
データサイエンティストがPythonNotebookでScRapyを簡単に使用するにはどうすればよいですか
公開: 2020-11-30目次
序章
Webスクレイピングは、インターネット上で利用可能な大量のデータにアクセスするための最も簡単で安価な方法の1つです。 構造化されたデータセットを簡単に構築でき、そのデータを定量分析、予測、感情分析などにさらに使用できます。Webサイトのデータをダウンロードする最良の方法は、公開データAPI(最速で信頼性の高い)を使用することですが、すべてではありません。 WebサイトはAPIを提供します。 APIが定期的に更新されない場合があり、重要なデータを見逃す可能性があります。
したがって、代わりにScrapyやSeleniumなどのツールを使用してWebクロールやスクレイピングを行うことができます。 Scrapyは、Pythonで記述された無料のオープンソースのWebクロールフレームワークです。 Scrapyを使用する最も一般的な方法は、Pythonターミナルであり、プロセスをガイドできる記事がたくさんあります。
上記のプロセスはPython開発者の間で非常に人気がありますが、データサイエンティストにとってはあまり直感的ではありません。 スクレイピーを使用する簡単ですが人気のない方法があります。つまり、Jupyterノートブックです。 Pythonノートブックはかなり新しく、主にデータ分析の目的で使用されることがわかっているため、同じツールでスクレイプ関数を作成するのは比較的簡単で簡単です。
HTMLタグの基本
PythonNotebookへのScrapyのインストール
次のコードブロックは、Pythonノートブックでscrapyを使い始めるために必要なパッケージをインストールしてインポートします。
!pipインストールscrapy
スクレイピーをインポートする
からscrapy.crawlerインポートCrawlerRunner
!pipインストールかぎ針編み
かぎ針編みのインポート設定から
設定()
インポートリクエスト
からscrapy.httpインポートTextResponse
クローラーランナーは、私たちが作成したスパイダーを実行するために使用されます。 TextResponseは、1つのURLをスクレイプし、Webページからのデータ抽出のためにHTMLタグを調査するために使用できるスクレイプシェルとして機能します。 後でスパイダーを作成して、プロセス全体を自動化し、最大nページまでのデータを取得できます。
かぎ針編みは、 ReactorNotRestartableエラーを処理するように設定されています。 ここで、 CSSセレクターとXパスを使用してWebページから実際にデータを抽出する方法を見てみましょう。 この例では、検索文字列をteslaとしてyahooニュースサイトをスクレイプします。 記事のタイトルを取得するためにWebページをスクレイピングします。
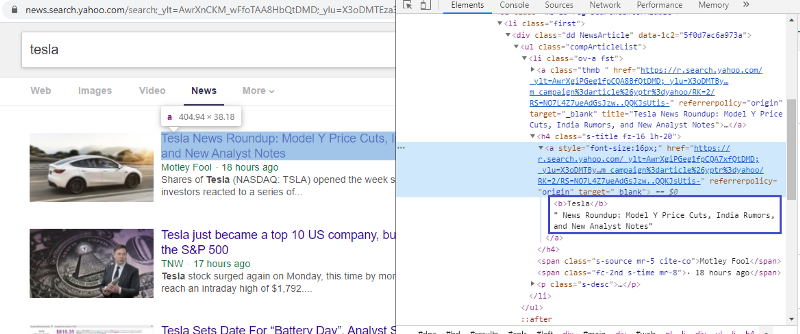
要素を調べてHTMLタグを確認します
最初のリンクを右クリックして検査要素を選択すると、上記の結果が得られます。 タイトルが<a>クラスの一部であることがわかります。 このタグを使用して、Pythonでタイトル情報を抽出してみます。 以下のコードは、YahooNewsWebサイトをPythonオブジェクトにロードします。
r = requests.get(“ https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu =
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p = tesla&nojs = 1&ei = UTF-8&b = 01&pz = 10&bct = 0&xargs = 0”)
response = TextResponse(r.url、body = r.text、encoding ='utf-8')
応答変数は、Webページをhtml形式で格納します。 <a>タグを使用して情報を抽出してみましょう。 以下のコード行は、<a>タグを使用してWebページからタイトルを抽出するCSSエクストラクタを使用しています。
response.css('a')。extract()
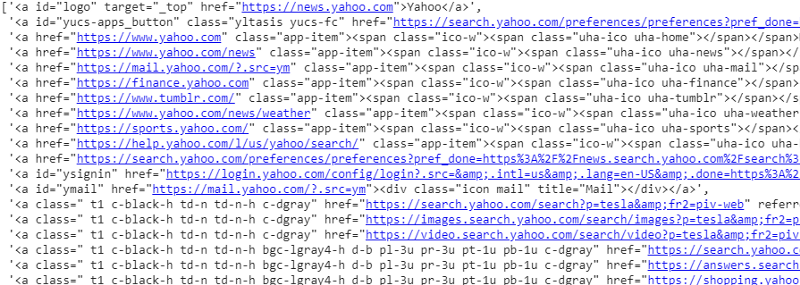
応答変数のCSSセレクターの出力
