
كيف يمكن لعالم البيانات أن يستخدم ScRapy بسهولة على مفكرة بايثون
نشرت: 2020-11-30جدول المحتويات
مقدمة
يعد Web-Scraping أحد أسهل وأرخص الطرق للوصول إلى كمية كبيرة من البيانات المتاحة على الإنترنت. يمكننا بسهولة بناء مجموعات بيانات منظمة ويمكن استخدام هذه البيانات بشكل أكبر في التحليل الكمي والتنبؤ وتحليل المشاعر وما إلى ذلك. أفضل طريقة لتنزيل بيانات موقع الويب هي استخدام واجهة برمجة تطبيقات البيانات العامة (الأسرع والموثوقية) ، ولكن ليس كلها توفر مواقع الويب واجهات برمجة التطبيقات. في بعض الأحيان ، لا يتم تحديث واجهات برمجة التطبيقات بانتظام وقد نفقد بعض البيانات المهمة.
ومن ثم يمكننا استخدام أدوات مثل Scrapy أو Selenium للزحف على الويب والكشط كبديل. Scrapy هو إطار عمل مجاني ومفتوح المصدر للزحف على الويب مكتوب بلغة Python. الطريقة الأكثر شيوعًا لاستخدام scrapy هي في Python Terminal وهناك العديد من المقالات التي يمكن أن توجهك خلال هذه العملية.
على الرغم من أن العملية المذكورة أعلاه تحظى بشعبية كبيرة بين مطوري Python ، إلا أنها ليست بديهية جدًا لعالم البيانات. هناك طريقة أسهل ولكن لا تحظى بشعبية لاستخدام scrapy على سبيل المثال على دفتر Jupyter. كما نعلم ، تعد دفاتر Python المحمولة جديدة إلى حد ما وتستخدم في الغالب لأغراض تحليل البيانات ، فإن إنشاء وظائف خردة على نفس الأداة أمر سهل ومباشر نسبيًا.
أساسيات علامات HTML
تثبيت Scrapy على Python Notebook
يتم تثبيت الكتلة التالية من التعليمات البرمجية واستيراد الحزم الضرورية اللازمة لبدء استخدام scrapy على دفتر ملاحظات Python:
! pip install scrapy
استيراد سكرابى
من scrapy.crawler استيراد CrawlerRunner
! نقطة تثبيت الكروشيه
من إعداد استيراد الكروشيه
اقامة()
طلبات الاستيراد
من scrapy.http استيراد TextResponse
سيتم استخدام أداة الزاحف لتشغيل العنكبوت الذي أنشأناه. يعمل TextResponse كقذيفة خردة يمكن استخدامها لكشط عنوان URL واحد والتحقيق في علامات HTML لاستخراج البيانات من صفحة الويب. يمكننا لاحقًا إنشاء عنكبوت لأتمتة العملية بأكملها وكشط البيانات حتى عدد n من الصفحات.
تم إعداد الكروشيه للتعامل مع خطأ ReactorNotRestartable . دعونا الآن نرى كيف يمكننا بالفعل استخراج البيانات من صفحة ويب باستخدام محدد CSS و X-path. سنقوم بكشط موقع yahoo الإخباري بسلسلة البحث مثل tesla في هذا كمثال. سنقوم بكشط صفحة الويب للحصول على عنوان المقالات.
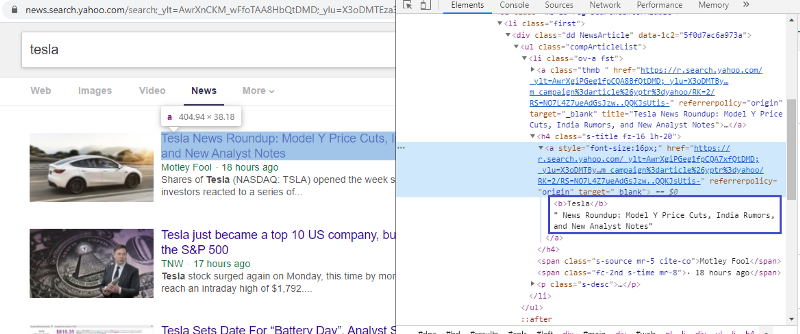
افحص العنصر للتحقق من علامة HTML
سيؤدي النقر بزر الماوس الأيمن على الرابط الأول واختيار عنصر الفحص إلى منحنا النتيجة أعلاه. يمكننا أن نرى أن العنوان جزء من <a> فئة. سنستخدم هذه العلامة ونحاول استخراج معلومات العنوان على بيثون. سيقوم الكود أدناه بتحميل موقع Yahoo News في كائن Python.
