
Bagaimana Ilmuwan Data Dapat Menggunakan ScRapy dengan Mudah di Notebook Python
Diterbitkan: 2020-11-30Daftar isi
pengantar
Web-Scraping adalah salah satu cara termudah dan termurah untuk mendapatkan akses ke sejumlah besar data yang tersedia di internet. Kami dapat dengan mudah membangun kumpulan data terstruktur dan data tersebut dapat digunakan lebih lanjut untuk Analisis Kuantitatif, Peramalan, Analisis Sentimen, dll. Metode terbaik untuk mengunduh data situs web adalah dengan menggunakan API data publiknya (tercepat dan andal), tetapi tidak semua situs web menyediakan API. Terkadang API tidak diperbarui secara berkala dan kami mungkin kehilangan data penting.
Oleh karena itu, kita dapat menggunakan alat seperti Scrapy atau Selenium untuk perayapan web dan pengikisan sebagai alternatif. Scrapy adalah kerangka kerja perayapan web sumber terbuka dan gratis yang ditulis dengan Python. Cara paling umum menggunakan scrapy adalah di terminal Python dan ada banyak artikel yang dapat memandu Anda melalui prosesnya.
Meskipun proses di atas sangat populer di kalangan pengembang python, proses ini tidak terlalu intuitif bagi ilmuwan data. Ada cara yang lebih mudah tetapi tidak populer untuk menggunakan scrapy yaitu di notebook Jupyter. Seperti yang kita ketahui, notebook Python cukup baru dan sebagian besar digunakan untuk tujuan analisis data, membuat fungsi yang tidak jelas pada alat yang sama relatif mudah dan langsung.
Dasar-dasar tag HTML
Menginstal Scrapy di Notebook Python
Blok kode berikut menginstal dan mengimpor paket yang diperlukan untuk memulai scrapy pada notebook python:
!pip install scrapy
impor scrapy
dari scrapy.crawler impor CrawlerRunner
!pip install crochet
dari pengaturan impor crochet
mempersiapkan()
permintaan impor
dari scrapy.http impor TextResponse
Crawler Runner akan digunakan untuk menjalankan spider yang kita buat. TextResponse berfungsi sebagai shell yang dapat digunakan untuk mengikis satu URL dan menyelidiki tag HTML untuk ekstraksi data dari halaman web. Kami nantinya dapat membuat laba-laba untuk mengotomatiskan seluruh proses dan mengikis data hingga n jumlah halaman.
Crochet diatur untuk menangani kesalahan ReactorNotRestartable . Sekarang mari kita lihat bagaimana sebenarnya kita dapat mengekstrak data dari halaman web menggunakan pemilih CSS dan X-path. Kami akan mengikis situs berita yahoo dengan string pencarian seperti tesla ini sebagai contoh. Kami akan mengikis halaman web untuk mendapatkan judul artikel.
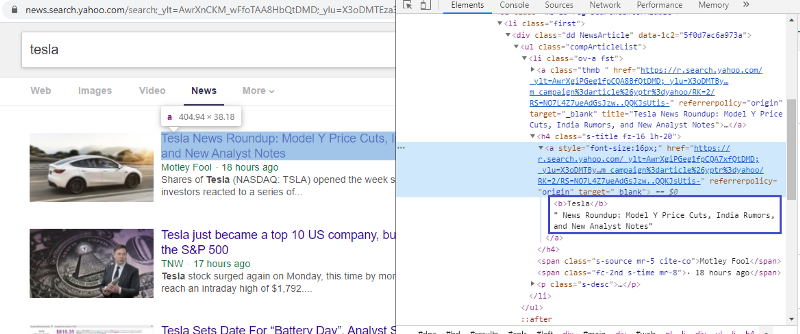
Periksa elemen untuk memeriksa tag HTML
Mengklik kanan pada tautan pertama dan memilih elemen inspeksi akan memberi kita hasil di atas. Kita dapat melihat bahwa judul adalah bagian dari kelas <a>. Kami akan menggunakan tag ini dan mencoba mengekstrak informasi judul di python. Kode di bawah ini akan memuat situs web Yahoo News dalam objek python.
