
Cum poate un Data Scientist să folosească cu ușurință ScRapy pe Python Notebook
Publicat: 2020-11-30Cuprins
Introducere
Web-Scraping este una dintre cele mai simple și mai ieftine modalități de a obține acces la o cantitate mare de date disponibile pe internet. Putem construi cu ușurință seturi de date structurate, iar acele date pot fi utilizate în continuare pentru analiză cantitativă, prognoză, analiză de sentiment etc. Cea mai bună metodă de a descărca datele unui site web este utilizarea API-ului de date publice (cel mai rapid și de încredere), dar nu toate site-urile web oferă API-uri. Uneori, API-urile nu sunt actualizate în mod regulat și este posibil să pierdem date importante.
Prin urmare, putem folosi instrumente precum Scrapy sau Selenium pentru crawling și scraping ca alternativă. Scrapy este un cadru de crawling web gratuit și open source, scris în Python. Cel mai comun mod de a folosi scrapy este pe terminalul Python și există multe articole care vă pot ghida prin proces.
Deși procesul de mai sus este foarte popular în rândul dezvoltatorilor Python, nu este foarte intuitiv pentru un cercetător de date. Există o modalitate mai ușoară, dar nepopulară de a folosi scrapy, adică pe notebook-ul Jupyter. După cum știm, notebook-urile Python sunt destul de noi și mai ales utilizate în scopuri de analiză a datelor, crearea de funcții scrapy pe același instrument este relativ ușoară și simplă.
Elementele de bază ale etichetelor HTML
Instalarea Scrapy pe Python Notebook
Următorul bloc de cod instalează și importă pachetele necesare pentru a începe cu scrapy pe python notebook:
!pip install scrapy
import scrapy
din scrapy.crawler import CrawlerRunner
!pip install crochet
din configurarea importului croșetat
înființat()
cereri de import
din scrapy.http import TextResponse
Crawler Runner va fi folosit pentru a rula păianjenul pe care îl creăm. TextResponse funcționează ca un shell scrapy care poate fi folosit pentru a răzui o adresă URL și a investiga etichetele HTML pentru extragerea datelor de pe pagina web. Mai târziu, putem crea un păianjen pentru a automatiza întregul proces și a răzui date până la un număr de n pagini.
Crochet este configurat pentru a gestiona eroarea ReactorNotRestartable . Să vedem acum cum putem extrage de fapt date dintr-o pagină web folosind selectorul CSS și calea X. Vom răzui site-ul de știri Yahoo cu șirul de căutare ca tesla în acest exemplu. Vom răzui pagina web pentru a obține titlul articolelor.
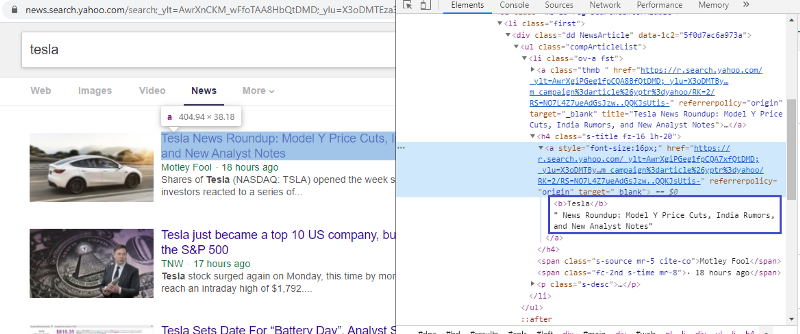
Inspectați elementul pentru a verifica eticheta HTML
Făcând clic dreapta pe primul link și selectând elementul de inspectare, vom obține rezultatul de mai sus. Putem vedea că titlul face parte din clasa <a>. Vom folosi această etichetă și vom încerca să extragem informațiile despre titlu pe python. Codul de mai jos va încărca site-ul Yahoo News într-un obiect Python.
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
răspuns = TextResponse(r.url, body=r.text, encoding='utf-8′)
Variabila răspuns stochează pagina web în format html. Să încercăm să extragem informații folosind eticheta <a>. Linia de cod de mai jos folosește extractorul CSS care utilizează eticheta <a> pentru a extrage titluri de pe pagina web.