r = request.get (“https://news.search.yahoo.com/search؛_ylt=AwrXnCKM_wFfoTAA8HbQtDMD؛_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u؟ p = tesla & nojs = 1 & ei = UTF-8 & b = 01 & pz = 10 & bct = 0) & xargs = 0
الاستجابة = TextResponse (r.url ، body = r.text ، الترميز = 'utf-8 ′)
يخزن متغير الاستجابة صفحة الويب بتنسيق html. دعونا نحاول استخراج المعلومات باستخدام العلامة <a>. يستخدم سطر الكود أدناه مستخرج CSS الذي يستخدم <a> العلامة لاستخراج العناوين من صفحة الويب.
response.css ('a'). extract ()
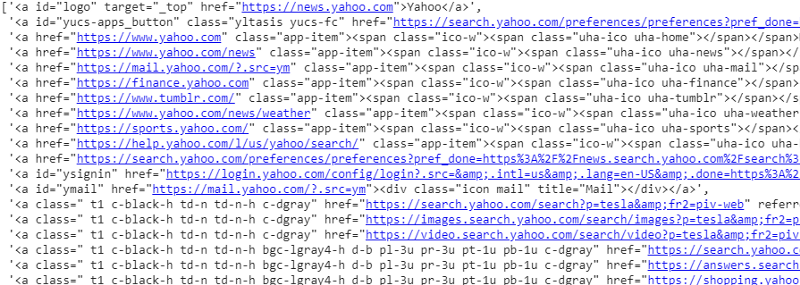
ناتج محدد CSS على متغير الاستجابة
كما نرى أن هناك أكثر من مجرد تفاصيل مقالة ضمن علامة <a>. ومن ثم فإن علامة <a> ليست قادرة بشكل صحيح على استخراج العناوين. الطريقة الأكثر دقة ودقة للحصول على علامات محددة هي استخدام أداة التحديد . بعد تثبيت أداة التحديد على الكروم ، يمكننا استخدامها للعثور على العلامات الخاصة بأجزاء معينة من صفحة الويب التي نريد استخراجها. أدناه يمكننا رؤية العلامة المقترحة بواسطة أداة التحديد:
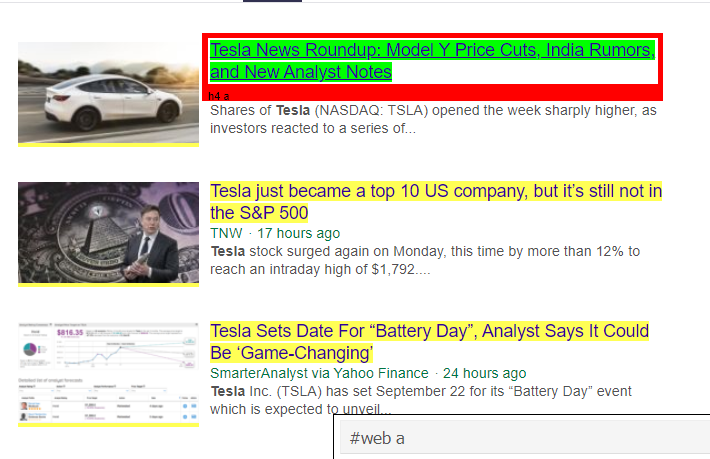
تم اقتراح علامة HTML بواسطة أداة التحديد
دعونا نحاول استخراج المعلومات باستخدام محدد "#web a". سيقوم الكود أدناه باستخراج معلومات العنوان باستخدام مستخرج CSS.
response.css ('# web a'). extract ()

الإخراج بعد استخدام وسم "#web"
بعد استخدام العلامة التي اقترحها Gadget Selector ، نحصل على نتائج أكثر إيجازًا باستخدام هذه العلامة. لكن مع ذلك ، نحتاج فقط إلى استخراج عنوان المقالة وترك المعلومات الأخرى منفصلة. يمكننا إضافة محدد المسار X على هذا والقيام بنفس الشيء. سيقوم الكود أدناه باستخراج نص العنوان من علامات CSS:
response.css ('# web a'). xpath ('@ title'). extract ()

قائمة بجميع العناوين
كما نرى ، فقد نجحنا في استخراج عناوين المقالات من موقع Yahoo News على الويب. على الرغم من أنه إجراء قليل من التجربة والخطأ ، إلا أنه يمكننا بالتأكيد فهم تدفق العملية لتلخيص العلامات الصحيحة وعنوان xpath المطلوب لاستخراج أي معلومات محددة من صفحة ويب.
