
Wie kann ein Datenwissenschaftler ScRapy einfach auf Python Notebook verwenden
Veröffentlicht: 2020-11-30Inhaltsverzeichnis
Einführung
Web-Scraping ist eine der einfachsten und billigsten Möglichkeiten, um Zugriff auf eine große Menge an Daten zu erhalten, die im Internet verfügbar sind. Wir können einfach strukturierte Datensätze erstellen und diese Daten können weiter für quantitative Analysen, Prognosen, Stimmungsanalysen usw. verwendet werden. Die beste Methode zum Herunterladen der Daten einer Website ist die Verwendung ihrer öffentlichen Daten-API (am schnellsten und zuverlässigsten), aber nicht alle Websites stellen APIs bereit. Manchmal werden die APIs nicht regelmäßig aktualisiert und uns entgehen möglicherweise wichtige Daten.
Daher können wir alternativ Tools wie Scrapy oder Selenium für Web-Crawling und Scraping verwenden. Scrapy ist ein kostenloses und Open-Source-Web-Crawling-Framework, das in Python geschrieben ist. Die gebräuchlichste Methode zur Verwendung von Scrapy ist das Python-Terminal, und es gibt viele Artikel , die Sie durch den Prozess führen können.
Obwohl der obige Prozess bei Python-Entwicklern sehr beliebt ist, ist er für einen Datenwissenschaftler nicht sehr intuitiv. Es gibt eine einfachere, aber unpopuläre Möglichkeit, Scrapy auf Jupyter-Notebooks zu verwenden. Wie wir wissen, sind Python-Notebooks ziemlich neu und werden hauptsächlich für Datenanalysezwecke verwendet. Das Erstellen von Scrapy-Funktionen mit demselben Tool ist relativ einfach und unkompliziert.
Grundlagen von HTML-Tags
Installieren von Scrapy auf Python Notebook
Der folgende Codeblock installiert und importiert die erforderlichen Pakete, die für den Einstieg in Scrapy auf dem Python-Notebook erforderlich sind:
!pip installiere scheiße
schrott importieren
aus scrapy.crawler import CrawlerRunner
!pip installieren häkeln
aus Häkelimport-Setup
Einrichten()
Anfragen importieren
aus scrapy.http TextResponse importieren
Crawler Runner wird verwendet, um die von uns erstellte Spinne auszuführen. TextResponse funktioniert als Scrapy-Shell, mit dem eine URL gescrapt und HTML-Tags für die Datenextraktion von der Webseite untersucht werden können. Wir können später eine Spinne erstellen, um den gesamten Prozess zu automatisieren und Daten bis zu einer Anzahl von n Seiten zu kratzen.
Crochet ist so eingerichtet, dass es den ReactorNotRestartable- Fehler behandelt. Lassen Sie uns nun sehen, wie wir mit CSS-Selektor und X-Pfad tatsächlich Daten von einer Webseite extrahieren können . Wir werden hier als Beispiel die Yahoo-News- Site mit der Suchzeichenfolge als Tesla schaben. Wir werden die Webseite durchsuchen, um den Titel der Artikel zu erhalten.
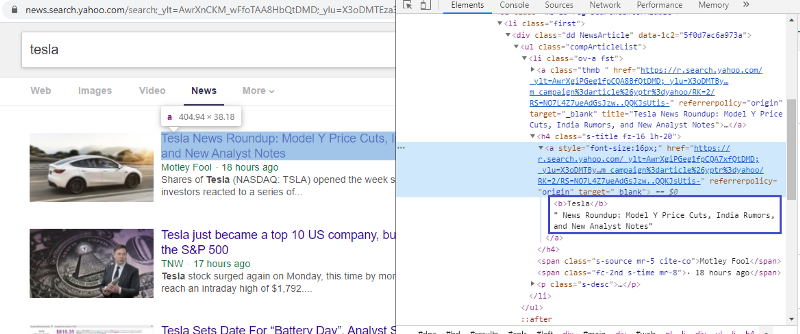
Untersuchen Sie das Element, um das HTML-Tag zu überprüfen
Klicken Sie mit der rechten Maustaste auf den ersten Link und wählen Sie das Element „Inspect“ aus, um das obige Ergebnis zu erhalten. Wir können sehen, dass der Titel Teil der Klasse <a> ist. Wir werden dieses Tag verwenden und versuchen, die Titelinformationen in Python zu extrahieren. Der folgende Code lädt die Yahoo News-Website in ein Python-Objekt.
