
Bir Veri Bilimcisi Python Not Defterinde ScRapy'yi Nasıl Kolayca Kullanabilir?
Yayınlanan: 2020-11-30İçindekiler
Tanıtım
Web-Scraping, internette bulunan büyük miktarda veriye erişmenin en kolay ve en ucuz yollarından biridir. Kolayca yapılandırılmış veri kümeleri oluşturabiliriz ve bu veriler Kantitatif Analiz, Tahmin, Duygu Analizi vb. için daha fazla kullanılabilir. Bir web sitesinin verilerini indirmenin en iyi yöntemi, genel veri API'sini kullanmaktır (en hızlı ve güvenilir), ancak hepsini değil web siteleri API'ler sağlar. Bazen API'ler düzenli olarak güncellenmez ve önemli verileri kaçırabiliriz.
Bu nedenle, web tarama ve kazıma için alternatif olarak Scrapy veya Selenium gibi araçları kullanabiliriz. Scrapy, Python ile yazılmış ücretsiz ve açık kaynaklı bir web tarama çerçevesidir. Scrapy kullanmanın en yaygın yolu Python terminalindedir ve süreç boyunca size rehberlik edebilecek birçok makale vardır.
Yukarıdaki süreç python geliştiricileri arasında çok popüler olmasına rağmen, bir veri bilimcisi için çok sezgisel değildir. Jupyter notebook'ta scrapy ie kullanmanın daha kolay ama popüler olmayan bir yolu var. Python not defterlerinin oldukça yeni olduğunu ve çoğunlukla veri analizi amacıyla kullanıldığını bildiğimiz için, aynı araç üzerinde scrapy işlevleri oluşturmak nispeten kolay ve basittir.
HTML etiketlerinin temelleri
Python Notebook'a Scrapy Kurulumu
Aşağıdaki kod bloğu, python notebook'ta scrapy kullanmaya başlamak için gerekli paketleri yükler ve içe aktarır:
!pip scrapy yükleyin
hurda ithal
scrapy.crawler'dan CrawlerRunner'ı içe aktarın
!pip tığ işi
kroşe ithalat kurulumundan
kurmak()
içe aktarma istekleri
scrapy.http'den TextResponse'u içe aktarın
Oluşturduğumuz örümceği çalıştırmak için Crawler Runner kullanılacaktır. TextResponse, bir URL'yi kazımak ve web sayfasından veri çıkarmak için HTML etiketlerini araştırmak için kullanılabilen bir kazıma kabuğu olarak çalışır. Daha sonra tüm süreci otomatikleştirmek ve n sayfaya kadar verileri sıyırmak için bir örümcek oluşturabiliriz .
Crochet, ReactorNotRestartable hatasını işlemek için ayarlanmıştır. Şimdi CSS seçici ve X-path kullanarak bir web sayfasından nasıl veri çıkarabileceğimizi görelim . Bu örnekte yahoo haber sitesini arama dizesiyle tesla olarak sıyıracağız . Makalelerin başlığını almak için web sayfasını kazıyacağız.
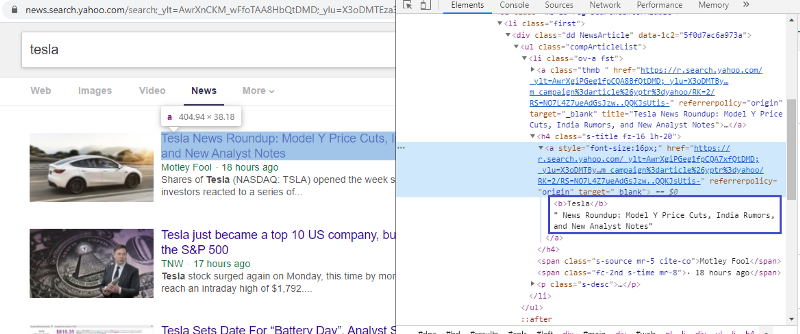
HTML etiketini kontrol etmek için öğeyi inceleyin
İlk bağlantıya sağ tıklayıp inspect öğesini seçmek bize yukarıdaki sonucu verecektir. Başlığın <a> sınıfının bir parçası olduğunu görebiliriz. Bu etiketi kullanacağız ve python üzerinde başlık bilgisini çıkarmaya çalışacağız. Aşağıdaki kod, Yahoo News web sitesini bir python nesnesine yükleyecektir.
