
Como um cientista de dados pode usar facilmente o ScRapy no Python Notebook
Publicados: 2020-11-30Índice
Introdução
O Web-Scraping é uma das maneiras mais fáceis e baratas de obter acesso a uma grande quantidade de dados disponíveis na internet. Podemos construir facilmente conjuntos de dados estruturados e esses dados podem ser usados para Análise Quantitativa, Previsão, Análise de Sentimentos, etc. O melhor método para baixar os dados de um site é usar sua API de dados públicos (mais rápida e confiável), mas nem todos sites fornecem APIs. Às vezes, as APIs não são atualizadas regularmente e podemos perder dados importantes.
Portanto, podemos usar ferramentas como Scrapy ou Selenium para rastreamento e raspagem na web como alternativa. Scrapy é uma estrutura de rastreamento da Web gratuita e de código aberto escrita em Python. A maneira mais comum de usar scrapy é no terminal Python e existem muitos artigos que podem guiá-lo pelo processo.
Embora o processo acima seja muito popular entre os desenvolvedores python, não é muito intuitivo para um cientista de dados. Há uma maneira mais fácil, mas impopular, de usar o scrapy, ou seja, no notebook Jupyter. Como sabemos, os notebooks Python são relativamente novos e usados principalmente para fins de análise de dados, criar funções fragmentadas na mesma ferramenta é relativamente fácil e direto.
Noções básicas de tags HTML
Instalando o Scrapy no Python Notebook
O seguinte bloco de código instala e importa os pacotes necessários para começar com scrapy no python notebook:
!pip instalar scrapy
importar fragmentado
de scrapy.crawler import CrawlerRunner
!pip instalar crochê
da configuração de importação de crochê
configuração()
solicitações de importação
de scrapy.http importação TextResponse
O Crawler Runner será usado para executar o spider que criamos. TextResponse funciona como um shell scrapy que pode ser usado para raspar uma URL e investigar tags HTML para extração de dados da página da web. Mais tarde, podemos criar um spider para automatizar todo o processo e extrair dados de até n páginas.
Crochet está configurado para lidar com o erro ReactorNotRestartable . Vamos agora ver como podemos realmente extrair dados de uma página da Web usando o seletor CSS e o X-path. Vamos raspar o site de notícias do yahoo com a string de pesquisa como tesla neste exemplo. Vamos raspar a página da web para obter o título dos artigos.
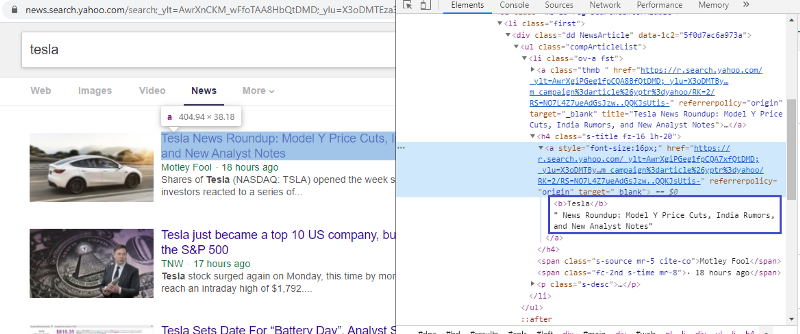
Inspecione o elemento para verificar a tag HTML
Clicar com o botão direito do mouse no primeiro link e selecionar o elemento inspecionar nos dará o resultado acima. Podemos ver que o título faz parte da classe <a>. Usaremos essa tag e tentaremos extrair as informações do título em python. O código abaixo carregará o site do Yahoo News em um objeto python.
r=requests.get(“https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
resposta = TextResponse(r.url, body=r.text, encoding='utf-8′)
A variável de resposta armazena a página da web no formato html. Vamos tentar extrair informações usando a tag <a>. A linha de código abaixo usa o extrator de CSS que está usando a tag <a> para extrair títulos da página da web.