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
Antwort = TextAntwort (r.url, body=r.text, Codierung='utf-8')
Die Antwortvariable speichert die Webseite im HTML-Format. Lassen Sie uns versuchen, Informationen mit dem Tag <a> zu extrahieren. Die folgende Codezeile verwendet den CSS-Extraktor, der das Tag <a> verwendet, um Titel von der Webseite zu extrahieren.
Antwort.css('a').extract()
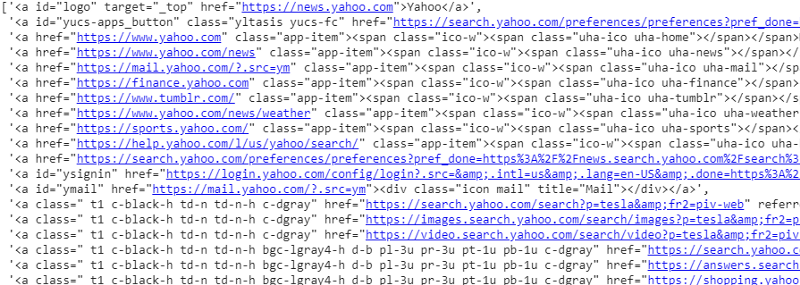
Ausgabe des CSS-Selektors auf Antwortvariable
Wie wir sehen können, gibt es mehr als nur Artikeldetails unter dem <a>-Tag. Daher ist das Tag <a> nicht in der Lage, die Titel richtig zu extrahieren. Der intuitivere und präzisere Weg, bestimmte Tags zu erhalten, ist die Verwendung des Selektor-Gadgets . Nachdem wir das Selektor-Gadget auf Chrome installiert haben, können wir es verwenden, um die Tags für bestimmte Teile der Webseite zu finden, die wir extrahieren möchten. Unten sehen wir das vom Selector Gadget vorgeschlagene Tag:
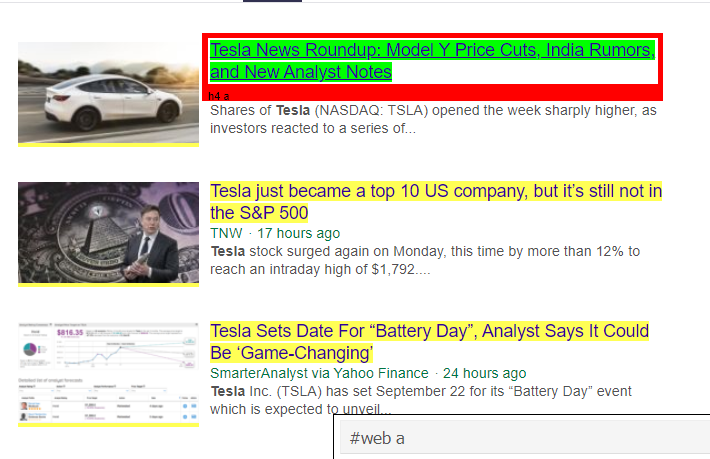
Vom Selector Gadget vorgeschlagenes HTML-Tag
Lassen Sie uns versuchen, Informationen mit dem Selektor „#web a“ zu extrahieren. Der folgende Code extrahiert die Titelinformationen mit dem CSS-Extraktor.
response.css('#web a').extract()

Ausgabe nach Verwendung des '#web a'-Tags
Nachdem wir das von Gadget Selector vorgeschlagene Tag verwendet haben, erhalten wir mit diesem Tag prägnantere Ergebnisse. Aber trotzdem müssen wir nur den Titel des Artikels extrahieren und andere Informationen beiseite lassen. Wir können den X-Pfad- Selektor hinzufügen und dasselbe tun. Der folgende Code extrahiert den Titeltext aus den CSS-Tags:
response.css('#web a').xpath('@title').extract()

Liste aller Titel
Wie wir sehen können, sind wir erfolgreich in der Lage, die Titel der Artikel von der Yahoo News-Website zu extrahieren. Obwohl es ein bisschen Trial-and-Error-Prozedur ist, können wir definitiv den Prozessablauf verstehen, der auf die richtigen Tags und xpath-Adressen reduziert wird, die erforderlich sind, um bestimmte Informationen von einer Webseite zu extrahieren.