يمكننا بالمثل استخراج الارتباط والوصف والتاريخ والناشر باستخدام عنصر الفحص وأداة التحديد. إنها عملية تكرارية وقد تستغرق بعض الوقت للحصول على النتائج المرغوبة. يمكننا استخدام مقتطف الشفرة هذا لاستخراج البيانات من صفحة ويب yahoo news.
title = response.css ('# web a'). xpath (“@ title”). extract ()
media = response.css ('. cite-co :: text'). extract ()
desc = response.css ('ps-desc'). extract ()
date = response.css ('# web .mr-8 :: text'). extract ()
link = response.css ('h4.s-title a'). xpath (“@ href”). extract ()
قراءة: مهنة في علم البيانات
بناء العنكبوت
نحن نعرف الآن كيفية استخدام العلامات لاستخراج أجزاء وأجزاء معينة من المعلومات باستخدام متغير الاستجابة ومستخرج css. علينا الآن ربط هذا مع Scrapy Spider. Scrapy Spiders عبارة عن فئات ذات بنية محددة مسبقًا تم إنشاؤها للزحف إلى المعلومات وكشطها من مواقع الويب. هناك العديد من الأشياء التي يمكن للعناكب السيطرة عليها:
- يتم استخراج البيانات من متغيرات الاستجابة.
- هيكلة وإرجاع البيانات.
- تنظيف البيانات في حالة وجود أجزاء غير مرغوب فيها من المعلومات في البيانات المستخرجة.
- خيار كشط المواقع حتى رقم صفحة معين.
ومن ثم فإن العنكبوت أساسًا هو قلب بناء وظيفة تجريف الويب باستخدام Scrapy. دعونا نلقي نظرة فاحصة على كل جزء من العنكبوت. تمت تغطية جزء البيانات المراد استخراجه أعلاه حيث كنا نستخدم متغيرات الاستجابة لاستخراج بيانات محددة من صفحة الويب.
تنظيف البيانات
ستقوم كتلة التعليمات البرمجية أدناه بتنظيف بيانات الوصف.
TAG_RE = re.compile (r '<[^>] +>') # إزالة علامات html
ي = 0
#cleaning سلسلة الوصف
بالنسبة لي في الوصف:
desc [j] = TAG_RE.sub ("، i)
ي = ي + 1
يستخدم هذا الرمز تعبيرًا عاديًا ويزيل علامات html غير المرغوب فيها من وصف المقالات.
قبل:
<p class = ”s-desc”> في مقابلة أجريت مؤخرًا على Motley Fool Live ، المؤسس المشارك والرئيس التنفيذي لشركة Motley Fool
استذكر توم جاردنر لقاء كيندال ماسك - شقيق <b> تسلا </ b> (NASDAQ: TSLA)… </p>
بعد Regex:
في مقابلة أجريت مؤخرًا على Motley Fool Live ، ذكر المؤسس المشارك والرئيس التنفيذي لشركة Motley Fool توم غاردنر لقاء Kendal Musk - شقيق Tesla (NASDAQ: TSLA) ..
يمكننا الآن أن نرى أنه تمت إزالة علامات html الإضافية من وصف المقالة.
هيكلة وإرجاع البيانات
# أعط صف المحتوى المستخرج حكيماً
للعنصر في ملف مضغوط (العنوان ، الوسائط ، الرابط ، الوصف ، التاريخ):
# إنشاء قاموس لتخزين المعلومات المسحوبة

scraped_info = {
"العنوان": عنصر [0] ،
"الوسائط": العنصر [1] ،
"الارتباط": العنصر [2] ،
"الوصف": العنصر [3] ،
"التاريخ": العنصر [4] ،
"سلسلة_البحث": searchstr،
"المصدر": "Yahoo News" ،
}
# إنتاج أو إعطاء المعلومات المكسورة للسكراب
العائد scraped_info
يتم تخزين البيانات المستخرجة من صفحات الويب في متغيرات قائمة مختلفة. نحن بصدد إنشاء قاموس يتم إرجاعه بعد ذلك إلى خارج العنكبوت. وظيفة المحصول هي وظيفة لأي فئة عنكبوتية وتستخدم لإعادة البيانات مرة أخرى إلى الوظيفة. يمكن بعد ذلك حفظ هذه البيانات على هيئة json أو csv أو أنواع مختلفة من مجموعة البيانات.
