
Как специалисту по данным легко использовать ScRapy на ноутбуке Python
Опубликовано: 2020-11-30Оглавление
Введение
Веб-скрейпинг — один из самых простых и дешевых способов получить доступ к большому количеству данных, доступных в Интернете. Мы можем легко создавать структурированные наборы данных, и эти данные можно в дальнейшем использовать для количественного анализа, прогнозирования, анализа настроений и т. д. Лучший способ загрузить данные веб-сайта — использовать его общедоступный API данных (самый быстрый и надежный), но не все веб-сайты предоставляют API. Иногда API не обновляются регулярно, и мы можем упустить важные данные.
Следовательно, мы можем использовать такие инструменты, как Scrapy или Selenium, для веб-сканирования и очистки в качестве альтернативы. Scrapy — это бесплатная платформа для веб-сканирования с открытым исходным кодом, написанная на Python. Наиболее распространенный способ использования scrapy — на терминале Python, и есть много статей , которые помогут вам в этом процессе.
Хотя описанный выше процесс очень популярен среди разработчиков Python, он не очень интуитивно понятен специалисту по данным. Есть более простой, но непопулярный способ использования scrapy, например, на блокноте Jupyter. Как мы знаем, блокноты Python появились сравнительно недавно и в основном используются для целей анализа данных, поэтому создание функций скрапинга в том же инструменте относительно легко и просто.
Основы HTML-тегов
Установка Scrapy на ноутбук Python
Следующий блок кода устанавливает и импортирует необходимые пакеты, необходимые для начала работы со scrapy на ноутбуке Python:
!pip установить скраппи
импортировать скрейп
импортировать из scrapy.crawler CrawlerRunner
!pip установить крючком
из настройки импорта вязания крючком
настраивать()
запросы на импорт
импорт из scrapy.http TextResponse
Crawler Runner будет использоваться для запуска созданного нами паука. TextResponse работает как оболочка, которую можно использовать для очистки одного URL-адреса и исследования HTML-тегов для извлечения данных с веб-страницы. Позже мы можем создать паука, чтобы автоматизировать весь процесс и очищать данные до n страниц.
Crochet настроен на обработку ошибки ReactorNotRestartable . Давайте теперь посмотрим, как мы можем извлечь данные с веб-страницы, используя селектор CSS и X-path. В качестве примера мы будем очищать новостной сайт Yahoo со строкой поиска как tesla . Мы будем очищать веб-страницу, чтобы получить название статей.
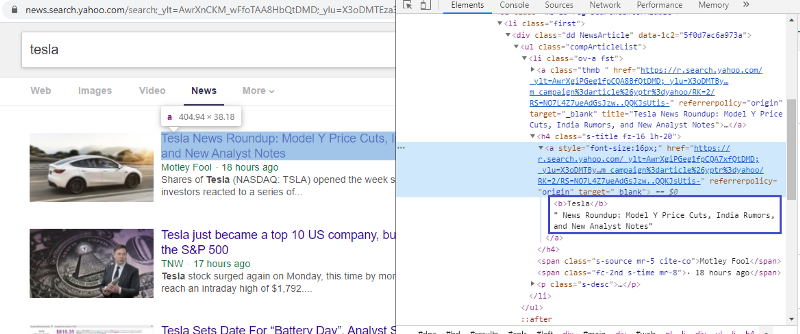
Осмотрите элемент, чтобы проверить тег HTML
Щелкнув правой кнопкой мыши по первой ссылке и выбрав элемент проверки, мы получим приведенный выше результат. Мы видим, что заголовок является частью класса <a>. Мы будем использовать этот тег и попытаемся извлечь информацию о заголовке на python. Приведенный ниже код загрузит веб-сайт Yahoo News в объект Python.
r=requests.get("https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0")
ответ = TextResponse (r.url, тело = r.текст, кодировка = 'utf-8')
Переменная ответа хранит веб-страницу в формате html. Попробуем извлечь информацию с помощью тега <a>. В приведенной ниже строке кода используется экстрактор CSS, использующий тег <a> для извлечения заголовков с веб-страницы.