Wir können auf ähnliche Weise den Link, die Beschreibung, das Datum und den Herausgeber extrahieren, indem wir das Inspect-Element und das Auswahl-Gadget verwenden. Es ist ein iterativer Prozess und es kann einige Zeit dauern, bis die gewünschten Ergebnisse erzielt werden. Wir können dieses Code-Snippet verwenden, um die Daten von der Yahoo News-Webseite zu extrahieren.
title = response.css('#web a').xpath(“@title”).extract()
media = response.css('.cite-co::text').extract()
desc = Antwort.css('ps-desc').extract()
date = response.css('#web .mr-8::text').extract()
link = response.css('h4.s-title a').xpath(“@href”).extract()
Lesen Sie: Karriere in der Datenwissenschaft
Aufbau der Spinne
Wir wissen jetzt, wie man Tags verwendet, um bestimmte Bits und Informationen mithilfe der Antwortvariablen und des CSS-Extraktors zu extrahieren. Das müssen wir jetzt mit Scrapy Spider aneinanderreihen. Scrapy Spiders sind Klassen mit vordefinierter Struktur, die zum Crawlen und Scrapen von Informationen von Websites erstellt wurden. Es gibt viele Dinge, die von den Spinnen gesteuert werden können:
- Aus Antwortvariablen zu extrahierende Daten.
- Strukturierung und Rückgabe der Daten.
- Bereinigen von Daten, wenn die extrahierten Daten unerwünschte Informationen enthalten.
- Option zum Scrapen von Websites bis zu einer bestimmten Seitenzahl.
Daher ist die Spinne im Wesentlichen das Herzstück beim Erstellen einer Web-Scraping-Funktion mit Scrapy. Schauen wir uns jeden Teil der Spinne genauer an. Der Teil der zu extrahierenden Daten wurde bereits oben behandelt, wo wir Antwortvariablen verwendet haben, um bestimmte Daten von der Webseite zu extrahieren.
Daten reinigen
Der folgende Codeblock bereinigt die Beschreibungsdaten.
TAG_RE = re.compile(r'<[^>]+>') # Entfernen von HTML-Tags
j = 0
#Reinigung Beschreibungszeichenfolge
für i in desc:
desc[j] = TAG_RE.sub(”, i)
j = j + 1
Dieser Code verwendet reguläre Ausdrücke und entfernt unerwünschte HTML-Tags aus der Beschreibung der Artikel.
Vor:
<p class=”s-desc”>In einem kürzlichen Interview auf Motley Fool Live, Mitbegründer und CEO von Motley Fool
Tom Gardner erinnerte sich an das Treffen mit Kendal Musk – dem Bruder von <b>Tesla</b> (NASDAQ: TSLA) … </p>
Nach Regex:
In einem kürzlichen Interview auf Motley Fool Live erinnerte sich Tom Gardner, Mitbegründer und CEO von Motley Fool, an das Treffen mit Kendal Musk – dem Bruder von Tesla (NASDAQ: TSLA).
Wir können jetzt sehen, dass die zusätzlichen HTML-Tags aus der Artikelbeschreibung entfernt wurden.

Strukturieren und Zurückgeben von Daten
# Geben Sie den extrahierten Inhalt zeilenweise an
für Artikel in ZIP (Titel, Medien, Link, Beschreibung, Datum):
# Erstellen Sie ein Wörterbuch, um die abgekratzten Informationen zu speichern
geschabte_info = {
'Titel': Artikel[0],
'Medien': item[1],
'Link' : Artikel[2],
'Beschreibung' : Artikel[3],
'Datum' : Artikel[4],
'Suchzeichenfolge' : Suchzeichenfolge,
„Quelle“: „Yahoo News“,
}
# yield oder die abgekratzten Informationen an scrapy weitergeben
Ausbeute scraped_info
Die aus den Webseiten extrahierten Daten werden in verschiedenen Listenvariablen gespeichert. Wir erstellen ein Wörterbuch, das dann außerhalb der Spinne zurückgegeben wird. Die Yield-Funktion ist eine Funktion einer beliebigen Spinnenklasse und wird verwendet, um Daten an die Funktion zurückzugeben. Diese Daten können dann als json, csv oder andere Arten von Datensätzen gespeichert werden.
