
นักวิทยาศาสตร์ข้อมูลสามารถใช้ ScRapy บน Python Notebook ได้อย่างง่ายดายได้อย่างไร
เผยแพร่แล้ว: 2020-11-30สารบัญ
บทนำ
Web-Scraping เป็นหนึ่งในวิธีที่ง่ายและถูกที่สุดในการเข้าถึงข้อมูลจำนวนมากบนอินเทอร์เน็ต เราสามารถสร้างชุดข้อมูลที่มีโครงสร้างได้อย่างง่ายดาย และสามารถใช้ข้อมูลนั้นเพิ่มเติมสำหรับการวิเคราะห์เชิงปริมาณ การคาดการณ์ การวิเคราะห์ความคิดเห็น เป็นต้น วิธีที่ดีที่สุดในการดาวน์โหลดข้อมูลของเว็บไซต์คือการใช้ API ข้อมูลสาธารณะ (เร็วที่สุดและเชื่อถือได้) แต่ไม่ใช่ทั้งหมด เว็บไซต์ให้บริการ API บางครั้ง API ก็ไม่ได้อัปเดตเป็นประจำ และเราอาจพลาดข้อมูลสำคัญไป
ดังนั้นเราจึงสามารถใช้เครื่องมือเช่น Scrapy หรือ Selenium สำหรับการรวบรวมข้อมูลเว็บและการขูดเป็นทางเลือก Scrapy เป็นเฟรมเวิร์กการรวบรวมข้อมูลเว็บแบบโอเพนซอร์ซที่เขียนด้วยภาษา Python ฟรี วิธีที่พบบ่อยที่สุดในการใช้ scrapy คือบนเทอร์มินัล Python และมี บทความ มากมาย ที่สามารถแนะนำคุณตลอดกระบวนการ
แม้ว่ากระบวนการข้างต้นจะได้รับความนิยมอย่างมากในหมู่นักพัฒนา python แต่นักวิทยาศาสตร์ด้านข้อมูลกลับไม่ค่อยเข้าใจ มีวิธีที่ง่ายกว่าแต่ไม่เป็นที่นิยมในการใช้ scrapy ie บนโน้ตบุ๊ก Jupyter เนื่องจากเราทราบดีว่าโน้ตบุ๊ก Python ค่อนข้างใหม่และส่วนใหญ่จะใช้สำหรับการวิเคราะห์ข้อมูล การสร้างฟังก์ชันที่มีปัญหาในเครื่องมือเดียวกันนั้นค่อนข้างง่ายและตรงไปตรงมา
พื้นฐานของแท็ก HTML
การติดตั้ง Scrapy บน Python Notebook
บล็อกโค้ดต่อไปนี้จะติดตั้งและนำเข้าแพ็คเกจที่จำเป็นเพื่อเริ่มต้นใช้งาน Scrapy บนโน้ตบุ๊ก python:
!pip ติดตั้ง scrapy
นำเข้าเศษเหล็ก
จาก scrapy.crawler นำเข้า CrawlerRunner
!pip ติดตั้งโครเชต์
จากการตั้งค่าการนำเข้าโครเชต์
ติดตั้ง()
คำขอนำเข้า
จาก scrapy.http นำเข้า TextResponse
Crawler Runner จะใช้เพื่อเรียกใช้แมงมุมที่เราสร้างขึ้น TextResponse ทำงานเป็นเชลล์สแครชที่สามารถใช้ขูดหนึ่ง URL และตรวจสอบแท็ก HTML สำหรับการดึงข้อมูลจากหน้าเว็บ ในภายหลัง เราสามารถสร้างสไปเดอร์เพื่อทำให้กระบวนการทั้งหมดเป็นแบบอัตโนมัติ และขูดข้อมูลได้มากถึง n จำนวนหน้า