response.css('a').extract()
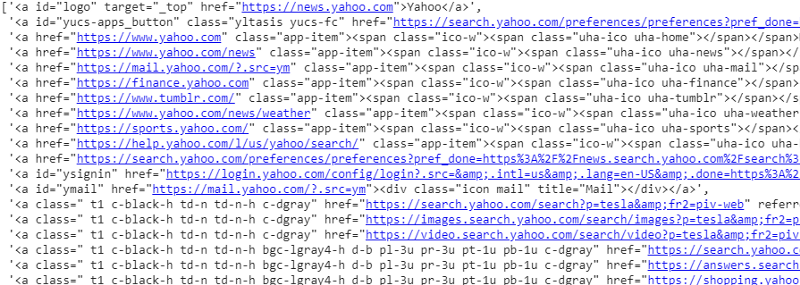
Saída do seletor CSS na variável de resposta
Como podemos ver, há mais do que apenas detalhes do artigo na tag <a>. Portanto, a tag <a> não é capaz de extrair os títulos corretamente. A maneira mais intuitiva e precisa de obter tags específicas é usando o gadget seletor . Depois de instalar o gadget seletor no Chrome, podemos usá-lo para encontrar as tags de qualquer parte específica da página da Web que desejamos extrair. Abaixo podemos ver a tag sugerida pelo Selector Gadget:
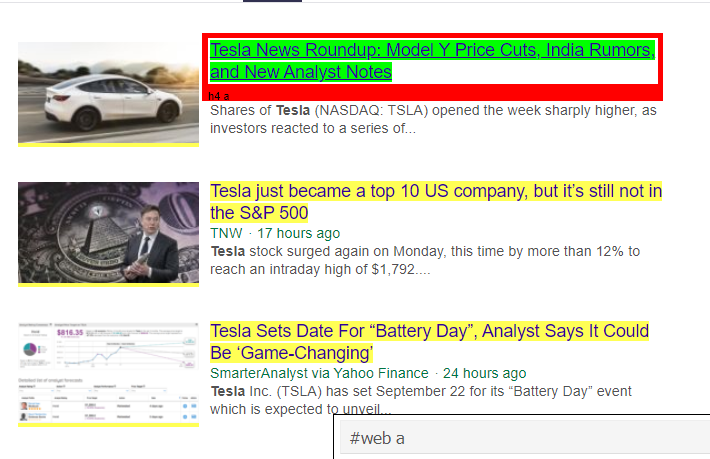
Tag HTML sugerida pelo Selector Gadget
Vamos tentar extrair informações usando o seletor '#web a'. O código abaixo extrairá as informações do título usando o extrator CSS.
response.css('#web a').extract()

Saída após usar a tag '#web a'
Depois de usar a tag sugerida pelo Gadget Selector, obtemos resultados mais concisos usando essa tag. Mas ainda assim, precisamos apenas extrair o título do artigo e deixar outras informações de lado. Podemos adicionar o seletor de caminho X a isso e fazer o mesmo. O código abaixo extrairá o texto do título das tags CSS:
response.css('#web a').xpath('@title').extract()

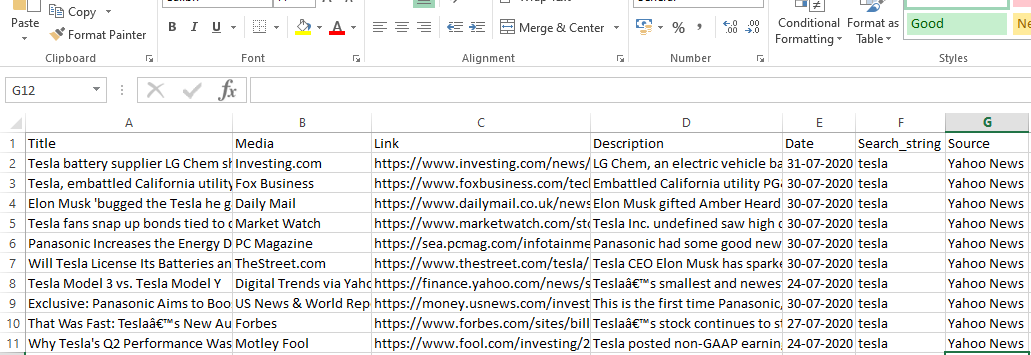
Lista de todos os títulos
Como podemos ver, conseguimos extrair com sucesso os títulos dos artigos do site do Yahoo News. Embora seja um pouco de procedimento de tentativa e erro, podemos definitivamente entender o fluxo do processo para resumir as tags corretas e o endereço xpath necessários para extrair qualquer informação específica de uma página da web.