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
yanıt = TextResponse(r.url, body=r.text, encoding='utf-8′)
Yanıt değişkeni, web sayfasını html biçiminde saklar. <a> etiketini kullanarak bilgi çıkarmaya çalışalım. Aşağıdaki kod satırı, web sayfasından başlıkları çıkarmak için <a> etiketini kullanan CSS çıkarıcıyı kullanır.
yanıt.css('a').extract()
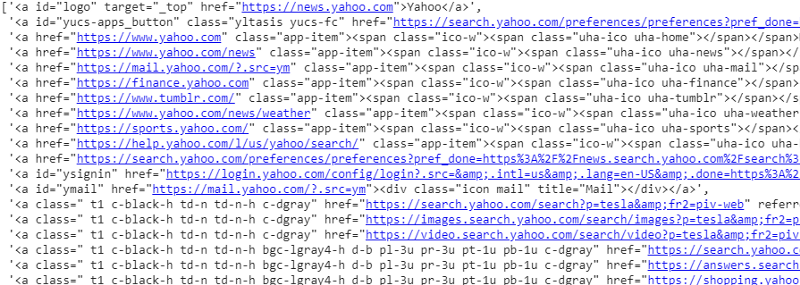
Yanıt değişkeninde CSS seçicisinin çıktısı
Gördüğümüz gibi <a> etiketinin altında sadece makale detaylarından daha fazlası var. Bu nedenle <a> etiketi başlıkları düzgün şekilde çıkaramaz. Belirli etiketleri elde etmenin daha sezgisel ve kesin yolu, seçici gadget'ı kullanmaktır . Seçici gadget'ı chrome'a yükledikten sonra, web sayfasının çıkarmak istediğimiz belirli bölümlerinin etiketlerini bulmak için kullanabiliriz. Aşağıda Selector Gadget tarafından önerilen etiketi görebiliriz:
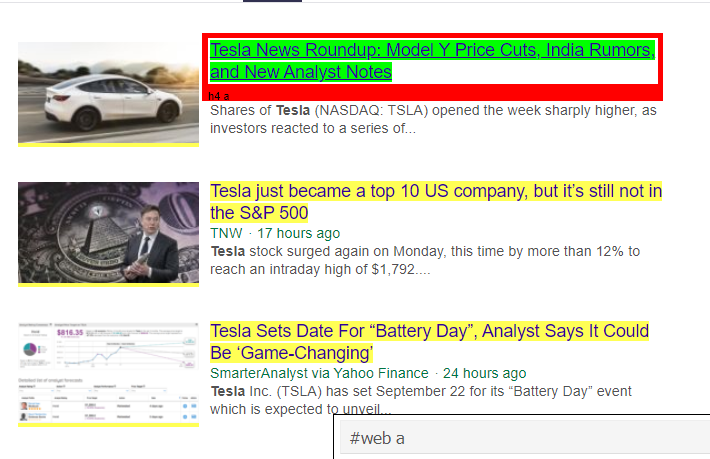
Selector Gadget tarafından önerilen HTML etiketi
'#web a' seçicisini kullanarak bilgileri çıkarmaya çalışalım. Aşağıdaki kod, CSS çıkarıcıyı kullanarak başlık bilgilerini çıkaracaktır.
answer.css('#web a').extract()

'#web a' etiketini kullandıktan sonra çıktı
Gadget Selector tarafından önerilen etiketi kullandıktan sonra, bu etiketi kullanarak daha özlü sonuçlar elde ederiz. Ama yine de, makalenin başlığını çıkarmamız ve diğer bilgileri bir kenara bırakmamız gerekiyor. Buna X-path seçici ekleyebilir ve aynısını yapabiliriz. Aşağıdaki kod, başlık metnini CSS etiketlerinden çıkaracaktır:
answer.css('#web a').xpath('@title').extract()

Tüm başlıkların listesi
Gördüğümüz gibi Yahoo News web sitesinden makalelerin başlıklarını başarıyla çıkarabiliyoruz. Biraz deneme yanılma prosedürü olsa da, bir web sayfasından herhangi bir belirli bilgiyi çıkarmak için gereken etiketleri ve xpath adresini düzeltmek için aşağı doğru kaynayan süreç akışını kesinlikle anlayabiliriz.
