스크랩 함수를 만드는 것은 비교적 쉽고 간단합니다.
HTML 태그의 기본
Python 노트북에 Scrapy 설치
다음 코드 블록은 Python 노트북에서 scrapy를 시작하는 데 필요한 패키지를 설치하고 가져옵니다.
! pip 설치 스크래피
수입 스크랩
scrapy.crawler에서 CrawlerRunner 가져오기
!pip 설치 크로 셰 뜨개질
크로 셰 뜨개질 가져오기 설정에서
설정()
가져오기 요청
scrapy.http에서 TextResponse 가져오기
Crawler Runner는 우리가 만든 거미를 실행하는 데 사용됩니다. TextResponse는 하나의 URL을 스크랩하고 웹 페이지에서 데이터 추출을 위한 HTML 태그를 조사하는 데 사용할 수 있는 스크랩 쉘로 작동합니다. 나중에 전체 프로세스를 자동화하고 최대 n 페이지의 데이터를 스크랩하는 스파이더를 만들 수 있습니다.
크로셰 뜨개질은 ReactorNotRestartable 오류 를 처리하도록 설정됩니다 . 이제 CSS 선택기와 X-path 를 사용하여 웹 페이지에서 실제로 데이터를 추출하는 방법을 살펴보겠습니다 . 이 예제 에서는 검색 문자열을 tesla 로 사용하여 yahoo 뉴스 사이트를 긁을 것 입니다. 우리는 기사의 제목을 얻기 위해 웹 페이지를 긁을 것입니다.
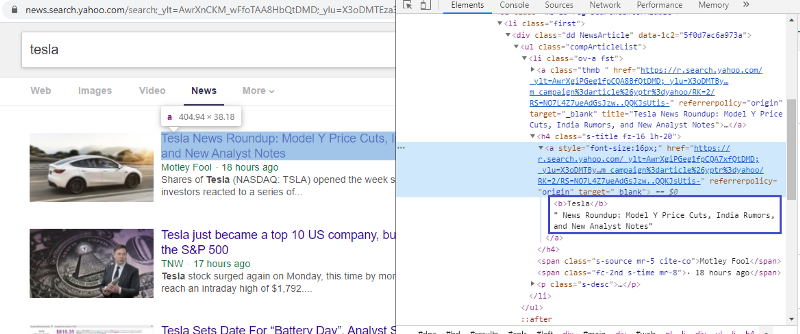
HTML 태그를 확인하기 위해 요소 검사
첫 번째 링크를 마우스 오른쪽 버튼으로 클릭하고 검사 요소를 선택하면 위의 결과가 표시됩니다. 제목이 <> 클래스의 일부임을 알 수 있습니다. 이 태그를 사용하여 파이썬에서 제목 정보를 추출하려고 합니다. 아래 코드는 Python 개체에서 Yahoo News 웹사이트를 로드합니다.
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
응답 = TextResponse(r.url, 본문=r.text, 인코딩='utf-8')
응답 변수는 웹 페이지를 html 형식으로 저장합니다. <a> 태그를 이용하여 정보를 추출해 보자. 아래 코드 라인은 <a> 태그를 사용하여 웹 페이지에서 제목을 추출하는 CSS 추출기를 사용합니다.
response.css('a').extract()
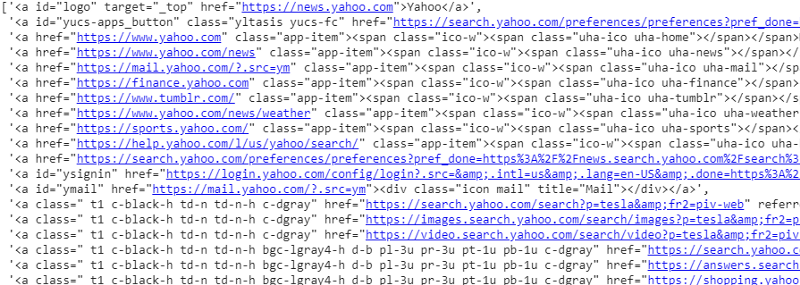
응답 변수에 대한 CSS 선택기의 출력
<a> 태그 아래에 기사 세부 정보 이상의 것이 있음을 알 수 있습니다. 따라서 <a> 태그는 제목을 제대로 추출할 수 없습니다. 특정 태그를 얻는 보다 직관적이고 정확한 방법은 선택기 가젯 을 사용하는 것 입니다. 크롬에 선택기 가젯을 설치한 후 이를 사용하여 추출하려는 웹페이지의 특정 부분에 대한 태그를 찾을 수 있습니다. 아래에서 Selector Gadget에서 제안한 태그를 볼 수 있습니다.