โครเชต์ถูกตั้งค่าเพื่อจัดการกับ ข้อผิดพลาด ReactorNotRestartable ให้เราดูว่าเราสามารถดึงข้อมูลจากหน้าเว็บโดยใช้ ตัวเลือก CSS และ X-path ได้อย่างไร เราจะขูด เว็บไซต์ ข่าว yahoo ด้วยสตริงการค้นหาเป็น tesla ในตัวอย่างนี้ เราจะขูดหน้าเว็บเพื่อรับชื่อบทความ
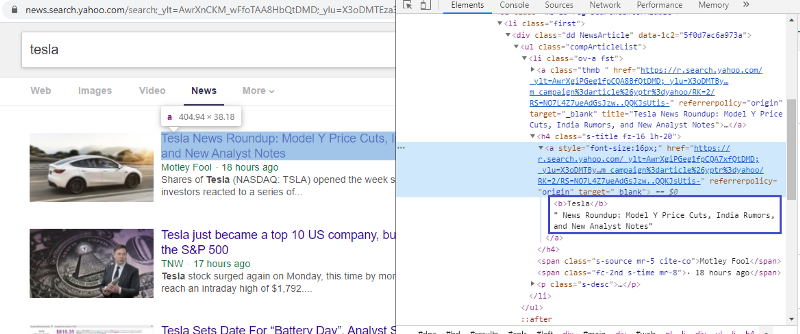
ตรวจสอบองค์ประกอบเพื่อตรวจสอบแท็ก HTML
คลิกขวาที่ลิงค์แรกและเลือกองค์ประกอบตรวจสอบจะให้ผลลัพธ์ข้างต้นแก่เรา เราจะเห็นได้ว่าชื่อนั้นเป็นส่วนหนึ่งของคลาส <a> เราจะใช้แท็กนี้และพยายามดึงข้อมูลชื่อบนหลาม รหัสด้านล่างจะโหลดเว็บไซต์ Yahoo News ในวัตถุหลาม
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=)
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
ตอบกลับ = TextResponse(r.url, body=r.text, encoding='utf-8′)
ตัวแปรตอบกลับจะจัดเก็บหน้าเว็บในรูปแบบ html ให้เราลองดึงข้อมูลโดยใช้แท็ก <a> บรรทัดโค้ดด้านล่างใช้ตัวแยก CSS ที่ใช้แท็ก <a> เพื่อแยกชื่อออกจากหน้าเว็บ
response.css('a').extract()
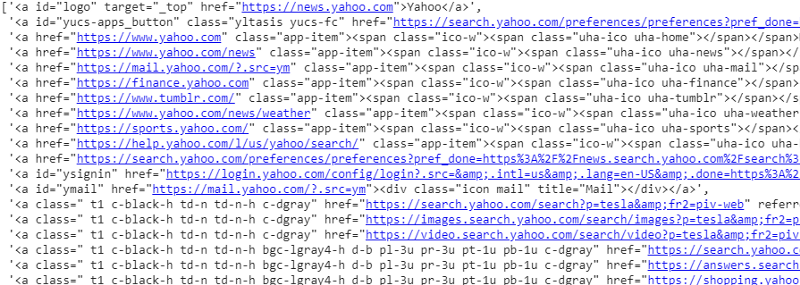
ผลลัพธ์ของตัวเลือก CSS บนตัวแปรตอบกลับ
อย่างที่เราเห็นว่ามีมากกว่ารายละเอียดบทความภายใต้แท็ก <a> ดังนั้นแท็ก <a> จึงไม่สามารถแยกชื่อได้อย่างถูกต้อง วิธีที่ง่ายกว่าและแม่นยำกว่าในการรับแท็กเฉพาะคือการใช้ selector gadget หลังจากติดตั้ง Selector gadget บน chrome แล้ว เราก็สามารถใช้มันเพื่อค้นหาแท็กสำหรับส่วนต่างๆ ของหน้าเว็บที่เราต้องการจะดึงข้อมูล ด้านล่าง เราจะเห็นแท็กที่แนะนำโดย Selector Gadget:
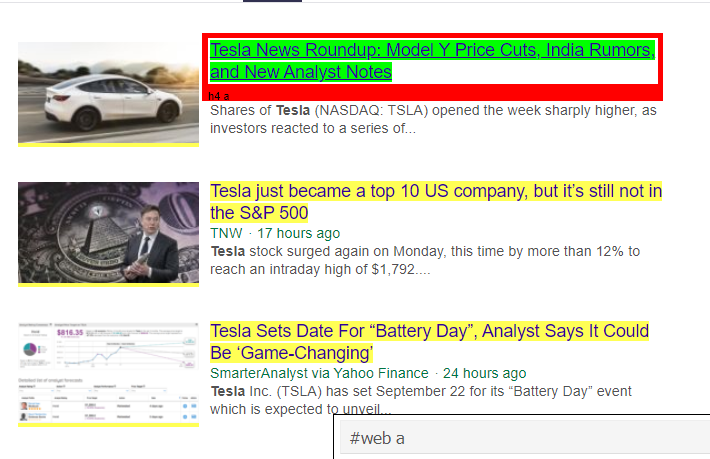
แท็ก HTML ที่แนะนำโดย Selector Gadget
ให้เราลองดึงข้อมูลโดยใช้ตัวเลือก '#web a' โค้ดด้านล่างจะดึงข้อมูลชื่อโดยใช้ตัวแยก CSS
response.css('#web a').extract()

เอาต์พุตหลังจากใช้แท็ก '#web a'
หลังจากใช้แท็กที่แนะนำโดย Gadget Selector เราก็ได้ผลลัพธ์ที่กระชับยิ่งขึ้นโดยใช้แท็กนี้ แต่เราแค่ต้องแยก ชื่อ บทความและแยกข้อมูลอื่นออกจากกัน เราสามารถเพิ่ม ตัวเลือก X-path ได้และทำเช่นเดียวกัน โค้ดด้านล่างจะดึง ข้อความ ชื่อ จากแท็ก CSS:
response.css('#web a').xpath('@title').extract()

รายชื่อชื่อเรื่องทั้งหมด
