
¿Cómo puede un científico de datos usar fácilmente ScrRapy en Python Notebook?
Publicado: 2020-11-30Tabla de contenido
Introducción
Web-Scraping es una de las formas más fáciles y económicas de obtener acceso a una gran cantidad de datos disponibles en Internet. Podemos construir fácilmente conjuntos de datos estructurados y esos datos se pueden usar para análisis cuantitativos, pronósticos, análisis de sentimientos, etc. El mejor método para descargar los datos de un sitio web es usar su API de datos públicos (más rápido y confiable), pero no todos los sitios web proporcionan API. A veces, las API no se actualizan con regularidad y es posible que nos perdamos datos importantes.
Por lo tanto, podemos usar herramientas como Scrapy o Selenium para rastrear y raspar web como alternativa. Scrapy es un marco de rastreo web gratuito y de código abierto escrito en Python. La forma más común de usar scrapy es en la terminal de Python y hay muchos artículos que pueden guiarlo a través del proceso.
Aunque el proceso anterior es muy popular entre los desarrolladores de Python, no es muy intuitivo para un científico de datos. Hay una forma más fácil pero impopular de usar scrapy, es decir, en el cuaderno Jupyter. Como sabemos, los cuadernos de Python son bastante nuevos y se utilizan principalmente para fines de análisis de datos, crear funciones scrapy en la misma herramienta es relativamente fácil y directo.
Conceptos básicos de las etiquetas HTML
Instalar Scrapy en Python Notebook
El siguiente bloque de código instala e importa los paquetes necesarios para comenzar con scrapy en el cuaderno de python:
!pip instalar scrapy
importar scrapy
de scrapy.crawler importar CrawlerRunner
!pip instalar ganchillo
desde la configuración de importación de ganchillo
configuración()
solicitudes de importación
de scrapy.http importar TextResponse
Crawler Runner se utilizará para ejecutar la araña que creamos. TextResponse funciona como un caparazón scrapy que se puede usar para raspar una URL e investigar etiquetas HTML para la extracción de datos de la página web. Más tarde podemos crear una araña para automatizar todo el proceso y extraer datos hasta un número n de páginas.
Crochet está configurado para manejar el error ReactorNotRestartable . Veamos ahora cómo podemos extraer datos de una página web utilizando el selector CSS y X-path. Raspemos el sitio de noticias de yahoo con la cadena de búsqueda como tesla en esto como ejemplo. Rasparemos la página web para obtener el título de los artículos.
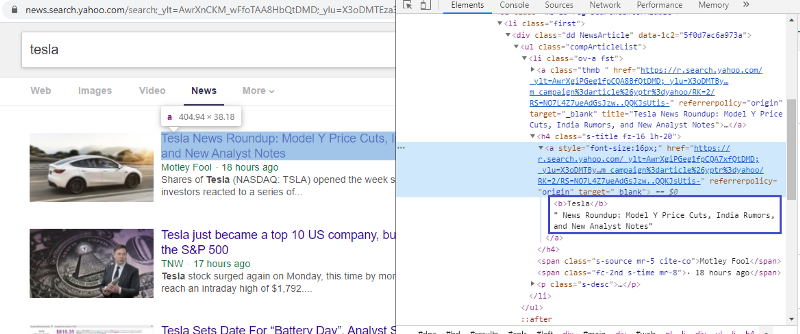
Inspeccionar elemento para comprobar la etiqueta HTML
Hacer clic derecho en el primer enlace y seleccionar el elemento de inspección nos dará el resultado anterior. Podemos ver que el título es parte de la clase <a>. Usaremos esta etiqueta e intentaremos extraer la información del título en python. El siguiente código cargará el sitio web de Yahoo News en un objeto python.
r=solicitudes.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
respuesta = TextResponse(r.url, cuerpo=r.texto, codificación='utf-8′)
La variable de respuesta almacena la página web en formato html. Intentemos extraer información usando la etiqueta <a>. La siguiente línea de código usa un extractor de CSS que usa la etiqueta <a> para extraer títulos de la página web.