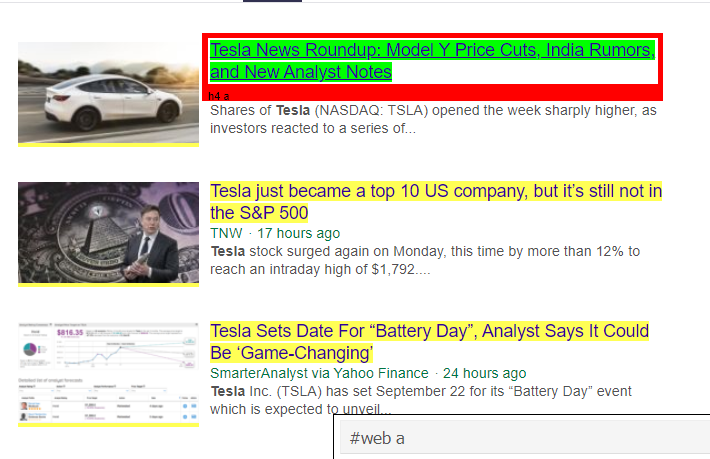
Selector Gadget에서 제안한 HTML 태그
'#web a' 선택자를 이용하여 정보를 추출해 봅시다. 아래 코드는 CSS 추출기를 사용하여 제목 정보를 추출합니다.
response.css('#웹 a').extract()

'#web a' 태그 사용 후 출력
Gadget Selector에서 제안한 태그를 사용한 후 이 태그를 사용하여 더 간결한 결과를 얻습니다. 그러나 여전히 기사의 제목 을 추출하고 다른 정보는 따로 남겨두기만 하면 됩니다. 여기에 X-경로 선택기를 추가 하고 동일한 작업을 수행할 수 있습니다. 아래 코드 는 CSS 태그에서 제목 텍스트를 추출합니다.
response.css('#web a').xpath('@title').extract()

모든 타이틀 목록
보시다시피 Yahoo News 웹사이트에서 기사 제목을 성공적으로 추출할 수 있습니다. 약간의 시행 착오 절차이지만 웹 페이지에서 특정 정보를 추출하는 데 필요한 올바른 태그와 xpath 주소로 요약되는 프로세스 흐름을 확실히 이해할 수 있습니다.
검사 요소 및 선택기 가젯을 사용하여 링크, 설명, 날짜 및 게시자를 유사하게 추출할 수 있습니다. 반복적인 프로세스이며 원하는 결과를 얻는 데 시간이 걸릴 수 있습니다. 이 코드 조각을 사용하여 야후 뉴스 웹페이지에서 데이터를 추출할 수 있습니다.
제목 = response.css('#웹 a').xpath(“@title”).extract()
미디어 = response.css('.cite-co::text').extract()
desc = 응답.css('ps-desc').extract()
날짜 = response.css('#web .mr-8::text').extract()
링크 = response.css('h4.s-title a').xpath("@href").extract()
읽기: 데이터 과학 경력
거미 만들기
이제 태그를 사용하여 응답 변수와 CSS 추출기를 사용하여 특정 비트와 정보를 추출하는 방법을 알게 되었습니다. 이제 이것을 Scrapy Spider와 함께 묶어야 합니다. Scrapy Spiders는 웹사이트에서 정보를 크롤링하고 긁어모으기 위해 구축된 미리 정의된 구조를 가진 클래스입니다. 거미가 제어할 수 있는 많은 것들이 있습니다.
- 응답 변수에서 추출할 데이터입니다.
- 데이터 구조화 및 반환.
- 추출된 데이터에 원치 않는 정보가 있는 경우 데이터를 정리합니다.
- 특정 페이지 번호까지 웹사이트 스크래핑 옵션.
따라서 스파이더는 본질적으로 Scrapy를 사용하여 웹 스크래핑 기능을 구축하는 핵심입니다. 거미의 모든 부분을 자세히 살펴보겠습니다. 추출할 데이터 부분은 이미 응답 변수를 사용하여 웹 페이지에서 특정 데이터를 추출하는 부분에 대해 설명했습니다.
청소 데이터
아래 코드 블록은 설명 데이터를 정리합니다.
TAG_RE = re.compile(r'<[^>]+>') # html 태그 제거
j = 0
#cleaning 설명 문자열
나는 설명에서:
desc[j] = TAG_RE.sub(”, i)
j = j + 1
이 코드는 정규식을 사용하고 기사 설명에서 원치 않는 html 태그를 제거합니다.