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
respon = TextResponse(r.url, body=r.text, encoding='utf-8′)
Variabel respon menyimpan halaman web dalam format html. Mari kita coba mengekstrak informasi menggunakan tag <a>. Baris kode di bawah ini menggunakan ekstraktor CSS yang menggunakan tag <a> untuk mengekstrak judul dari halaman web.
response.css('a').ekstrak()
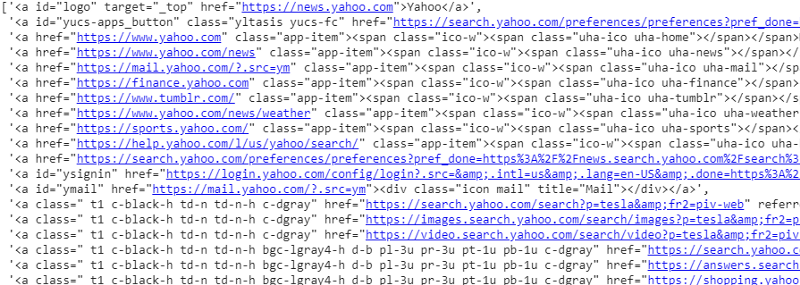
Output dari pemilih CSS pada variabel respons
Seperti yang dapat kita lihat, ada lebih dari sekadar detail artikel di bawah tag <a>. Karenanya tag <a> tidak dapat mengekstrak judul dengan benar. Cara yang lebih intuitif dan tepat untuk mendapatkan tag tertentu adalah dengan menggunakan gadget pemilih . Setelah menginstal gadget pemilih di chrome, kita dapat menggunakannya untuk menemukan tag untuk bagian tertentu dari halaman web yang ingin kita ekstrak. Di bawah ini kita dapat melihat tag yang disarankan oleh Selector Gadget:
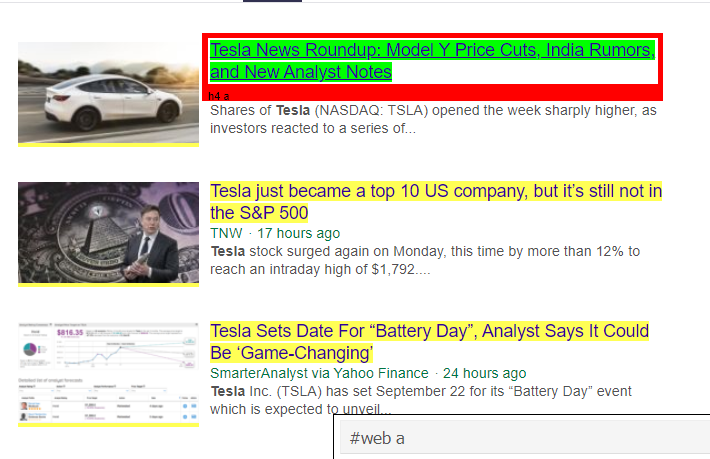
Tag HTML yang disarankan oleh Selector Gadget
Mari kita coba mengekstrak informasi menggunakan pemilih '#web a'. Kode di bawah ini akan mengekstrak informasi judul menggunakan ekstraktor CSS.
response.css('#web a').extract()

Keluaran setelah menggunakan tag '#web a'
Setelah menggunakan tag yang disarankan oleh Gadget Selector, kami mendapatkan hasil yang lebih ringkas menggunakan tag ini. Tapi tetap saja, kita hanya perlu mengekstrak judul artikel dan membiarkan informasi lainnya terpisah. Kita dapat menambahkan pemilih X-path pada ini dan melakukan hal yang sama. Kode di bawah ini akan mengekstrak teks judul dari tag CSS:
response.css('#web a').xpath('@title').extract()

Daftar semua judul
Seperti yang kita lihat, kita berhasil mengekstrak judul artikel dari situs web Yahoo News. Meskipun ini adalah sedikit prosedur coba-coba, kami pasti dapat memahami alur proses yang mengarah ke tag yang benar dan alamat xpath yang diperlukan untuk mengekstrak informasi spesifik apa pun dari halaman web.
Kami juga dapat mengekstrak tautan, deskripsi, tanggal, dan penerbit dengan menggunakan elemen periksa dan gadget pemilih. Ini adalah proses berulang dan mungkin memerlukan beberapa waktu untuk mendapatkan hasil yang diinginkan. Kita dapat menggunakan potongan kode ini untuk mengekstrak data dari halaman web yahoo news.
judul = response.css('#web a').xpath(“@title”).extract()
media = response.css('.cite-co::text').extract()
desc = response.css('ps-desc').extract()
tanggal = response.css('#web .mr-8::text').extract()
link = response.css('h4.s-title a').xpath(“@href”).extract()
Baca: Karir di Ilmu Data
Membangun laba-laba
Kita sekarang tahu cara menggunakan tag untuk mengekstrak bit dan potongan informasi tertentu menggunakan variabel respons dan ekstraktor css. Kita sekarang harus merangkai ini bersama-sama dengan Scrapy Spider. Scrapy Spider adalah kelas dengan struktur standar yang dibangun untuk merayapi dan mengikis informasi dari situs web. Ada banyak hal yang bisa dikendalikan oleh laba-laba:
- Data yang akan diekstraksi dari variabel respon.
- Penataan dan Pengembalian data.
- Membersihkan data jika ada potongan informasi yang tidak diinginkan dalam data yang diekstraksi.
- Opsi menggores situs web hingga nomor halaman tertentu.