respuesta.css('a').extraer()
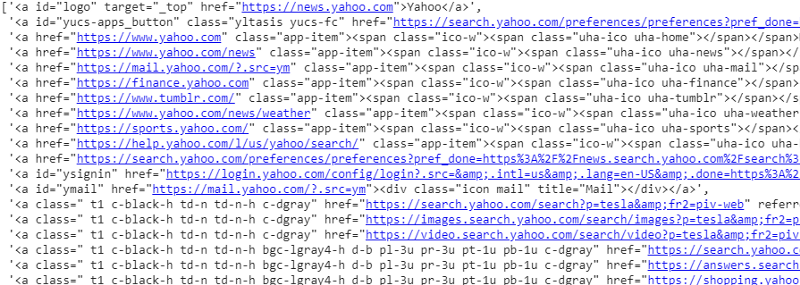
Salida del selector CSS en la variable de respuesta
Como podemos ver, hay más que solo detalles del artículo bajo la etiqueta <a>. Por lo tanto, la etiqueta <a> no puede extraer correctamente los títulos. La forma más intuitiva y precisa de obtener etiquetas específicas es mediante el uso de un dispositivo de selección . Después de instalar el gadget selector en Chrome, podemos usarlo para encontrar las etiquetas de cualquier parte específica de la página web que queremos extraer. A continuación podemos ver la etiqueta sugerida por el Selector Gadget:
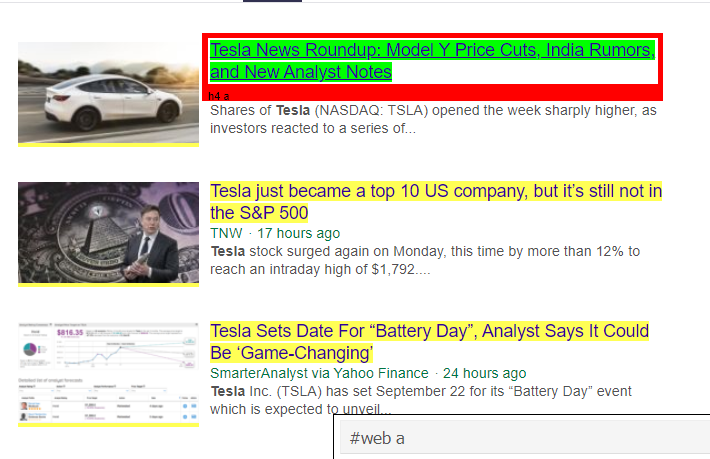
Etiqueta HTML sugerida por Selector Gadget
Intentemos extraer información usando el selector '#web a'. El siguiente código extraerá la información del título utilizando el extractor de CSS.
respuesta.css('#web a').extraer()

Salida después de usar la etiqueta '#web a'
Después de usar la etiqueta sugerida por Gadget Selector, obtenemos resultados más concisos usando esta etiqueta. Pero aún así, solo necesitamos extraer el título del artículo y dejar otra información aparte. Podemos agregar un selector de ruta X en esto y hacer lo mismo. El siguiente código extraerá el texto del título de las etiquetas CSS:
respuesta.css('#web a').xpath('@title').extract()

Lista de todos los títulos
Como podemos ver, podemos extraer con éxito los títulos de los artículos del sitio web de Yahoo News. Aunque es un poco un procedimiento de prueba y error, definitivamente podemos entender que el flujo del proceso se reduce a las etiquetas correctas y la dirección xpath requerida para extraer cualquier información específica de una página web.
De manera similar, podemos extraer el enlace, la descripción, la fecha y el editor utilizando el elemento de inspección y el gadget de selección. Es un proceso iterativo y puede llevar algún tiempo obtener resultados deseables. Podemos usar este fragmento de código para extraer los datos de la página web de noticias de Yahoo.
título = respuesta.css('#web a').xpath(“@title”).extract()
media = respuesta.css('.cite-co::text').extraer()
desc = respuesta.css('ps-desc').extract()
fecha = respuesta.css('#web .mr-8::texto').extraer()
enlace = respuesta.css('h4.s-title a').xpath(“@href”).extract()
Leer: Carrera en ciencia de datos
Construyendo la araña
Ahora sabemos cómo usar etiquetas para extraer fragmentos y piezas de información específicos usando la variable de respuesta y el extractor css. Ahora tenemos que unir esto con Scrapy Spider. Scrapy Spiders son clases con una estructura predefinida que están diseñadas para rastrear y extraer información de los sitios web. Hay muchas cosas que pueden ser controladas por las arañas:
- Datos a extraer de las variables de respuesta.
- Estructuración y Devolución de los datos.
- Limpieza de datos si hay información no deseada en los datos extraídos.
- Opción de raspar sitios web hasta cierto número de página.
Por lo tanto, la araña es esencialmente el corazón de la construcción de una función de web scraping usando Scrapy. Echemos un vistazo más de cerca a cada parte de la araña. La parte de los datos que se extraerán ya se cubrió anteriormente, donde usamos variables de respuesta para extraer datos específicos de la página web.