Da mesma forma, podemos extrair o link, a descrição, a data e o editor usando o elemento inspecionar e o gadget seletor. É um processo iterativo e pode levar algum tempo para obter resultados desejáveis. Podemos usar este trecho de código para extrair os dados da página de notícias do yahoo.
title = response.css('#web a').xpath(“@title”).extract()
media = response.css('.cite-co::text').extract()
desc = response.css('ps-desc').extract()
data = response.css('#web .mr-8::text').extract()
link = response.css('h4.s-title a').xpath(“@href”).extract()
Leia: Carreira em Ciência de Dados
Construindo a aranha
Agora sabemos como usar tags para extrair bits e informações específicas usando a variável de resposta e o extrator css. Agora temos que amarrar isso junto com o Scrapy Spider. Scrapy Spiders são classes com estrutura predefinida que são construídas para rastrear e raspar informações dos sites. Há muitas coisas que podem ser controladas pelas aranhas:
- Dados a serem extraídos das variáveis de resposta.
- Estruturando e retornando os dados.
- Limpeza de dados se houver informações indesejadas nos dados extraídos.
- Opção de raspagem de sites até um determinado número de página.
Portanto, a aranha é essencialmente o coração da construção de uma função de raspagem da web usando o Scrapy. Vamos dar uma olhada em cada parte da aranha. A parte dos dados a serem extraídos já está coberta acima, onde estávamos usando variáveis de resposta para extrair dados específicos da página da web.
Dados de limpeza
O bloco de código abaixo irá limpar os dados de descrição.
TAG_RE = re.compile(r'<[^>]+>') # removendo tags html
j = 0
#cleaning Cadeia de descrição
para i em desc:
desc[j] = TAG_RE.sub(”,i)
j = j + 1
Este código usa expressão regular e remove tags html indesejadas da descrição dos artigos.
Antes de:
<p class=”s-desc”>Em uma entrevista recente no Motley Fool Live, o cofundador e CEO do Motley Fool
Tom Gardner lembrou-se de conhecer Kendal Musk — o irmão de <b>Tesla</b> (NASDAQ: TSLA)… </p>
Depois do Regex:
Em uma entrevista recente no Motley Fool Live, o cofundador e CEO do Motley Fool, Tom Gardner, lembrou-se de conhecer Kendal Musk – o irmão de Tesla (NASDAQ: TSLA).
Agora podemos ver que as tags html extras foram removidas da descrição do artigo.
Estruturando e retornando dados
# Forneça a linha de conteúdo extraída

para item em zip (título, mídia, link, desc, data):
# cria um dicionário para armazenar as informações extraídas
raspado_info = {
'Título': item[0],
'Mídia': item[1],
'Link': item[2],
'Descrição': item[3],
'Data': item[4],
'Search_string': searchstr,
'Fonte': “Notícias do Yahoo”,
}
# rendimento ou dar a informação raspada para scrapy
rendimento scraped_info
Os dados extraídos das páginas da web são armazenados em diferentes variáveis de lista. Estamos criando um dicionário que é então devolvido para fora da aranha. A função Yield é uma função de qualquer classe spider e é usada para retornar dados à função. Esses dados podem ser salvos como json, csv ou diferentes tipos de conjunto de dados.
Deve ler: Salário de cientista de dados na Índia
Navegando para n número de páginas
O bloco de código abaixo usa o link quando se tenta ir para a próxima página de resultados no Yahoo news. A variável page number é iterada até que o page_limit atinja e para cada número de página, um link exclusivo é criado conforme a variável é usada na string de link. O comando a seguir segue para a nova página e produz as informações dessa página.
Em suma, somos capazes de navegar pelas páginas usando um hiperlink básico e editar informações como o número da página e a palavra-chave. Pode ser um pouco complicado extrair o hiperlink base para algumas páginas, mas geralmente requer a compreensão do padrão de como o link está sendo atualizado nas próximas páginas.
pagenumber = 1 #número da página inicial
page_limit = 5 #Páginas a serem raspadas
#follow na inicialização do URL da página next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.pagenumber)+”1&pz=10&bct=0&xargs=0″
if(MySpider.pagenumber < MySpider.res_limit):
MeuSpider.pagenumber += 1
yield response.follow(next_page,callback=self.parse)
#navigation para a próxima página
Função final
O bloco de código abaixo é a função final quando chamada exportará os dados da string de pesquisa no formato .csv.