Muss gelesen werden: Data Scientist Gehalt in Indien
Navigieren zu n Seiten
Der folgende Codeblock verwendet den Link, wenn versucht wird, zur nächsten Ergebnisseite der Yahoo-Nachrichten zu gelangen. Die Seitenzahlvariable wird iteriert, bis das Seitenlimit erreicht ist, und für jede Seitenzahl wird ein eindeutiger Link erstellt, da die Variable in der Linkzeichenfolge verwendet wird. Der folgende Befehl folgt dann auf die neue Seite und liefert die Informationen von dieser Seite.
Alles in allem können wir mit einem Basis-Hyperlink durch die Seiten navigieren und Informationen wie die Seitennummer und das Schlüsselwort bearbeiten. Es kann ein wenig kompliziert sein, den Basis-Hyperlink für einige Seiten zu extrahieren, aber es erfordert im Allgemeinen, das Muster zu verstehen, wie der Link auf den nächsten Seiten aktualisiert wird.
Seitennummer = 1 #initiierende Seitennummer
page_limit = 5 #zu kratzende Seiten
#follow on page URL-Initialisierung next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=“+MySpider.keyword+“&nojs=1&ei=UTF-8&b=“+str(MySpider.pagenumber)+“1&pz=10&bct=0&xargs=0″
if(MySpider.Seitennummer < MySpider.res_limit):
MySpider.Seitennummer += 1
yield response.follow(nächste_seite,callback=self.parse)
#Navigation zur nächsten Seite
Endgültige Funktion
Der folgende Codeblock ist die letzte Funktion, wenn sie aufgerufen wird, um die Daten der Suchzeichenfolge im .csv-Format zu exportieren.
def yahoo_news ( searchstr,lim ):
TAG_RE = bzgl. compile (r '<[^>]+>' ) # Entfernen von HTML-Tags
Klasse MySpider ( kratzige Spinne ) :
cnt = 1
name = 'yahoonews' #Name der Spinne
Seitenzahl = 1 #einleitende Seitenzahl
res_limit = lim #Zu kratzende Seiten
keyword = searchstr #Suchzeichenfolge
start_urls = [ „https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=
“ +Schlüsselwort+ “&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def parse ( selbst , Antwort ):
#Daten, die aus HTML extrahiert werden sollen
title = response.css( '#web a' ).xpath( „@title“ ).extract()
media = response.css( '.cite-co::text' ).extract()
desc = response.css( 'ps-desc' ).extract()
date = response.css( '#web .mr-8::text' ).extract()
link = response.css( 'h4.s-title a' ).xpath( „@href“ ).extract()
j = 0
#Reinigung Beschreibungszeichenfolge
für i in desc:
desc[j] = TAG_RE.sub( ” , i)
j = j + 1
# Geben Sie den extrahierten Inhalt zeilenweise an
für Artikel in ZIP (Titel, Medien, Link, Beschreibung, Datum):
# Erstellen Sie ein Wörterbuch, um die abgekratzten Informationen zu speichern
geschabte_info = {
'Titel' : Artikel[ 0 ],
'Medien' : Artikel[ 1 ],
'Link' : Artikel[ 2 ],
'Beschreibung' : Artikel[ 3 ],
'Datum' : Artikel[ 4 ],
'Suchzeichenfolge' : Suchzeichenfolge,
„Quelle“ : „Yahoo News“ ,
}
# yield oder die abgekratzten Informationen an scrapy weitergeben
Ausbeute scraped_info
#folgen Sie bei der Initialisierung der Seiten-URL
next_page= „https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG“ \
„8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=“ +MySpider.keyword+ „&nojs=1&ei=“ \
„UTF-8&b=“ +str(MySpider.pagenumber)+ „1&pz=10&bct=0&xargs=0“
if(MySpider.Seitennummer < MySpider.res_limit):
MySpider.Seitennummer += 1
yield response.follow(next_page,callback= self .parse) #Navigation zur nächsten Seite
wenn __name__ == „__main__“ :
#Crawling-Prozess einleiten
Läufer = CrawlerRunner (Einstellungen = {
„FEEDS“ : { „yahoo_output.csv“ : { „format“ : „csv“ }, #set Ausgabe in den Einstellungen
},
})
d=runner.crawl(MySpider) # das Skript blockiert hier, bis das Crawlen beendet ist
Wir können verschiedene Codeblöcke erkennen, die integriert sind, um die Spinne zu erstellen. Der Hauptteil wird tatsächlich verwendet, um den Spider zu starten und das Ausgabeformat zu konfigurieren. Es gibt verschiedene Einstellungen, die bezüglich des Crawlers bearbeitet werden können. Man kann Middlewares oder Proxies zum Hopping verwenden.