전에:
<p class=”s-desc”>Motley Fool Live의 최근 인터뷰에서 Motley Fool의 공동 설립자이자 CEO는
Tom Gardner는 <b>Tesla</b>(NASDAQ: TSLA)의 형제인 Kendal Musk와의 만남을 회상했습니다. </p>
정규식 후:
Motley Fool Live의 최근 인터뷰에서 Motley Fool의 공동 창립자이자 CEO인 Tom Gardner는 Tesla(NASDAQ: TSLA)의 형제인 Kendal Musk를 만났던 것을 회상했습니다.
이제 추가 html 태그가 기사 설명에서 제거되었음을 알 수 있습니다.
데이터 구조화 및 반환
# 추출된 내용을 row wise로 제공
zip 항목의 경우(제목, 미디어, 링크, 설명, 날짜):
# 스크랩한 정보를 저장할 사전을 만듭니다.
긁힌 정보 = {
'제목': 항목[0],
'미디어': 항목[1],
'링크': 항목[2],

'설명' : 항목[3],
'날짜' : 항목[4],
'검색 문자열': 검색 문자열,
'출처': "야후 뉴스",
}
# 스크래피에 스크랩한 정보를 양보하거나 제공
scraped_info 수율
웹 페이지에서 추출한 데이터는 다른 목록 변수에 저장됩니다. 우리는 거미 외부에서 다시 양보되는 사전을 만들고 있습니다. Yield 함수는 모든 스파이더 클래스의 함수이며 함수에 데이터를 다시 반환하는 데 사용됩니다. 이 데이터는 json, csv 또는 다른 종류의 데이터 세트로 저장할 수 있습니다.
필독: 인도의 데이터 과학자 급여
n 페이지로 이동
아래 코드 블록은 야후 뉴스 결과의 다음 페이지로 이동하려고 할 때 링크를 사용합니다. 페이지 번호 변수는 page_limit에 도달할 때까지 반복되고 모든 페이지 번호에 대해 링크 문자열에서 변수가 사용되므로 고유한 링크가 생성됩니다. 그런 다음 다음 명령은 새 페이지로 이동하여 해당 페이지에서 정보를 생성합니다.
대체로 기본 하이퍼링크를 사용하여 페이지를 탐색하고 페이지 번호 및 키워드와 같은 정보를 편집할 수 있습니다. 일부 페이지의 기본 하이퍼링크를 추출하는 것은 약간 복잡할 수 있지만 일반적으로 다음 페이지에서 링크가 업데이트되는 방식에 대한 패턴을 이해해야 합니다.
pagenumber = 1 #시작 페이지 번호
page_limit = 5 #스크레이핑할 페이지
#페이지 URL 초기화에 따라 다음_페이지=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.pagenumber=”+str(MySpider.pagenumber=)+”1
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
yield response.follow(next_page,callback=self.parse)
#다음페이지로이동
최종 기능
아래 코드 블록은 호출 시 검색 문자열의 데이터를 .csv 형식으로 내보내는 최종 함수입니다.
def yahoo_news ( searchstr,lim ):
TAG_RE = 다시. compile (r '<[^>]+>' ) # html 태그 제거
클래스 MySpider ( scrapy . Spider ):
cnt = 1
이름 = '야후뉴스' #거미의이름
페이지 번호 = 1 #시작 페이지 번호
res_limit = 림 # 스크랩할 페이지
키워드 = searchstr #검색 문자열
start_urls = [ "https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwY=aWdp
" +키워드+ "&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0" ]
def parse ( self , response ):
#HTML에서 추출할 데이터
제목 = 응답 .css( '#웹 a' ).xpath( "@제목 " ).extract()
미디어 = response.css( '.cite-co::text' ).extract()
desc = 응답 .css( 'ps-desc' ).extract()
날짜 = response.css( '#web .mr-8::text' ).extract()
링크 = response.css( 'h4.s-title a' ).xpath( "@href" ).extract()
j = 0
#cleaning 설명 문자열
나는 설명 에서 :
desc[j] = TAG_RE.sub( " , i)
j = j + 1
# 추출된 내용을 row wise로 제공
zip 항목 의 경우 (제목, 미디어, 링크, 설명, 날짜):