răspuns.css('a').extract()
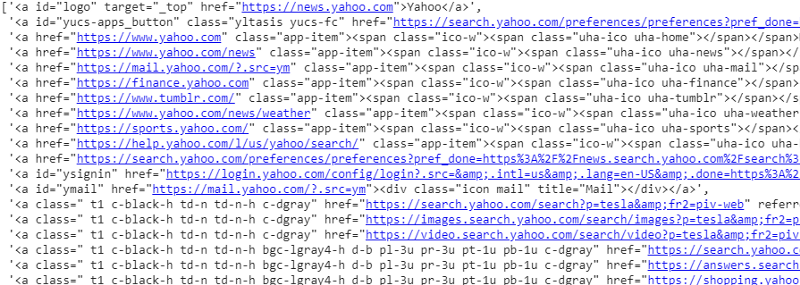
Ieșirea selectorului CSS pe variabila răspuns
După cum putem vedea că sub eticheta <a> există mai mult decât detalii despre articol. Prin urmare, eticheta <a> nu este capabilă să extragă titlurile în mod corespunzător. Modalitatea mai intuitivă și mai precisă de a obține anumite etichete este utilizarea gadgetului de selecție . După instalarea gadgetului selector pe Chrome, îl putem folosi pentru a găsi etichetele pentru orice părți specifice ale paginii web pe care dorim să le extragem. Mai jos putem vedea eticheta sugerată de Selector Gadget:
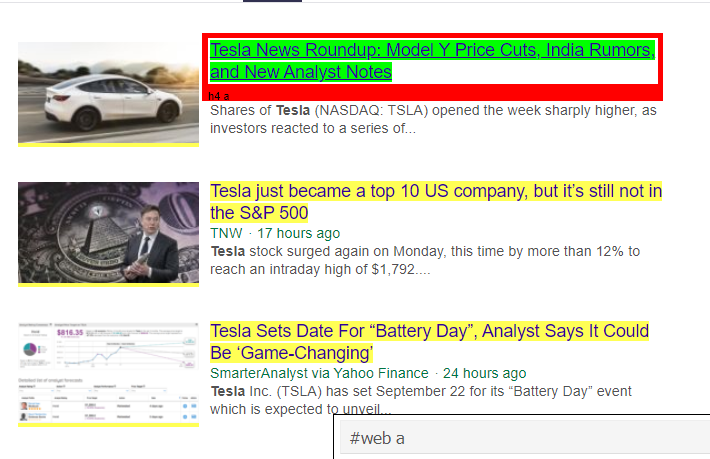
Etichetă HTML sugerată de Selector Gadget
Să încercăm să extragem informații folosind selectorul „#web a”. Codul de mai jos va extrage informațiile despre titlu folosind extractorul CSS.
response.css('#web a').extract()

Ieșire după utilizarea etichetei „#web a”.
După utilizarea etichetei sugerate de Gadget Selector, obținem rezultate mai concise folosind această etichetă. Dar totuși, trebuie doar să extragem titlul articolului și să lăsăm alte informații deoparte. Putem adăuga selectorul X-path la aceasta și facem același lucru. Codul de mai jos va extrage textul titlului din etichetele CSS:
response.css('#web a').xpath('@title').extract()

Lista tuturor titlurilor
După cum vedem, putem extrage cu succes titlurile articolelor de pe site-ul Yahoo News. Deși este o mică procedură de încercare și eroare, putem înțelege cu siguranță fluxul de proces care se reduce la etichetele corecte și adresa xpath necesare pentru a extrage orice informație specifică dintr-o pagină web.
În mod similar, putem extrage linkul, descrierea, data și editorul utilizând elementul de inspectare și gadgetul selector. Este un proces iterativ și poate dura ceva timp pentru a obține rezultatele dorite. Putem folosi acest fragment de cod pentru a extrage datele de pe pagina web de știri Yahoo.
title = response.css('#web a').xpath(“@title”).extract()
media = response.css('.cite-co::text').extract()
desc = răspuns.css('ps-desc').extract()
data = response.css('#web .mr-8::text').extract()
link = response.css('h4.s-title a').xpath(„@href”).extract()
Citiți: Carieră în știința datelor
Construirea păianjenului
Acum știm cum să folosim etichetele pentru a extrage anumite biți și informații folosind variabila răspuns și extractorul css. Acum trebuie să înșirăm asta împreună cu Scrapy Spider. Scrapy Spiders sunt clase cu structură predefinită care sunt construite pentru a accesa cu crawlere și a răzui informații de pe site-uri web. Există multe lucruri care pot fi controlate de păianjeni:
- Date care trebuie extrase din variabilele de răspuns.
- Structurarea și returnarea datelor.
- Curățarea datelor dacă există informații nedorite în datele extrase.
- Opțiunea de a răzui site-uri web până la un anumit număr de pagină.