ดังที่เราเห็นแล้วว่าเราสามารถดึงชื่อบทความจากเว็บไซต์ Yahoo News ได้สำเร็จ แม้ว่าจะเป็นขั้นตอนการลองผิดลองถูกเล็กน้อย แต่เราสามารถเข้าใจโฟลว์กระบวนการเพื่อแก้ไขแท็กและที่อยู่ xpath ที่จำเป็นในการดึงข้อมูลเฉพาะใดๆ จากหน้าเว็บได้อย่างแน่นอน
ในทำนองเดียวกัน เราสามารถแยกลิงก์ คำอธิบาย วันที่ และผู้เผยแพร่ได้โดยใช้องค์ประกอบตรวจสอบและตัวเลือกแกดเจ็ต เป็นกระบวนการที่ต้องทำซ้ำๆ และอาจต้องใช้เวลาสักระยะเพื่อให้ได้ผลลัพธ์ที่ต้องการ เราสามารถใช้ข้อมูลโค้ดนี้เพื่อดึงข้อมูลจากหน้าเว็บข่าวของ yahoo
title = response.css('#web a').xpath(“@title”).extract()
สื่อ = response.css('.cite-co::text').extract()
desc = response.css('ps-desc').extract()
date = response.css('#web .mr-8::text').extract()
ลิงค์ = response.css('h4.s-title a').xpath(“@href”).extract()
อ่าน: อาชีพใน Data Science
การสร้างแมงมุม
ตอนนี้เรารู้วิธีใช้แท็กเพื่อดึงข้อมูลเฉพาะบางส่วนโดยใช้ตัวแปรตอบกลับและตัวแยก css ตอนนี้เราต้องรวมสิ่งนี้กับ Scrapy Spider Scrapy Spiders เป็นคลาสที่มีโครงสร้างที่กำหนดไว้ล่วงหน้าซึ่งสร้างขึ้นเพื่อรวบรวมข้อมูลและขูดข้อมูลจากเว็บไซต์ มีหลายสิ่งที่แมงมุมสามารถควบคุมได้:
- ข้อมูลที่จะดึงออกมาจากตัวแปรตอบสนอง
- โครงสร้างและการส่งคืนข้อมูล
- การล้างข้อมูลหากมีข้อมูลที่ไม่ต้องการในข้อมูลที่ดึงออกมา
- ตัวเลือกการขูดเว็บไซต์จนได้เลขหน้าที่กำหนด
ดังนั้นโดยพื้นฐานแล้วแมงมุมจึงเป็นหัวใจของการสร้างฟังก์ชั่นการขูดเว็บโดยใช้ Scrapy เรามาดูทุกส่วนของแมงมุมกันดีกว่า ส่วนหนึ่งของข้อมูลที่จะดึงออกมาได้อธิบายไว้ข้างต้นแล้วว่าเราใช้ตัวแปรตอบกลับเพื่อดึงข้อมูลเฉพาะออกจากหน้าเว็บ
ข้อมูลการทำความสะอาด
บล็อกโค้ดด้านล่างจะล้างข้อมูลคำอธิบาย
TAG_RE = re.compile(r'<[^>]+>') # การลบแท็ก html
เจ = 0
#cleaning คำอธิบาย string
สำหรับฉันในรายละเอียด:
desc[j] = TAG_RE.sub(”, i)
เจ = เจ + 1
รหัสนี้ใช้นิพจน์ทั่วไปและลบแท็ก html ที่ไม่ต้องการออกจากคำอธิบายของบทความ
ก่อน:
<p class=”s-desc”>ในการให้สัมภาษณ์ล่าสุดเกี่ยวกับ Motley Fool Live ผู้ร่วมก่อตั้งและ CEO ของ Motley Fool
Tom Gardner เล่าถึงการพบกับ Kendal Musk — น้องชายของ <b>Tesla</b> (NASDAQ: TSLA)… </p>