def yahoo_news ( searchstr,lim ):
TAG_RE = re. compile (r '<[^>]+>' ) # removendo tags html
class MySpider ( scrapy . Spider ):
cnt = 1
nome = 'yahoonews' #nome da aranha
número da página = 1 #initiating número da página
res_limit = lim #Páginas a serem raspadas
palavra-chave = searchstr #Search string
start_urls = [ “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=
“ +palavra-chave+ “&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def parse ( self , response ):
#Dados a serem extraídos do HTML
title = response.css( '#web a' ).xpath( “@title” ).extract()
media = response.css( '.cite-co::text' ).extract()
desc = response.css( 'ps-desc' ).extract()
data = response.css( '#web .mr-8::text' ).extract()
link = response.css( 'h4.s-título a' ).xpath( “@href” ).extract()
j = 0
#cleaning Cadeia de descrição
para i em desc:
desc[j] = TAG_RE.sub( ” , i)
j = j + 1
# Forneça a linha de conteúdo extraída
para item em zip (título, mídia, link, desc, data):
# cria um dicionário para armazenar as informações extraídas
raspado_info = {
'Título' : item[ 0 ],
'Mídia' : item[ 1 ],
'Link' : item[ 2 ],
'Descrição' : item[ 3 ],
'Data' : item[ 4 ],
'Search_string' : searchstr,
'Fonte' : “Notícias do Yahoo” ,
}
# rendimento ou dar a informação raspada para scrapy
rendimento scraped_info
#follow na inicialização do URL da página
next_page= “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
“8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.keyword+ “&nojs=1&ei=” \
“UTF-8&b=” +str(MySpider.pagenumber)+ “1&pz=10&bct=0&xargs=0”
if(MySpider.pagenumber < MySpider.res_limit):
MeuSpider.pagenumber += 1
yield response.follow(next_page,callback= self .parse) #navigation to next page
if __name__ == “__main__” :
#iniciar processo de rastreamento
corredor = CrawlerRunner(configurações={
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }, #defina a saída nas configurações
},
})
d=runner.crawl(MySpider) # o script irá bloquear aqui até que o rastreamento termine
Podemos identificar diferentes blocos de códigos que são integrados para fazer a aranha. A parte principal é realmente usada para iniciar o spider e configurar o formato de saída. Existem várias configurações diferentes que podem ser editadas em relação ao rastreador. Pode-se usar middlewares ou proxies para salto.
runner.crawl(spider) executará todo o processo e obteremos a saída como um arquivo separado por vírgula.
Saída
Conclusão
Agora podemos usar o Scrapy como uma API em notebooks Python e criar spiders para rastrear e raspar sites diferentes. Também analisamos como diferentes tags e X-path podem ser usados para acessar informações de uma página da web.
Aprenda cursos de ciência de dados das melhores universidades do mundo. Ganhe Programas PG Executivos, Programas de Certificado Avançado ou Programas de Mestrado para acelerar sua carreira.
O que é Scrapy?
Qual é o caso de uso real do ScRapy?
O ScRapy é usado para decidir os pontos de preço. As empresas coletam informações e dados de preços de sites rivais para auxiliar na tomada de várias decisões comerciais importantes. Em seguida, eles salvam e analisam todos os dados, fazendo as modificações de preços necessárias para otimizar as vendas e o lucro. Várias empresas conseguiram obter informações sobre a demanda sazonal de vendas coletando dados de sites de concorrentes. Em seguida, eles utilizaram os dados para identificar a necessidade de mais instalações ou pessoal para atender à crescente demanda. O ScRapy também é usado para serviços de recrutamento, manutenção de liderança de custos e logística, criação de diretórios e comércio eletrônico.
Como o Scrapy funciona?
O ScRapy usa processamento controlado por tempo e pulso, o que significa que o processo solicitante não espera pela resposta e, em vez disso, passa para o próximo trabalho de acordo com o tempo. Quando uma resposta é recebida, o processo solicitante passa a alterar a resposta. O ScRapy pode realizar grandes tarefas sem esforço. Ele pode rastrear um grupo de URLs em menos de um minuto, dependendo do tamanho do grupo, e o faz incrivelmente rápido, pois utiliza o Twister para paralelismo, que opera de forma assíncrona (sem bloqueio).