Limpieza de datos
El bloque de código a continuación limpiará los datos de la descripción.
TAG_RE = re.compile(r'<[^>]+>') # eliminando etiquetas html
j = 0
#Limpieza Cadena de descripción
para i en desc:
desc[j] = TAG_RE.sub(”, i)
j = j + 1
Este código utiliza expresiones regulares y elimina las etiquetas html no deseadas de la descripción de los artículos.
Antes:
<p class=”s-desc”>En una entrevista reciente en Motley Fool Live, el cofundador y director ejecutivo de Motley Fool
Tom Gardner recordó haber conocido a Kendal Musk, el hermano de <b>Tesla</b> (NASDAQ: TSLA)... </p>
Después de expresiones regulares:
En una entrevista reciente en Motley Fool Live, el cofundador y director ejecutivo de Motley Fool, Tom Gardner, recordó haber conocido a Kendal Musk, el hermano de Tesla (NASDAQ: TSLA).
Ahora podemos ver que las etiquetas html adicionales se eliminan de la descripción del artículo.
Estructuración y devolución de datos
# Dar el contenido extraído por filas

para elemento en zip (título, medio, enlace, descripción, fecha):
# crear un diccionario para almacenar la información raspada
raspado_info = {
'Título': elemento[0],
'Medios': elemento[1],
'Enlace': artículo[2],
'Descripción': elemento[3],
'Fecha': artículo[4],
'Cadena_de_búsqueda' : cadena_de_búsqueda,
'Fuente': "Noticias de Yahoo",
}
# ceder o dar la información raspada a scrapy
rendimiento scraped_info
Los datos extraídos de las páginas web se almacenan en diferentes variables de lista. Estamos creando un diccionario que luego se devuelve fuera de la araña. La función de rendimiento es una función de cualquier clase de araña y se usa para devolver datos a la función. Estos datos se pueden guardar como json, csv o diferentes tipos de conjuntos de datos.
Debe leer: Salario del científico de datos en India
Navegando a n número de páginas
El bloque de código a continuación usa el enlace cuando uno intenta ir a la siguiente página de resultados en las noticias de Yahoo. La variable de número de página se itera hasta que alcanza page_limit y para cada número de página, se crea un enlace único a medida que se usa la variable en la cadena de enlace. El siguiente comando luego sigue a la nueva página y produce la información de esa página.
En general, podemos navegar por las páginas usando un hipervínculo base y editar información como el número de página y la palabra clave. Puede ser un poco complicado extraer el hipervínculo base para algunas páginas, pero generalmente requiere comprender el patrón de cómo se actualiza el enlace en las páginas siguientes.
número de página = 1 #número de página de inicio
page_limit = 5 #Páginas para raspar
#seguir en la inicialización de la URL de la página next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.pagenumber)+”1&pz=10&bct=0&xargs=0″
if(MySpider.pagenumber < MySpider.res_limit):
MiSpider.número de página += 1
rendimiento de respuesta.seguir(siguiente_página,devolución de llamada=self.parse)
#navegación a la página siguiente
función final
El bloque de código a continuación es la función final cuando se llama, exportará los datos de la cadena de búsqueda en formato .csv.