# 스크랩한 정보를 저장할 사전을 만듭니다.
긁힌 정보 = {
'제목' : 항목[ 0 ],
'미디어' : 항목[ 1 ],
'링크' : 항목[ 2 ],
'설명' : 항목[ 3 ],
'날짜' : 항목[ 4 ],
'검색 문자열' : 검색 문자열,
'출처' : “야후뉴스” ,
}
# 스크래피에 스크랩한 정보를 양보하거나 제공
scraped_info 수율
#페이지 URL 초기화에 따라
next_page= “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
"8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=" +MySpider.keyword+ "&nojs=1&ei=" \
"UTF-8&b=" +str(MySpider.pagenumber)+ "1&pz=10&bct=0&xargs=0"
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
yield response.follow(next_page,callback= self .parse) #다음 페이지로 이동
__name__ == "__main__" 인 경우 :
# 크롤링 프로세스 시작
러너 = CrawlerRunner(설정={
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }, #설정에서 출력 설정
},
})
d=runner.crawl(MySpider) # 크롤링이 완료될 때까지 스크립트가 여기에서 차단됩니다.
거미를 만들기 위해 통합된 다양한 코드 블록을 발견할 수 있습니다. 주요 부분은 실제로 스파이더를 시작하고 출력 형식을 구성하는 데 사용됩니다. 크롤러와 관련하여 편집할 수 있는 다양한 설정이 있습니다. 호핑을 위해 미들웨어나 프록시를 사용할 수 있습니다.
runner.crawl(spider)은 전체 프로세스를 실행하고 쉼표로 구분된 파일로 출력을 얻습니다.
산출
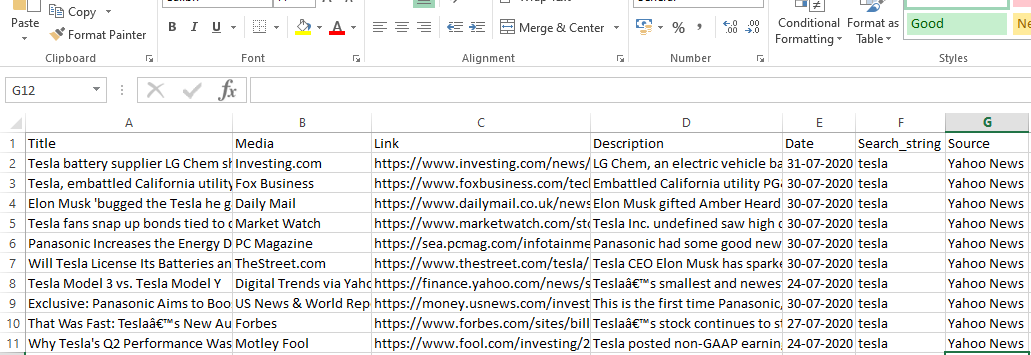
결론
이제 Scrapy를 Python 노트북의 API로 사용하고 스파이더를 만들어 다른 웹사이트를 크롤링하고 긁을 수 있습니다. 또한 다양한 태그와 X-path를 사용하여 웹 페이지에서 정보에 액세스하는 방법도 살펴보았습니다.
세계 최고의 대학에서 데이터 과학 과정 을 배우십시오 . 이그 제 큐 티브 PG 프로그램, 고급 인증 프로그램 또는 석사 프로그램을 획득하여 경력을 빠르게 추적하십시오.
ScRapy는 무엇입니까?
ScRapy의 실제 사용 사례는 무엇입니까?
ScRapy는 가격대를 결정하는 데 사용됩니다. 기업은 몇 가지 중요한 비즈니스 결정을 내리는 데 도움이 되도록 경쟁 웹사이트에서 가격 정보와 데이터를 수집합니다. 그런 다음 모든 데이터를 저장하고 분석하여 판매 및 이익을 최적화하는 데 필요한 가격 수정을 수행합니다. 여러 회사는 경쟁 사이트에서 데이터를 수집하여 계절별 판매 수요에 대한 통찰력을 얻을 수 있었습니다. 그런 다음 데이터를 활용하여 증가하는 수요를 충족하기 위해 더 많은 시설이나 인력이 필요한지 파악했습니다. ScRapy는 서비스 모집, 비용 우위 및 물류 유지, 디렉토리 구축 및 전자 상거래에도 사용됩니다.
ScRapy는 어떻게 작동합니까?
ScRapy는 시간 및 펄스 제어 처리를 사용합니다. 즉, 요청 프로세스가 응답을 기다리지 않고 시간에 따라 다음 작업으로 이동합니다. 응답이 수신되면 요청 프로세스가 응답을 변경하기 위해 이동합니다. ScRapy는 큰 작업을 쉽게 수행할 수 있습니다. 그룹의 크기에 따라 1분 이내에 URL 그룹을 크롤링할 수 있으며 비동기식(비차단)으로 작동하는 병렬 처리를 위해 Twister를 사용하기 때문에 매우 빠르게 수행합니다.