Benzer şekilde, inceleme öğesi ve seçici gadget'ı kullanarak bağlantıyı, açıklamayı, tarihi ve yayıncıyı ayıklayabiliriz. Bu yinelemeli bir süreçtir ve istenen sonuçların elde edilmesi biraz zaman alabilir. Verileri yahoo haber web sayfasından çıkarmak için bu kod parçacığını kullanabiliriz.
başlık = yanıt.css('#web a').xpath(“@title”).extract()
medya = answer.css('.cite-co::text').extract()
açıklama = yanıt.css('ps-desc').extract()
tarih = yanıt.css('#web .mr-8::text').extract()
link = answer.css('h4.s-title a').xpath(“@href”).extract()
Okuyun: Veri Biliminde Kariyer
Örümcek inşa etmek
Artık yanıt değişkenini ve css çıkarıcıyı kullanarak belirli bitleri ve bilgi parçalarını çıkarmak için etiketlerin nasıl kullanılacağını biliyoruz. Şimdi bunu Scrapy Spider ile birleştirmemiz gerekiyor. Scrapy Spiders, web sitelerindeki bilgileri taramak ve sıyırmak için oluşturulmuş, önceden tanımlanmış yapıya sahip sınıflardır. Örümcekler tarafından kontrol edilebilecek pek çok şey vardır:
- Yanıt değişkenlerinden çıkarılacak veriler.
- Verilerin yapılandırılması ve döndürülmesi.
- Çıkarılan verilerde istenmeyen bilgi parçaları varsa verileri temizleme.
- Belirli bir sayfa numarasına kadar web sitelerini kazıma seçeneği.
Bu nedenle örümcek, esasen Scrapy kullanarak bir ağ kazıma işlevi oluşturmanın kalbidir. Örümceğin her parçasına daha yakından bakalım. Ayıklanacak verilerin kısmı, web sayfasından belirli verileri çıkarmak için yanıt değişkenlerini kullandığımız yukarıda zaten ele alınmıştır.
temizlik verileri
Aşağıdaki kod bloğu açıklama verilerini temizleyecektir.
TAG_RE = re.compile(r'<[^>]+>') # html etiketlerini kaldırma
j = 0
#cleaning Açıklama dizesi
i için açıklama:
desc[j] = TAG_RE.sub(”, i)
j = j + 1
Bu kod, normal ifadeyi kullanır ve istenmeyen html etiketlerini makalelerin açıklamasından kaldırır.
Önce:
<p class=”s-desc”>Motley Fool'un kurucu ortağı ve CEO'su Motley Fool Live ile ilgili yakın tarihli bir röportajda
Tom Gardner, <b>Tesla</b>'ın (NASDAQ: TSLA) kardeşi Kendal Musk ile tanıştığını hatırladı… </p>
Regex'ten sonra:
Motley Fool Live'da yakın zamanda yapılan bir röportajda, Motley Fool'un kurucu ortağı ve CEO'su Tom Gardner, Tesla'nın (NASDAQ: TSLA) kardeşi Kendal Musk ile tanıştığını hatırladı.
Artık fazladan html etiketlerinin makale açıklamasından kaldırıldığını görebiliyoruz.

Verileri Yapılandırma ve Döndürme
# Çıkarılan içerik satırını akıllıca verin
Zip'deki öğe için(başlık, medya, bağlantı, açıklama, tarih):
# kazınmış bilgileri saklamak için bir sözlük oluşturun
scraped_info = {
'Başlık': öğe[0],
'Medya': öğe[1],
'Bağlantı' : madde[2],
'Açıklama' : öğe[3],
'Tarih' : madde[4],
'Search_string' : searchstr,
'Kaynak': “Yahoo Haberleri”,
}
# kazınmış bilgiyi scrapy'e verin veya verin
verim scraped_info
Web sayfalarından çıkarılan veriler farklı liste değişkenlerinde saklanır. Daha sonra örümceğin dışına çıkan bir sözlük oluşturuyoruz. Verim işlevi, herhangi bir örümcek sınıfının bir işlevidir ve verileri işleve geri döndürmek için kullanılır. Bu veriler daha sonra json, csv veya farklı türde veri kümesi olarak kaydedilebilir.