Prin urmare, păianjenul este în esență inima construirii unei funcții de răzuire a rețelei folosind Scrapy. Să aruncăm o privire mai atentă la fiecare parte a păianjenului. Partea de date care trebuie extrasă este deja acoperită mai sus, în cazul în care am folosit variabile de răspuns pentru a extrage date specifice de pe pagina web.
Date de curățare
Blocul de cod de mai jos va curăța datele de descriere.
TAG_RE = re.compile(r'<[^>]+>') # se elimină etichetele html
j = 0
#cleaning Șir de descriere
pentru eu in desc:
desc[j] = TAG_RE.sub(”, i)
j = j + 1
Acest cod folosește expresia regulată și elimină etichetele html nedorite din descrierea articolelor.
Inainte de:
<p class="s-desc">Într-un interviu recent la Motley Fool Live, co-fondatorul și CEO-ul Motley Fool
Tom Gardner și-a amintit de întâlnirea cu Kendal Musk — fratele lui <b>Tesla</b> (NASDAQ: TSLA)... </p>
După Regex:
Într-un interviu recent la Motley Fool Live, cofondatorul și CEO-ul Motley Fool, Tom Gardner, și-a amintit de întâlnirea cu Kendal Musk – fratele Tesla (NASDAQ: TSLA).
Acum putem vedea că etichetele html suplimentare sunt eliminate din descrierea articolului.

Structurarea și returnarea datelor
# Dați conținutul extras pe rând
pentru articol în zip (titlu, media, link, descriere, dată):
# creați un dicționar pentru a stoca informațiile răzuite
scraped_info = {
„Titlu”: element[0],
„Media”: element[1],
„Link”: element[2],
„Descriere”: element[3],
„Data”: element[4],
'Search_string': searchstr,
„Sursa”: „Yahoo News”,
}
# ceda sau da informațiile răzuite la scrapy
randament scraped_info
Datele extrase din paginile web sunt stocate în diferite variabile de listă. Creăm un dicționar care este apoi returnat în afara păianjenului. Funcția de randament este o funcție a oricărei clase spider și este utilizată pentru a returna datele în funcție. Aceste date pot fi apoi salvate ca json, csv sau diferite tipuri de set de date.
Trebuie să citiți: Salariul Data Scientist în India
Navigarea la un număr de pagini
Blocul de cod de mai jos folosește linkul atunci când cineva încearcă să meargă la următoarea pagină de rezultate pe știri Yahoo. Variabila număr de pagină este repetată până când atinge limita_pagină și pentru fiecare număr de pagină este creat un link unic, deoarece variabila este utilizată în șirul de linkuri. Următoarea comandă urmează apoi către noua pagină și furnizează informațiile din pagina respectivă.
Una peste alta, suntem capabili să navigăm prin pagini folosind un hyperlink de bază și să edităm informații precum numărul paginii și cuvântul cheie. Poate fi puțin complicat să extrageți un hyperlink de bază pentru unele pagini, dar, în general, necesită înțelegerea modelului privind actualizarea linkului în paginile următoare.
pagenumber = 1 #initiating numărul paginii
page_limit = 5 #Pagini de răzuit
#follow on page url initialization next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider=MySpider).
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
randament response.follow(next_page,callback=self.parse)
#navigarea la pagina următoare
Funcția finală
Blocul de cod de mai jos este funcția finală atunci când este apelat va exporta datele șirului de căutare în format .csv.