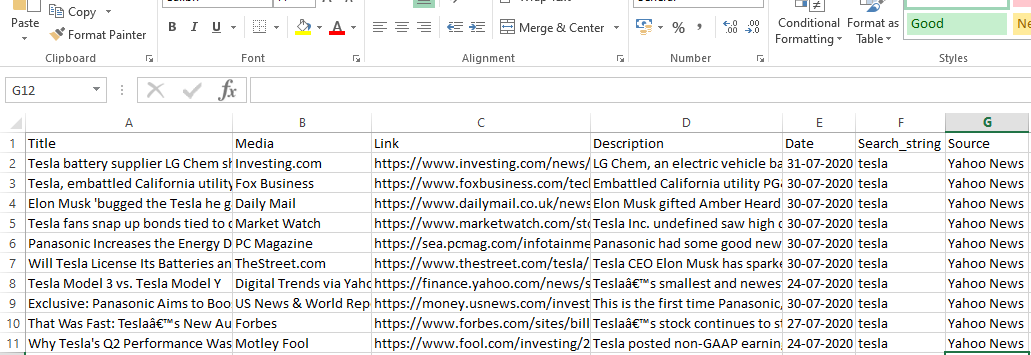
runner.crawl(spider) führt den gesamten Prozess aus und wir erhalten die Ausgabe als kommagetrennte Datei.
Ausgabe
Fazit
Wir können jetzt Scrapy als API auf Python-Notebooks verwenden und Spider erstellen, um verschiedene Websites zu crawlen und zu scrapen. Wir haben uns auch angesehen, wie verschiedene Tags und X-Pfade verwendet werden können, um auf Informationen von einer Webseite zuzugreifen.
Lernen Sie Datenwissenschaftskurse von den besten Universitäten der Welt. Verdienen Sie Executive PG-Programme, Advanced Certificate-Programme oder Master-Programme, um Ihre Karriere zu beschleunigen.
Was ist ScRapy?
Was ist der reale Anwendungsfall von ScRapy?
ScRapy wird verwendet, um über Preispunkte zu entscheiden. Firmen sammeln Preisinformationen und Daten von konkurrierenden Websites, um bei mehreren wichtigen Geschäftsentscheidungen zu helfen. Anschließend speichern und analysieren sie alle Daten und machen Preisanpassungen erforderlich, um Umsatz und Gewinn zu optimieren. Mehrere Unternehmen konnten Einblicke in die saisonale Verkaufsnachfrage gewinnen, indem sie Daten von Websites von Mitbewerbern sammelten. Anschließend nutzten sie die Daten, um den Bedarf an mehr Einrichtungen oder Personal zu ermitteln, um der wachsenden Nachfrage gerecht zu werden. ScRapy wird auch für Rekrutierungsdienste, Aufrechterhaltung der Kostenführerschaft und Logistik, Aufbau von Verzeichnissen und E-Commerce verwendet.
Wie funktioniert ScRapy?
ScRapy verwendet eine zeit- und impulsgesteuerte Verarbeitung, was bedeutet, dass der anfragende Prozess nicht auf die Antwort wartet, sondern zeitgesteuert zum nächsten Job übergeht. Wenn eine Antwort empfangen wird, geht der anfordernde Prozess weiter, um die Antwort zu ändern. ScRapy kann mühelos große Aufgaben erledigen. Es kann eine Gruppe von URLs je nach Größe der Gruppe in weniger als einer Minute crawlen, und zwar unglaublich schnell, da es Twister für Parallelität verwendet, das asynchron (nicht blockierend) arbeitet.