ご覧のとおり、<a>タグの下には記事の詳細だけではありません。 したがって、<a>タグはタイトルを適切に抽出できません。 特定のタグを取得するためのより直感的で正確な方法は、セレクタガジェットを使用することです。 セレクターガジェットをChromeにインストールした後、それを使用して、抽出するWebページの特定の部分のタグを見つけることができます。 以下に、セレクタガジェットによって提案されたタグを示します。
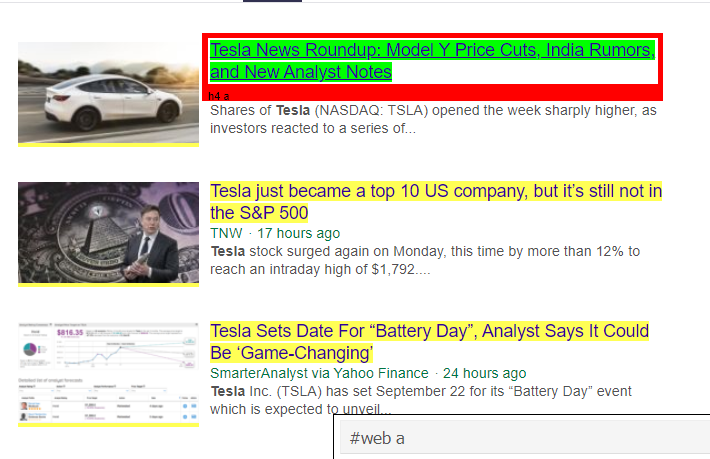
セレクターガジェットによって提案されたHTMLタグ
'#weba'セレクターを使用して情報を抽出してみましょう。 以下のコードは、CSSエクストラクタを使用してタイトル情報を抽出します。
response.css('#web a')。extract()

'#weba'タグを使用した後の出力
Gadget Selectorによって提案されたタグを使用した後、このタグを使用すると、より簡潔な結果が得られます。 それでも、記事のタイトルを抽出し、他の情報はそのままにしておく必要があります。 これにX-pathセレクターを追加して、同じことを行うことができます。 以下のコードは、CSSタグからタイトルテキストを抽出します。
response.css('#web a')。xpath('@ title')。extract()

すべてのタイトルのリスト
ご覧のとおり、YahooNewsWebサイトから記事のタイトルを抽出することができました。 少し試行錯誤の手順ですが、Webページから特定の情報を抽出するために必要なタグとxpathアドレスを修正するためのプロセスフローを確実に理解できます。
同様に、inspect要素とselectorガジェットを使用して、リンク、説明、日付、発行元を抽出できます。 これは反復プロセスであり、望ましい結果が得られるまでに時間がかかる場合があります。 このコードスニペットを使用して、yahooニュースのWebページからデータを抽出できます。
title = response.css('#web a')。xpath(“ @ title”)。extract()
media = response.css('。cite-co:: text')。extract()
desc = response.css('ps-desc')。extract()
date = response.css('#web .mr-8 :: text')。extract()
link = response.css('h4.s-title a')。xpath(“ @ href”)。extract()
読む:データサイエンスのキャリア
蜘蛛を作る
これで、タグを使用して、応答変数とcssエクストラクタを使用して特定のビットと情報を抽出する方法がわかりました。 これをScrapySpiderと一緒につなぐ必要があります。 Scrapy Spidersは、Webサイトから情報をクロールして取得するために構築された、事前定義された構造を持つクラスです。 スパイダーによって制御できるものはたくさんあります。
- 応答変数から抽出されるデータ。
- データの構造化と返却。
- 抽出されたデータに不要な情報が含まれている場合は、データをクリーニングします。
- 特定のページ番号までWebサイトをスクレイピングするオプション。
したがって、スパイダーは本質的に、Scrapyを使用してWebスクレイピング機能を構築するための中心です。 蜘蛛のあらゆる部分を詳しく見てみましょう。 抽出されるデータの部分は、Webページから特定のデータを抽出するために応答変数を使用していた上記ですでに説明されています。
クリーニングデータ
以下のコードブロックは、説明データをクリーンアップします。
TAG_RE = re.compile(r'<[^>] +>')#htmlタグを削除する
j = 0
#cleaning説明文字列
説明の私のために:
desc [j] = TAG_RE.sub(”、i)
j = j + 1
このコードは正規表現を使用し、記事の説明から不要なhtmlタグを削除します。
前:
<p class =” s-desc”> Motley Fool Liveの最近のインタビューで、MotleyFoolの共同創設者兼CEO
トムガードナーは、<b>テスラ</ b>(NASDAQ:TSLA)の兄弟であるケンダルマスクとの出会いを思い出しました…</ p>
正規表現後:
Motley Fool Liveに関する最近のインタビューで、MotleyFoolの共同創設者兼CEOのTomGardnerは、Tesla(NASDAQ:TSLA)の兄弟であるKendalMuskとの出会いを思い出しました。