Okumalısınız: Hindistan'da Veri Bilimcisi Maaşı
n sayıda sayfaya gitme
Aşağıdaki kod bloğu, Yahoo haberlerinde bir sonraki sonuç sayfasına gitmeye çalıştığında bağlantıyı kullanır. Sayfa numarası değişkeni, page_limit değerine ulaşana kadar yinelenir ve her sayfa numarası için, değişken bağlantı dizesinde kullanıldığından benzersiz bir bağlantı oluşturulur. Aşağıdaki komut daha sonra yeni sayfayı takip eder ve o sayfadaki bilgileri verir.
Sonuç olarak, bir temel köprü kullanarak sayfalarda gezinebilir ve sayfa numarası ve anahtar kelime gibi bilgileri düzenleyebiliriz. Bazı sayfalar için temel köprüyü çıkarmak biraz karmaşık olabilir, ancak genellikle bağlantının sonraki sayfalarda nasıl güncellendiğine ilişkin kalıbın anlaşılmasını gerektirir.
sayfa numarası = 1 #başlangıç sayfa numarası
page_limit = 5 #Sayfa çıkarılacak
#follow on page url başlatma next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.1&gs=0ct”xpider.1&gs=0ct”
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.sayfa numarası += 1
verim yanıtı.follow(next_page,callback=self.parse)
#navigasyon sonraki sayfaya
Son İşlev
Aşağıdaki kod bloğu, çağrıldığında arama dizesinin verilerini .csv biçiminde dışa aktaracak son işlevdir.
def yahoo_news ( searchstr,lim ):
TAG_RE = yeniden. derleme (r '<[^>]+>' ) # html etiketlerini kaldırma
sınıf MySpider ( scrapy . Spider ):
cnt = 1
isim = 'yahoonews' #örümceğin adı
sayfa numarası = 1 #başlangıç sayfa numarası
res_limit = limit #Sıfırlanacak sayfalar
anahtar kelime = searchstr #Arama dizesi
start_urls = [ “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwY0Wap
“ +keyword+ “&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def ayrıştırma ( öz , yanıt ):
#HTML'den ayıklanacak veriler
başlık = yanıt.css( '#web a' ).xpath( “@title” ).extract()
medya = yanıt.css( '.cite-co::text' ).extract()
açıklama = yanıt.css( 'ps-desc' ).extract()
tarih = yanıt.css( '#web .mr-8::text' ).extract()
link = answer.css( 'h4.s-title a' ).xpath( “@href” ).extract()
j = 0
#cleaning Açıklama dizesi
i için açıklama :
desc[j] = TAG_RE.sub( ” , i)
j = j + 1
# Çıkarılan içerik satırını akıllıca verin
Zip'deki öğe için (başlık, medya, bağlantı, açıklama, tarih) :
# kazınmış bilgileri saklamak için bir sözlük oluşturun
scraped_info = {
'Başlık' : öğe[ 0 ],
'Medya' : öğe[ 1 ],
'Bağlantı' : öğe[ 2 ],
'Açıklama' : öğe[ 3 ],
'Tarih' : öğe[ 4 ],
'Search_string' : searchstr,
'Kaynak' : “Yahoo Haberleri” ,
}
# kazınmış bilgiyi scrapy'e verin veya verin
verim scraped_info
#sayfa url başlatmada takip et
next_page= “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
“8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.keyword+ “&nojs=1&ei=” \
“UTF-8&b=” +str(MySpider.pagenumber)+ “1&pz=10&bct=0&xargs=0”
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.sayfa numarası += 1
verim yanıtı.follow (next_page,callback= self .parse) #navigasyon sonraki sayfaya
eğer __name__ == “__main__” :
#tarama sürecini başlat
koşucu = CrawlerRunner(ayarlar={
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }, ayarlarda #set çıktısı
},
})
d=runner.crawl(MySpider) # komut dosyası tarama bitene kadar burada engellenecek
Örümceği oluşturmak için entegre edilmiş farklı kod bloklarını görebiliriz. Ana kısım aslında örümceği başlatmak ve çıktı biçimini yapılandırmak için kullanılır. Tarayıcıyla ilgili olarak düzenlenebilecek çeşitli farklı ayarlar vardır. Atlamak için ara katman yazılımları veya proxy'ler kullanılabilir.