Karenanya laba-laba pada dasarnya adalah jantung dari membangun fungsi pengikisan web menggunakan Scrapy. Mari kita lihat lebih dekat setiap bagian dari laba-laba. Bagian data yang akan diekstraksi sudah dibahas di atas di mana kami menggunakan variabel respons untuk mengekstrak data tertentu dari halaman web.
Membersihkan data
Blok kode di bawah ini akan membersihkan data deskripsi.
TAG_RE = re.compile(r'<[^>]+>') # menghapus tag html
j = 0
#cleaning Deskripsi string
untuk saya di desc:
desc[j] = TAG_RE.sub(”, i)
j = j + 1
Kode ini menggunakan ekspresi reguler dan menghapus tag html yang tidak diinginkan dari deskripsi artikel.
Sebelum:
<p class=”s-desc”>Dalam wawancara baru-baru ini di Motley Fool Live, salah satu pendiri dan CEO Motley Fool
Tom Gardner ingat bertemu Kendal Musk — saudara laki-laki <b>Tesla</b> (NASDAQ: TSLA)… </p>
Setelah Regex:
Dalam sebuah wawancara baru-baru ini di Motley Fool Live, salah satu pendiri dan CEO Motley Fool Tom Gardner mengingat pertemuannya dengan Kendal Musk - saudara laki-laki Tesla (NASDAQ: TSLA)..
Sekarang kita dapat melihat bahwa tag html tambahan telah dihapus dari deskripsi artikel.

Penataan dan Pengembalian data
# Berikan baris konten yang diekstraksi dengan bijak
untuk item dalam zip (judul, media, tautan, desc, tanggal):
# buat kamus untuk menyimpan info yang tergores
tergores_info = {
'Judul': item[0],
'Media': butir[1],
'Tautan' : item [2],
'Deskripsi' : item[3],
'Tanggal' : butir[4],
'Search_string' : searchstr,
'Sumber': “Berita Yahoo”,
}
# hasilkan atau berikan info yang tergores ke scrapy
hasil scraped_info
Data yang diekstraksi dari halaman web disimpan dalam variabel daftar yang berbeda. Kami sedang membuat kamus yang kemudian dikembalikan ke luar laba-laba. Fungsi hasil adalah fungsi dari setiap kelas laba-laba dan digunakan untuk mengembalikan data ke fungsi tersebut. Data ini kemudian dapat disimpan sebagai json, csv atau berbagai jenis dataset.
Wajib Dibaca: Gaji Data Scientist di India
Menavigasi ke n jumlah halaman
Blok kode di bawah ini menggunakan tautan ketika seseorang mencoba membuka halaman hasil berikutnya di berita Yahoo. Variabel nomor halaman diulang hingga page_limit mencapai dan untuk setiap nomor halaman, tautan unik dibuat saat variabel digunakan dalam string tautan. Perintah berikut kemudian mengikuti ke halaman baru dan menghasilkan informasi dari halaman itu.
Secara keseluruhan kami dapat menavigasi halaman menggunakan hyperlink dasar dan mengedit informasi seperti nomor halaman dan kata kunci. Mungkin sedikit rumit untuk mengekstrak hyperlink dasar untuk beberapa halaman tetapi umumnya membutuhkan pemahaman pola tentang bagaimana tautan diperbarui di halaman berikutnya.
pagenumber = 1 #memulai nomor halaman
page_limit = 5 #Halaman yang akan di-scraped
#ikuti inisialisasi url halaman next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider=0″+”.
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
hasilkan response.follow(next_page,callback=self.parse)
#navigasi ke halaman berikutnya
Fungsi Akhir
Blok kode di bawah ini adalah fungsi terakhir ketika dipanggil akan mengekspor data string pencarian dalam format .csv.
def yahoo_news ( searchstr,lim ):
TAG_RE = ulang. kompilasi (r '<[^>]+>' ) # menghapus tag html
kelas MySpider ( scrapy . Spider ):
cnt = 1
nama = 'yahoonews' #nama laba-laba
nomor halaman = 1 #memulai nomor halaman
res_limit = lim #Halaman yang akan digores
kata kunci = searchstr #String pencarian
start_urls = [ “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpb?p=aWdpb?