これで、余分なhtmlタグが記事の説明から削除されていることがわかります。
データの構造化と返却
#抽出されたコンテンツを行ごとに与える
zip形式のアイテム(タイトル、メディア、リンク、説明、日付)の場合:
#スクレイプされた情報を保存するための辞書を作成する
scared_info = {
'タイトル':item [0]、
「メディア」:item [1]、
'リンク':item [2]、
'説明':item [3]、

'日付':item [4]、
'Search_string':searchstr、
「出典」:「YahooNews」、
}
#スクレイプされた情報をscrapyに譲るまたは与える
利回りscraped_info
Webページから抽出されたデータは、さまざまなリスト変数に格納されます。 スパイダーの外に戻される辞書を作成しています。 Yield関数は、任意のスパイダークラスの関数であり、データを関数に戻すために使用されます。 このデータは、json、csv、またはさまざまな種類のデータセットとして保存できます。
必読:インドのデータサイエンティスト給与
nページに移動
以下のコードブロックは、Yahooニュースの結果の次のページに移動しようとしたときにリンクを使用します。 ページ番号変数は、page_limitに達するまで繰り返され、ページ番号ごとに、変数がリンク文字列で使用されるときに一意のリンクが作成されます。 次に、次のコマンドが新しいページに続き、そのページから情報を生成します。
全体として、ベースハイパーリンクを使用してページをナビゲートし、ページ番号やキーワードなどの情報を編集することができます。 一部のページのベースハイパーリンクを抽出するのは少し複雑かもしれませんが、通常、次のページでリンクがどのように更新されるかについてのパターンを理解する必要があります。
pagenumber = 1#開始ページ番号
page_limit = 5#スクレイプするページ
#follow on page url initialisation next_page =” https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu =
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p =” + MySpider.keyword +”&nojs = 1&ei = UTF-8&b =” + str(MySpider.pagenumber)+” 1&p
if(MySpider.pagenumber <MySpider.res_limit):
MySpider.pagenumber + = 1
response.follow(next_page、callback = self.parse)を生成します
#次のページへのナビゲーション
最終機能
以下のコードブロックは、呼び出されたときに検索文字列のデータを.csv形式でエクスポートする最後の関数です。
def yahoo_news ( searchstr、lim ):
TAG_RE=re。 compile (r '<[^>] +>' ) #htmlタグを削除する
クラスMySpider ( scrapy。Spider ) : _
cnt = 1
名前= 'yahoonews' #クモの名前
ページ番号= 1 #開始ページ番号
res_limit = lim #スクレイプするページ
キーワード=searchstr #検索文字列
start_urls = [ “ https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdp
「 +keyword+ 」&nojs = 1&ei = UTF-8&b = 01&pz = 10&bct = 0&xargs = 0” ]
def parse ( self 、 response ):
#HTMLから抽出するデータ
title = response.css( '#web a' ).xpath( “ @title” ).extract()
media = response.css( '.cite-co :: text' ).extract()
desc = response.css( 'ps-desc' ).extract()
date = response.css( '#web .mr-8 :: text' ).extract()
link = response.css( 'h4.s-title a' ).xpath( “ @href” ).extract()
j = 0
#cleaning説明文字列