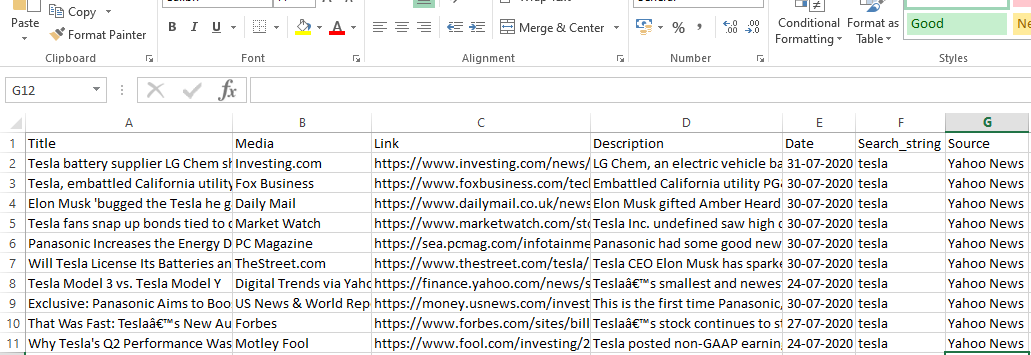
runner.crawl(spider) tüm süreci yürütecek ve çıktıyı virgülle ayrılmış bir dosya olarak alacağız.
Çıktı
Çözüm
Artık Scrapy'yi Python not defterlerinde bir api olarak kullanabilir ve farklı web sitelerini taramak ve kazımak için örümcekler oluşturabiliriz. Bir web sayfasından bilgilere erişmek için farklı etiketlerin ve X yolunun nasıl kullanılabileceğini de inceledik.
Dünyanın en iyi Üniversitelerinden veri bilimi derslerini öğrenin . Kariyerinizi hızlandırmak için Yönetici PG Programları, Gelişmiş Sertifika Programları veya Yüksek Lisans Programları kazanın.
ScRapy nedir?
ScRapy'nin gerçek hayattaki kullanım durumu nedir?
ScRapy, fiyat noktalarına karar vermek için kullanılır. Firmalar, birkaç önemli iş kararının alınmasına yardımcı olmak için rakip web sitelerinden fiyat bilgisi ve veri toplar. Daha sonra tüm verileri kaydedip analiz ederek satışları ve karı optimize etmek için gerekli fiyatlandırma değişikliklerini yaparlar. Birkaç firma, rakip sitelerden veri toplayarak sezonluk satış talebiyle ilgili içgörüler elde edebilmiştir. Ardından, artan talebi karşılamak için daha fazla tesis veya personele ihtiyaç duyulduğunu belirlemek için verileri kullandılar. ScRapy ayrıca işe alım hizmetleri, maliyet liderliği ve lojistiği sürdürme, dizin oluşturma ve e-ticaret için de kullanılır.
ScRapy nasıl çalışır?
ScRapy, zaman ve darbe kontrollü işleme kullanır; bu, talep eden sürecin yanıtı beklemediği ve bunun yerine zamana göre bir sonraki işe geçtiği anlamına gelir. Bir yanıt alındığında, talep etme süreci yanıtı değiştirmek için ilerler. ScRapy büyük görevleri zahmetsizce yapabilir. Grubun boyutuna bağlı olarak bir grup URL'yi bir dakikadan daha kısa sürede tarayabilir ve paralellik için eşzamansız (engellemesiz) çalışan Twister'ı kullandığı için bunu inanılmaz derecede hızlı yapar.