يجب أن تقرأ: راتب عالم البيانات في الهند
التنقل إلى عدد n من الصفحات
يستخدم جزء التعليمات البرمجية أدناه الارتباط عندما يحاول المرء الانتقال إلى الصفحة التالية من النتائج على أخبار Yahoo. يتم تكرار متغير رقم الصفحة حتى يصل حد_الصفحة ولكل رقم صفحة ، يتم إنشاء ارتباط فريد حيث يتم استخدام المتغير في سلسلة الارتباط. ثم يتبع الأمر التالي الصفحة الجديدة ويعطي المعلومات من تلك الصفحة.
بشكل عام ، نحن قادرون على التنقل بين الصفحات باستخدام ارتباط تشعبي أساسي وتحرير المعلومات مثل رقم الصفحة والكلمة الرئيسية. قد يكون استخراج الارتباط التشعبي الأساسي لبعض الصفحات معقدًا بعض الشيء ، ولكنه يتطلب عمومًا فهم النمط الخاص بكيفية تحديث الارتباط في الصفحات التالية.
رقم الصفحة = 1 # رقم صفحة البداية
page_limit = 5 # صفحات يتم كشطها
#follow on تهيئة عنوان url للصفحة next_page = ”https://news.search.yahoo.com/search؛_ylt=AwrXnCKM_wFfoTAA8HbQtDMD؛_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u؟
إذا كان (MySpider.pagenumber <MySpider.res_limit):
رقم MySpider.pagenumber + = 1
استجابة العائد. اتبع (الصفحة التالية ، رد الاتصال = تحليل الذات)
#navigation إلى الصفحة التالية
الوظيفة النهائية
كتلة التعليمات البرمجية أدناه هي الوظيفة النهائية عندما يتم استدعاؤها ستصدر بيانات سلسلة البحث بتنسيق .csv.
def yahoo_news ( searchstr ، lim ):
TAG_RE = إعادة. تجميع (r '<[^>] +>' ) # إزالة علامات html
فئة MySpider ( scrapy . Spider ):
cnt = 1
الاسم = 'yahoonews' # اسم العنكبوت
رقم الصفحة = 1 #initiating رقم الصفحة
res_limit = ليم # صفحات ليتم كشطها
الكلمة الرئيسية = searchstr # search string
start_urls = [ “https : //news.search.yahoo.com/search؛_ylt=AwrXnCKM_wFfoTAA8HbQtDMD؛_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQWNWab9
" + كلمة رئيسية + " & nojs = 1 & ei = UTF-8 & b = 01 & pz = 10 & bct = 0 & xargs = 0 " ]
تحليل def ( ذاتي ، استجابة ):
# البيانات المراد استخراجها من HTML
title = response.css ( '#web a' ) .xpath ( “title” ) .extract ()
media = response.css ( '.cite-co :: text' ) .extract ()
desc = response.css ( 'ps-desc' ) .extract ()
date = response.css ( '#web .mr-8 :: text' ) .extract ()
link = response.css ( 'h4.s-title a' ) .xpath ( “href” ) .extract ()
ي = 0
#cleaning سلسلة الوصف
بالنسبة لي في الوصف:
desc [j] = TAG_RE.sub ( " ، i)
ي = ي + 1
# أعط صف المحتوى المستخرج حكيماً
للعنصر في ملف مضغوط (العنوان ، الوسائط ، الرابط ، الوصف ، التاريخ):
# إنشاء قاموس لتخزين المعلومات المسحوبة
scraped_info = {
"العنوان" : عنصر [ 0 ] ،
"الوسائط" : العنصر [ 1 ] ،
"الارتباط" : العنصر [ 2 ] ،
"الوصف" : العنصر [ 3 ] ،
"التاريخ" : العنصر [ 4 ] ،
"سلسلة_البحث" : searchstr،
"المصدر" : "Yahoo News" ،
}
# إنتاج أو إعطاء المعلومات المكسورة للسكراب
العائد scraped_info
#follow في تهيئة عنوان url للصفحة
next_page = “https://news.search.yahoo.com/search؛_ylt=AwrXnCKM_wFfoTAA8HbQtDMD؛_ylu=X3oDMTEza3NiY3RnBGNvbG” \
"8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u؟ p =" + MySpider.keyword + "& nojs = 1 & ei =" \
"UTF-8 & b =" + str (MySpider.pagenumber) + "1 & pz = 10 & bct = 0 & xargs = 0"
إذا كان (MySpider.pagenumber <MySpider.res_limit):
رقم MySpider.pagenumber + = 1
استجابة العائد . اتبع (الصفحة التالية ، رد الاتصال = تحليل الذات ) #navigation إلى الصفحة التالية
إذا __name__ == "__main__" :
# بدء عملية الزحف
عداء = CrawlerRunner (الإعدادات = {
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }، # set output in settings
} ،
})
d = runner.crawl (MySpider) # سيتم حظر البرنامج النصي هنا حتى ينتهي الزحف
يمكننا تحديد كتل مختلفة من الأكواد المدمجة لصنع العنكبوت. يتم استخدام الجزء الرئيسي بالفعل لبدء تشغيل العنكبوت وتكوين تنسيق الإخراج. هناك العديد من الإعدادات المختلفة التي يمكن تعديلها بخصوص الزاحف. يمكن للمرء استخدام البرامج الوسيطة أو الوكلاء للتنقل.