説明の私のために:
desc [j] = TAG_RE.sub( ” 、i)
j = j + 1
#抽出されたコンテンツを行ごとに与える
zip形式のアイテム(タイトル、メディア、リンク、説明、日付)の場合:
#スクレイプされた情報を保存するための辞書を作成する
scared_info = {
'タイトル' :item [ 0 ]、
'メディア' :item [ 1 ]、
'リンク' :item [ 2 ]、
'説明' :item [ 3 ]、
'日付' :item [ 4 ]、
'Search_string' :searchstr、
「出典」 : 「YahooNews」 、
}
#スクレイプされた情報をscrapyに譲るまたは与える
利回りscraped_info
#ページのURLの初期化をフォローする
next_page = “ https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
“ 8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p =” + MySpider.keyword + “&nojs = 1&ei =” \
“ UTF-8&b =” + str(MySpider.pagenumber)+ “ 1&pz = 10&bct = 0&xargs = 0”
if(MySpider.pagenumber <MySpider.res_limit):
MySpider.pagenumber + = 1
return response.follow( next_page 、callback = self .parse) #navigation to next page
if __name__ == “ __main __” :
#クロールのプロセスを開始します
runner = CrawlerRunner(settings = {
“ FEEDS”: { “ yahoo_output.csv” :{ “ format” : “ csv” }、 #設定で出力を設定
}、
})
d = runner.crawl(MySpider) #クロールが終了するまで、スクリプトはここでブロックされます
スパイダーを作成するために統合されたコードのさまざまなブロックを見つけることができます。 主要部分は、実際にはスパイダーをキックスタートし、出力フォーマットを構成するために使用されます。 クローラーに関して編集できるさまざまな設定があります。 ホッピングにはミドルウェアまたはプロキシを使用できます。
runner.crawl(spider)はプロセス全体を実行し、出力をコンマ区切りファイルとして取得します。
出力
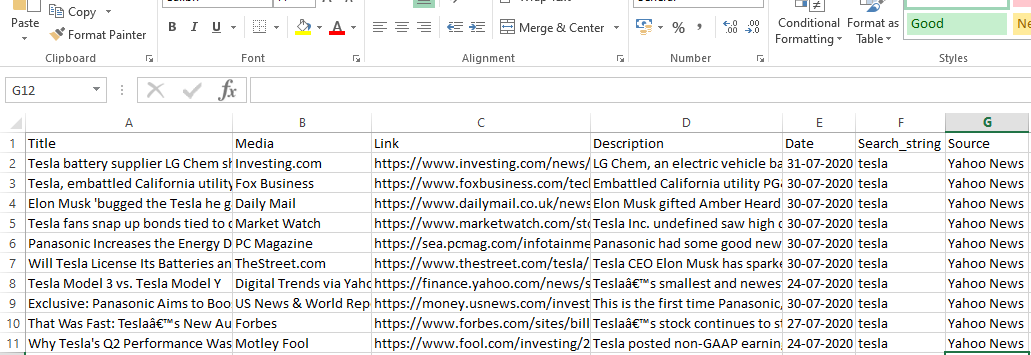
結論
これで、ScrapyをPythonノートブックのAPIとして使用し、さまざまなWebサイトをクロールしてスクレイプするスパイダーを作成できます。 また、さまざまなタグとXパスを使用してWebページから情報にアクセスする方法についても説明しました。
世界のトップ大学からデータサイエンスコースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
ScRapyとは何ですか?
ScRapyの実際のユースケースは何ですか?
ScRapyは、価格ポイントを決定するために使用されます。 企業は、ライバルのWebサイトから価格情報とデータを収集して、いくつかの重要なビジネス上の意思決定を支援します。 次に、すべてのデータを保存して分析し、売上と利益を最適化するために必要な価格変更を行います。 いくつかの企業は、競合他社のサイトからデータを収集することにより、季節的な販売需要に関する洞察を得ることができました。 次に、データを利用して、増大する需要を満たすためにさらに多くの施設や人員が必要であることを特定しました。 ScRapyは、サービスの採用、コストリーダーシップとロジスティクスの維持、ディレクトリの構築、eコマースにも使用されます。
ScRapyはどのように機能しますか?
ScRapyは時間とパルス制御の処理を使用します。つまり、要求しているプロセスは応答を待たずに、時間に従って次のジョブに進みます。 応答を受信すると、要求プロセスは応答を変更するために進みます。 ScRapyは大きなタスクを簡単に実行できます。 グループのサイズに応じて、1分以内にURLのグループをクロールでき、非同期(非ブロッキング)で動作する並列処理にTwisterを利用するため、非常に高速に実行されます。