หลังจาก Regex:
ในการให้สัมภาษณ์ล่าสุดเกี่ยวกับ Motley Fool Live Tom Gardner ผู้ร่วมก่อตั้งและ CEO ของ Motley Fool เล่าถึงการพบกับ Kendal Musk น้องชายของ Tesla (NASDAQ: TSLA)
ตอนนี้เราจะเห็นแล้วว่าแท็ก html พิเศษจะถูกลบออกจากคำอธิบายบทความ
โครงสร้างและการส่งคืนข้อมูล
# ให้แถวเนื้อหาที่แยกออกมาอย่างชาญฉลาด
สำหรับรายการในไฟล์ zip (ชื่อ, สื่อ, ลิงค์, รายละเอียด, วันที่):

# สร้างพจนานุกรมเพื่อเก็บข้อมูลที่คัดลอกมา
scraped_info = {
'ชื่อ': รายการ[0],
'สื่อ': รายการ [1],
'ลิงค์' : รายการ[2],
'คำอธิบาย' : รายการ[3],
'วันที่' : รายการ[4],
'Search_string' : searchstr,
'ที่มา': “Yahoo News”,
}
# ให้ผลผลิตหรือให้ข้อมูลที่คัดลอกมาเพื่อ scrapy
ให้ผลผลิต scraped_info
ข้อมูลที่ดึงมาจากหน้าเว็บจะถูกเก็บไว้ในตัวแปรรายการต่างๆ เรากำลังสร้างพจนานุกรมซึ่งจะกลับคืนสู่ภายนอกแมงมุม ฟังก์ชัน Yield เป็นฟังก์ชันของสไปเดอร์คลาสใดๆ และใช้เพื่อส่งคืนข้อมูลกลับไปยังฟังก์ชัน ข้อมูลนี้สามารถบันทึกเป็น json, csv หรือชุดข้อมูลประเภทต่างๆ
ต้องอ่าน: เงินเดือนนักวิทยาศาสตร์ข้อมูลในอินเดีย
กำลังนำทางไปยัง n จำนวนหน้า
บล็อกโค้ดด้านล่างใช้ลิงก์เมื่อพยายามไปที่หน้าถัดไปของผลลัพธ์ใน Yahoo News ตัวแปรหมายเลขหน้าจะถูกทำซ้ำจนกว่าจะถึง page_limit และสำหรับหมายเลขหน้าทุกหมายเลข ลิงก์ที่ไม่ซ้ำจะถูกสร้างขึ้นเมื่อใช้ตัวแปรในสตริงลิงก์ คำสั่งต่อไปนี้จะติดตามไปยังหน้าใหม่และให้ข้อมูลจากหน้านั้น
โดยรวมแล้ว เราสามารถไปยังหน้าต่างๆ ได้โดยใช้ไฮเปอร์ลิงก์ฐาน และแก้ไขข้อมูล เช่น หมายเลขหน้าและคำหลัก การแยกไฮเปอร์ลิงก์พื้นฐานสำหรับบางหน้าอาจซับซ้อนเล็กน้อย แต่โดยทั่วไปต้องเข้าใจรูปแบบว่าลิงก์มีการอัปเดตในหน้าถัดไปอย่างไร
เลขหน้า = 1 #เริ่มต้นเลขหน้า
page_limit = 5 #หน้าที่จะคัดลอก
#ติดตามในหน้า URL การเริ่มต้น next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.pagenumber)=10&”1
ถ้า (MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
ให้ผลตอบสนอง.follow(next_page,callback=self.parse)
#การนำทางไปยังหน้าถัดไป
ฟังก์ชันสุดท้าย