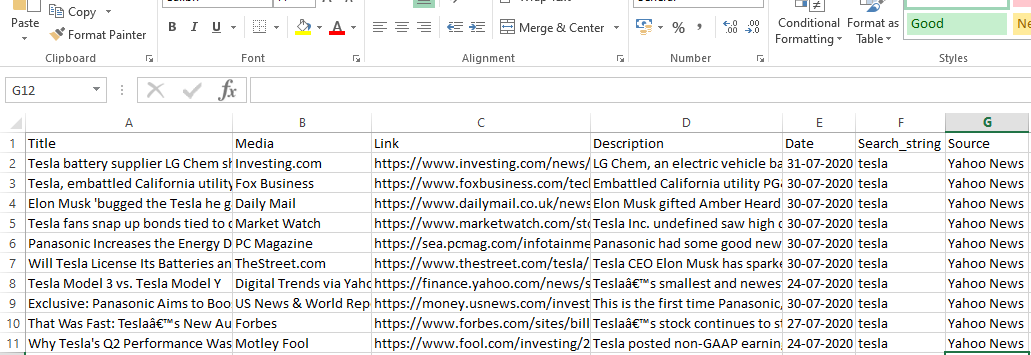
سوف ينفذ runner.crawl (العنكبوت) العملية برمتها وسنحصل على الإخراج كملف مفصول بفاصلة.
انتاج |
خاتمة
يمكننا الآن استخدام Scrapy كواجهة برمجة تطبيقات على دفاتر Python وإنشاء عناكب للزحف وكشط مواقع الويب المختلفة. نظرنا أيضًا في كيفية استخدام العلامات المختلفة ومسار X للوصول إلى المعلومات من صفحة ويب.
تعلم دورات علوم البيانات من أفضل الجامعات في العالم. اربح برامج PG التنفيذية أو برامج الشهادات المتقدمة أو برامج الماجستير لتتبع حياتك المهنية بشكل سريع.
ما هو العلاج الوقائي؟
ما هي حالة الاستخدام الواقعية لـ ScRapy؟
يستخدم ScRapy لتحديد نقاط السعر. تقوم الشركات بجمع معلومات وبيانات الأسعار من المواقع المنافسة للمساعدة في اتخاذ العديد من القرارات التجارية المهمة. ثم يقومون بحفظ وتحليل جميع البيانات وإجراء تعديلات التسعير اللازمة لتحسين المبيعات والأرباح. تمكنت العديد من الشركات من الحصول على رؤى بخصوص طلب المبيعات الموسمية من خلال جمع البيانات من مواقع المنافسين. ثم استخدموا البيانات لتحديد الحاجة إلى المزيد من المرافق أو الموظفين لتلبية الطلب المتزايد. يستخدم ScRapy أيضًا في خدمات التوظيف ، والحفاظ على قيادة التكلفة والخدمات اللوجستية ، وبناء الأدلة ، والتجارة الإلكترونية.
كيف يعمل ScRapy؟
يستخدم ScRapy معالجة يتم التحكم فيها بالوقت والنبض ، مما يعني أن عملية الطلب لا تنتظر الاستجابة وبدلاً من ذلك تنتقل إلى الوظيفة التالية وفقًا للوقت. عند تلقي رد ، تنتقل عملية الطلب لتغيير الاستجابة. يمكن لـ ScRapy القيام بمهام كبيرة دون عناء. يمكنه الزحف إلى مجموعة من عناوين URL في أقل من دقيقة ، اعتمادًا على حجم المجموعة ، ويفعل ذلك بسرعة مذهلة نظرًا لأنه يستخدم Twister للتوازي ، والذي يعمل بشكل غير متزامن (بدون حظر).