“ +kata kunci+ “&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def parse ( self , respon ):
#Data yang akan diekstrak dari HTML
judul = response.css( '#web a' ).xpath( “@title” ).extract()
media = response.css( '.cite-co::text' ).extract()
desc = response.css( 'ps-desc' ).extract()
tanggal = response.css( '#web .mr-8::text' ).extract()
link = response.css( 'h4.s-title a' ).xpath( “@href” ).extract()
j = 0
#cleaning Deskripsi string
untuk saya di desc:
desc[j] = TAG_RE.sub( ” , i)
j = j + 1
# Berikan baris konten yang diekstraksi dengan bijak
untuk item dalam zip (judul, media, tautan, desc, tanggal):
# buat kamus untuk menyimpan info yang tergores
tergores_info = {
'Judul' : butir[ 0 ],
'Media' : butir[ 1 ],
'Tautan' : item[ 2 ],
'Deskripsi' : item[ 3 ],
'Tanggal' : butir[ 4 ],
'Search_string' : searchstr,
'Sumber' : “Yahoo News” ,
}
# hasilkan atau berikan info yang tergores ke scrapy
hasil scraped_info
#ikuti inisialisasi url halaman
next_page= “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
“8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.keyword+ “&nojs=1&ei=" \
“UTF-8&b=” +str(MySpider.pagenumber)+ “1&pz=10&bct=0&xargs=0”
if(MySpider.pagenumber < MySpider.res_limit):
MySpider.pagenumber += 1
hasilkan response.follow(next_page,callback= self .parse) #navigation to next page
if __name__ == “__main__” :
#mulai proses crawling
pelari = CrawlerRunner(pengaturan={
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }, #set output di pengaturan
},
})
d=runner.crawl(MySpider) # skrip akan diblokir di sini sampai crawling selesai
Kita dapat melihat blok kode yang berbeda yang terintegrasi untuk membuat laba-laba. Bagian utama sebenarnya digunakan untuk memulai laba-laba dan mengkonfigurasi format output. Ada berbagai pengaturan berbeda yang dapat diedit terkait perayap. Seseorang dapat menggunakan middlewares atau proxy untuk melompat.
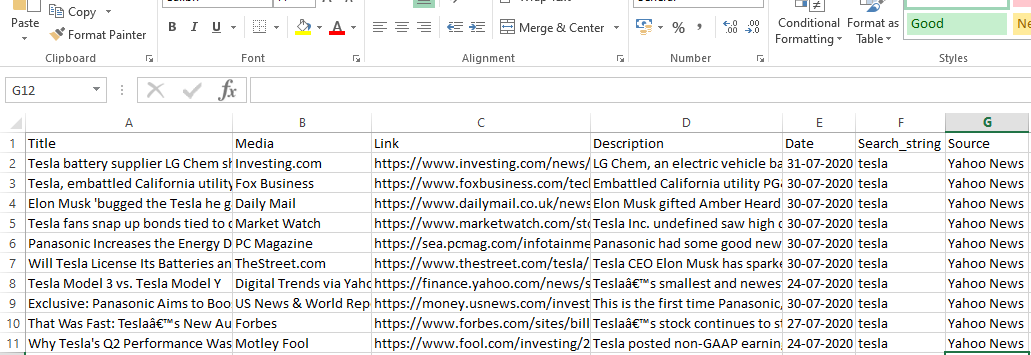
runner.crawl(spider) akan mengeksekusi seluruh proses dan kita akan mendapatkan output sebagai file yang dipisahkan koma.
Keluaran
Kesimpulan
Kami sekarang dapat menggunakan Scrapy sebagai api di notebook Python dan membuat laba-laba untuk merayapi dan mengikis situs web yang berbeda. Kami juga melihat bagaimana berbagai tag dan jalur X dapat digunakan untuk mengakses informasi dari halaman web.
Pelajari kursus ilmu data dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.
Apa itu ScRapy?
Apa kasus penggunaan ScRapy di kehidupan nyata?
ScRapy digunakan untuk menentukan titik harga. Perusahaan mengumpulkan informasi harga dan data dari situs pesaing untuk membantu dalam membuat beberapa keputusan bisnis penting. Mereka kemudian menyimpan dan menganalisis semua data, membuat modifikasi harga yang diperlukan untuk mengoptimalkan penjualan dan keuntungan. Beberapa perusahaan dapat memperoleh wawasan tentang permintaan penjualan musiman dengan mengumpulkan data dari situs pesaing. Mereka kemudian menggunakan data tersebut untuk mengidentifikasi kebutuhan lebih banyak fasilitas atau personel untuk memenuhi permintaan yang terus meningkat. ScRapy juga digunakan untuk merekrut layanan, mempertahankan kepemimpinan biaya dan logistik, membangun direktori, dan eCommerce.
Bagaimana cara kerja ScRapy?
ScRapy menggunakan pemrosesan yang dikendalikan oleh waktu dan pulsa, yang berarti bahwa proses yang meminta tidak menunggu respons dan alih-alih beralih ke pekerjaan berikutnya sesuai waktu. Ketika respons diterima, proses permintaan bergerak untuk mengubah respons. ScRapy dapat dengan mudah melakukan tugas-tugas besar. Itu dapat merayapi sekelompok URL dalam waktu kurang dari satu menit, tergantung pada ukuran grup, dan melakukannya dengan sangat cepat karena menggunakan Twister untuk paralelisme, yang beroperasi secara asinkron (non-pemblokiran).