บล็อกโค้ดด้านล่างเป็นฟังก์ชันสุดท้ายเมื่อเรียกจะส่งออกข้อมูลของสตริงการค้นหาในรูปแบบ .csv
def yahoo_news ( searchstr,lim ):
TAG_RE = อีกครั้ง คอมไพล์ (r '<[^>]+>' ) # การลบแท็ก html
คลาส MySpider ( ส ไปเดอ ร์ .
cnt = 1
ชื่อ = 'yahoonews' #ชื่อแมงมุม
เลขหน้า = 1 #เริ่มต้นเลขหน้า
res_limit = ลิ ม #หน้าที่จะขูด
คีย์เวิร์ด = searchstr #Search string
start_urls = [ “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwF0AWdpbm?
“ +คีย์เวิร์ด+ “&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def parse ( self , ตอบกลับ ):
#ข้อมูลที่จะแยกจาก HTML
title = response.css( '#web a' ).xpath( “@title” ).extract()
สื่อ = response.css( '.cite-co::text' ).extract()
desc = response.css( 'ps-desc' ).extract()
date = response.css( '#web .mr-8::text' ).extract()
ลิงค์ = response.css( 'h4.s-title a' ).xpath( “@href” ).extract()
เจ = 0
#cleaning คำอธิบาย string
สำหรับ ฉัน ใน รายละเอียด:
desc[j] = TAG_RE.sub( ” , ผม)
เจ = เจ + 1
# ให้แถวเนื้อหาที่แยกออกมาอย่างชาญฉลาด
สำหรับ รายการ ใน ไฟล์ zip (ชื่อ, สื่อ, ลิงค์, รายละเอียด, วันที่):
# สร้างพจนานุกรมเพื่อเก็บข้อมูลที่คัดลอกมา
scraped_info = {
'ชื่อ' : รายการ[ 0 ],
'สื่อ' : รายการ[ 1 ],
'ลิงค์' : รายการ[ 2 ],
'คำอธิบาย' : รายการ[ 3 ],
'วันที่' : รายการ[ 4 ],
'Search_string' : searchstr,
'ที่มา' : “ Yahoo News” ,
}
# ให้ผลผลิตหรือให้ข้อมูลที่คัดลอกมาเพื่อ scrapy
ให้ผลผลิต scraped_info
#ติดตามที่ URL การเริ่มต้นใช้งาน
next_page= “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
“8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.keyword+ “&nojs=1&ei=” \
“UTF-8&b=” +str(MySpider.pagenumber)+ “1&pz=10&bct=0&xargs=0”
ถ้า (MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
ตอบกลับ.follow( next_page ,callback= self .parse) #navigation to next page
ถ้า __name__ == “__main__” :
#เริ่มกระบวนการคลาน
รันเนอร์ = CrawlerRunner(การตั้งค่า={
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }, #set output ในการตั้งค่า
},
})