def yahoo_news ( searchstr,lim ):
TAG_RE = re. compile (r '<[^>]+>' ) # eliminando etiquetas html
clase MySpider ( scrapy . Spider ):
ct = 1
nombre = 'yahoonoticias' #nombre de la araña
número de página = 1 #número de página de inicio
res_limit = límite #Páginas para raspar
palabra clave = searchstr #Cadena de búsqueda
start_urls = [ "https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=
“ +palabra clave+ “&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def parse ( self , respuesta ):
#Datos a extraer de HTML
título = respuesta.css( '#web a' ).xpath( “@title” ).extract()
media = respuesta.css( '.cite-co::text' ).extraer()
desc = respuesta.css( 'ps-desc' ).extract()
fecha = respuesta.css( '#web .mr-8::text' ).extract()
enlace = respuesta.css( 'h4.s-title a' ).xpath( “@href” ).extract()
j = 0
#Limpieza Cadena de descripción
para i en desc:
desc[j] = TAG_RE.sub( ” , i)
j = j + 1
# Dar el contenido extraído por filas
para elemento en zip (título, medio, enlace, descripción, fecha):
# crear un diccionario para almacenar la información raspada
raspado_info = {
'Título' : elemento[ 0 ],
'Medios' : elemento[ 1 ],
'Enlace' : elemento[ 2 ],
'Descripción' : elemento[ 3 ],
'Fecha' : elemento[ 4 ],
'Cadena_de_búsqueda' : cadena_de_búsqueda,
'Fuente' : “Yahoo News” ,
}
# ceder o dar la información raspada a scrapy
rendimiento scraped_info
#seguir en la inicialización de la URL de la página
next_page= “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
“8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.keyword+ “&nojs=1&ei=” \
“UTF-8&b=” +str(MySpider.número de página)+ “1&pz=10&bct=0&xargs=0”
if(MySpider.pagenumber < MySpider.res_limit):
MiSpider.número de página += 1
yield response.follow(next_page,callback= self .parse) #navegación a la página siguiente
si __nombre__ == “__principal__” :
#iniciar proceso de rastreo
corredor = CrawlerRunner (configuración = {
"FEEDS" : { "yahoo_output.csv" : { "formato" : "csv" }, #establecer salida en la configuración
},
})
d=runner.crawl(MySpider) # el script se bloqueará aquí hasta que finalice el rastreo
Podemos detectar diferentes bloques de códigos que se integran para hacer la araña. La parte principal en realidad se usa para poner en marcha la araña y configurar el formato de salida. Hay varias configuraciones diferentes que se pueden editar con respecto al rastreador. Uno puede usar middlewares o proxies para saltar.
runner.crawl(spider) ejecutará todo el proceso y obtendremos el resultado como un archivo separado por comas.
Producción
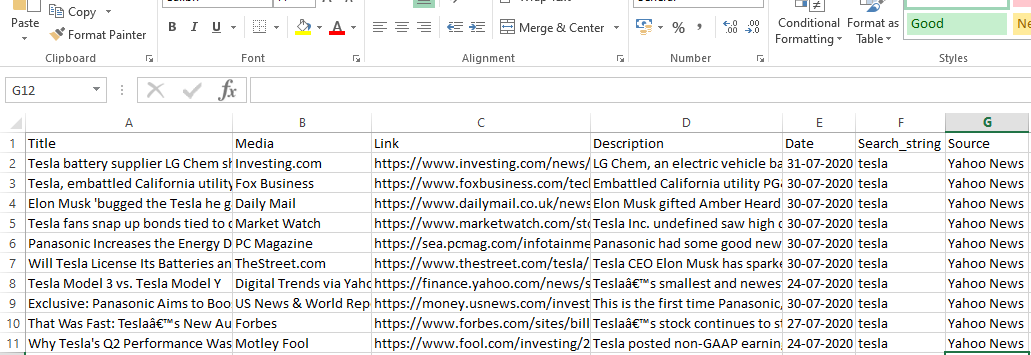
Conclusión
Ahora podemos usar Scrapy como una API en los cuadernos de Python y crear arañas para rastrear y raspar diferentes sitios web. También analizamos cómo se pueden usar diferentes etiquetas y X-path para acceder a la información de una página web.
Aprenda cursos de ciencia de datos de las mejores universidades del mundo. Obtenga programas Executive PG, programas de certificados avanzados o programas de maestría para acelerar su carrera.
¿Qué es Scrapy?
¿Cuál es el caso de uso real de ScrRapy?
Scrapy se utiliza para decidir los puntos de precio. Las empresas recopilan información de precios y datos de sitios web rivales para ayudar a tomar varias decisiones comerciales importantes. Luego guardan y analizan todos los datos, haciendo necesarias las modificaciones de precios para optimizar las ventas y las ganancias. Varias empresas han podido obtener información sobre la demanda de ventas estacionales mediante la recopilación de datos de los sitios de la competencia. Luego utilizaron los datos para identificar la necesidad de más instalaciones o personal para satisfacer la creciente demanda. ScRapy también se usa para contratar servicios, mantener el liderazgo en costos y la logística, crear directorios y comercio electrónico.
¿Cómo funciona Scrapy?
ScRapy utiliza procesamiento controlado por tiempo y pulso, lo que significa que el proceso de solicitud no espera la respuesta y, en cambio, pasa al siguiente trabajo de acuerdo con el tiempo. Cuando se recibe una respuesta, el proceso de solicitud avanza para modificar la respuesta. ScrRapy puede realizar grandes tareas sin esfuerzo. Puede rastrear un grupo de URL en menos de un minuto, según el tamaño del grupo, y lo hace increíblemente rápido, ya que utiliza Twister para el paralelismo, que funciona de forma asíncrona (sin bloqueo).