def yahoo_news ( searchstr,lim ):
TAG_RE = re. compile (r '<[^>]+>' ) # eliminând etichetele html
clasa MySpider ( scrapy . Spider ):
cnt = 1
nume = 'yahoonews' #numele păianjenului
numărul paginii = 1 #numărul paginii inițiale
res_limit = lim #Pagini de răzuit
cuvânt cheie = searchstr #Șir de căutare
start_urls = [ „https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwNwmFpYWp9WP
„ +cuvânt cheie+ „&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def parse ( auto , răspuns ):
#Date care urmează să fie extrase din HTML
title = response.css( '#web a' ).xpath( “@title” ).extract()
media = response.css( '.cite-co::text' ).extract()
desc = răspuns.css( 'ps-desc' ).extract()
data = response.css( '#web .mr-8::text' ).extract()
link = response.css( 'h4.s-title a' ).xpath( “@href” ).extract()
j = 0
#cleaning Șir de descriere
pentru eu in desc:
desc[j] = TAG_RE.sub( ” , i)
j = j + 1
# Dați conținutul extras pe rând
pentru articol în zip (titlu, media, link, descriere, dată):
# creați un dicționar pentru a stoca informațiile răzuite
scraped_info = {
„Titlu” : element[ 0 ],
„Media” : element[ 1 ],
„Link” : articol[ 2 ],
„Descriere” : element[ 3 ],
„Data” : element[ 4 ],
'Search_string' : searchstr,
„Sursa” : „Yahoo News” ,
}
# ceda sau da informațiile răzuite la scrapy
randament scraped_info
#follow la inițializare URL a paginii
next_page= „https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
„8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.keyword+ „&nojs=1&ei=” \
„UTF-8&b=” +str(MySpider.pagenumber)+ „1&pz=10&bct=0&xargs=0”
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
randament response.follow(next_page,callback= self .parse) #navigation to the next page
if __name__ == „__main__” :
#inițiați procesul de crawling
alergător = CrawlerRunner(settings={
„FEEDS” : { „yahoo_output.csv” : { „format” : „csv” }, #set output în setări
},
})
d=runner.crawl(MySpider) # scriptul se va bloca aici până la terminarea accesării cu crawlere
Putem identifica diferite blocuri de coduri care sunt integrate pentru a face păianjen. Partea principală este de fapt folosită pentru a porni păianjenul și pentru a configura formatul de ieșire. Există diverse setări diferite care pot fi editate cu privire la crawler. Se pot folosi middleware-uri sau proxy-uri pentru salt.
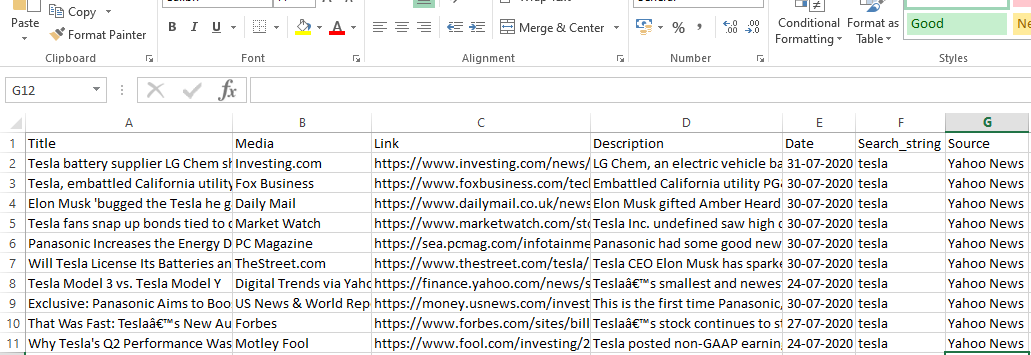
runner.crawl(spider) va executa întregul proces și vom obține rezultatul ca fișier separat prin virgulă.
Ieșire
Concluzie
Acum putem folosi Scrapy ca api pe notebook-urile Python și putem crea păianjeni pentru a accesa cu crawlere și a răzui diferite site-uri web. De asemenea, am analizat modul în care diferite etichete și X-path pot fi folosite pentru a accesa informațiile dintr-o pagină web.
Învață cursuri de știință a datelor de la cele mai bune universități din lume. Câștigă programe Executive PG, programe avansate de certificat sau programe de master pentru a-ți accelera cariera.
Ce este ScRapy?
Care este cazul de utilizare real al ScRapy?
ScRapy este folosit pentru a decide asupra punctelor de preț. Firmele colectează informații despre prețuri și date de pe site-urile web rivale pentru a ajuta la luarea mai multor decizii de afaceri importante. Apoi salvează și analizează toate datele, făcând modificări de preț necesare pentru a optimiza vânzările și profitul. Mai multe firme au reușit să obțină informații despre cererea sezonieră de vânzări prin colectarea de date de pe site-urile concurenței. Apoi au folosit datele pentru a identifica nevoia de mai multe facilități sau personal pentru a satisface cererea în creștere. ScRapy este, de asemenea, folosit pentru recrutarea de servicii, menținerea conducerii costurilor și logisticii, construirea directoarelor și comerțul electronic.
Cum funcționează ScRapy?
ScRapy folosește procesarea controlată de timp și puls, ceea ce înseamnă că procesul de solicitare nu așteaptă răspunsul, ci trece la următoarea lucrare în funcție de timp. Când se primește un răspuns, procesul de solicitare trece la modificarea răspunsului. ScRapy poate face fără efort sarcini mari. Poate accesa cu crawlere un grup de adrese URL în mai puțin de un minut, în funcție de dimensiunea grupului, și o face incredibil de rapid, deoarece utilizează Twister pentru paralelism, care funcționează asincron (neblocare).