d=runner.crawl(MySpider) # สคริปต์จะบล็อกที่นี่จนกว่าการรวบรวมข้อมูลจะเสร็จสิ้น
เราสามารถมองเห็นรหัสต่างๆ ที่รวมอยู่ในการสร้างแมงมุมได้ ส่วนหลักใช้เพื่อเริ่มต้นแมงมุมและกำหนดค่ารูปแบบเอาต์พุต มีการตั้งค่าต่างๆ มากมายที่สามารถแก้ไขได้เกี่ยวกับโปรแกรมรวบรวมข้อมูล สามารถใช้มิดเดิลแวร์หรือพร็อกซีเพื่อกระโดด
runner.crawl(spider) จะดำเนินการกระบวนการทั้งหมด และเราจะได้รับผลลัพธ์เป็นไฟล์ที่คั่นด้วยเครื่องหมายจุลภาค
เอาท์พุต
บทสรุป
ตอนนี้เราสามารถใช้ Scrapy เป็น API บนโน้ตบุ๊ก Python และสร้างสไปเดอร์เพื่อรวบรวมข้อมูลและขูดเว็บไซต์ต่างๆ ได้ นอกจากนี้เรายังมองว่าแท็กและ X-path ต่างๆ สามารถใช้ในการเข้าถึงข้อมูลจากหน้าเว็บได้อย่างไร
เรียนรู้ หลักสูตรวิทยาศาสตร์ข้อมูล จากมหาวิทยาลัยชั้นนำของโลก รับโปรแกรม PG สำหรับผู้บริหาร โปรแกรมประกาศนียบัตรขั้นสูง หรือโปรแกรมปริญญาโท เพื่อติดตามอาชีพของคุณอย่างรวดเร็ว
ScRapy คืออะไร?
กรณีการใช้งานจริงของ ScRapy คืออะไร?
ScRapy ใช้เพื่อตัดสินใจเกี่ยวกับจุดราคา บริษัทรวบรวมข้อมูลราคาและข้อมูลจากเว็บไซต์ของคู่แข่งเพื่อช่วยในการตัดสินใจทางธุรกิจที่สำคัญหลายประการ จากนั้นพวกเขาจะบันทึกและวิเคราะห์ข้อมูลทั้งหมด โดยทำการปรับเปลี่ยนราคาที่จำเป็นเพื่อเพิ่มประสิทธิภาพการขายและผลกำไร หลายบริษัทสามารถรับข้อมูลเชิงลึกเกี่ยวกับความต้องการขายตามฤดูกาลได้โดยการรวบรวมข้อมูลจากเว็บไซต์ของคู่แข่ง จากนั้นพวกเขาใช้ข้อมูลเพื่อระบุความต้องการสิ่งอำนวยความสะดวกหรือบุคลากรเพิ่มเติมเพื่อตอบสนองความต้องการที่เพิ่มขึ้น ScRapy ยังใช้สำหรับการสรรหาบริการ รักษาความเป็นผู้นำด้านต้นทุนและโลจิสติกส์ การสร้างไดเรกทอรี และอีคอมเมิร์ซ
ScRapy ทำงานอย่างไร
ScRapy ใช้เวลาและการประมวลผลที่ควบคุมด้วยพัลส์ ซึ่งหมายความว่ากระบวนการร้องขอไม่รอการตอบสนอง แต่จะย้ายไปยังงานถัดไปตามเวลาแทน เมื่อได้รับการตอบกลับ กระบวนการร้องขอจะดำเนินต่อไปเพื่อแก้ไขการตอบกลับ ScRapy สามารถทำงานขนาดใหญ่ได้อย่างง่ายดาย มันสามารถรวบรวมข้อมูลกลุ่มของ URL ในเวลาไม่ถึงนาที ขึ้นอยู่กับขนาดของกลุ่ม และทำได้อย่างรวดเร็วอย่างไม่น่าเชื่อเนื่องจากใช้ Twister สำหรับการขนานกัน ซึ่งทำงานแบบอะซิงโครนัส (ไม่มีการบล็อก)