ответ.css('a').extract()
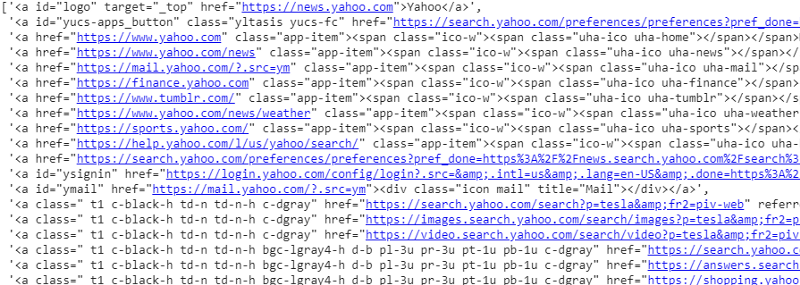
Вывод селектора CSS на переменную ответа
Как мы видим, под тегом <a> находится не только информация о статье. Следовательно, тег <a> не может должным образом извлекать заголовки. Более интуитивный и точный способ получения конкретных тегов — использование гаджета-селектора . После установки гаджета селектора в Chrome мы можем использовать его для поиска тегов для любых конкретных частей веб-страницы, которые мы хотим извлечь. Ниже мы видим тег, предложенный селекторным гаджетом:
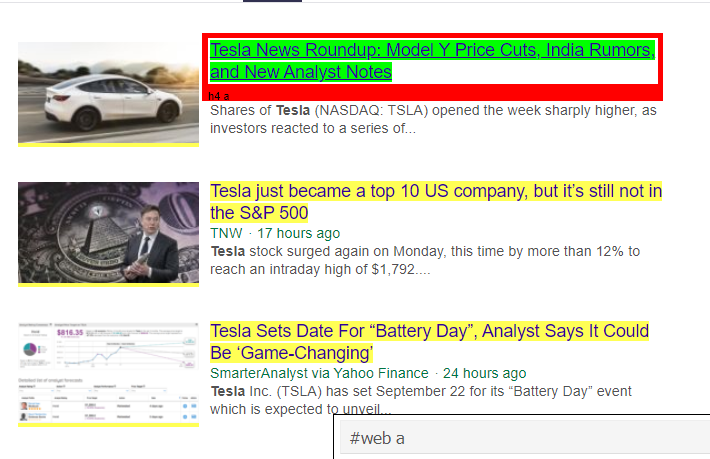
HTML-тег, предложенный Selector Gadget
Попробуем извлечь информацию с помощью селектора '#web a'. Приведенный ниже код будет извлекать информацию о заголовке с помощью экстрактора CSS.
response.css('#web a').extract()

Вывод после использования тега #web a
После использования тега, предложенного Gadget Selector, мы получаем более краткие результаты с использованием этого тега. Но все же нам нужно просто извлечь заголовок статьи и оставить другую информацию отдельно. Мы можем добавить сюда селектор X-path и сделать то же самое. Код ниже извлечет текст заголовка из тегов CSS:
response.css('#web a').xpath('@title').extract()

Список всех титулов
Как мы видим, нам удалось извлечь заголовки статей с веб-сайта Yahoo News. Хотя это немного процедура проб и ошибок, мы определенно можем понять, что процесс сводится к правильным тегам и адресу xpath, необходимым для извлечения любой конкретной информации с веб-страницы.
Точно так же мы можем извлечь ссылку, описание, дату и издателя, используя элемент проверки и гаджет выбора. Это повторяющийся процесс, и для получения желаемых результатов может потребоваться некоторое время. Мы можем использовать этот фрагмент кода для извлечения данных с веб-страницы новостей Yahoo.
title = response.css('#web a').xpath("@title").extract()
медиа = response.css('.cite-co::text').extract()
desc = response.css('ps-desc').extract()
date = response.css('#web.mr-8::text').extract()
ссылка = response.css('h4.s-title a').xpath("@href").extract()
Читайте: Карьера в науке о данных
Создание паука
Теперь мы знаем, как использовать теги для извлечения определенных битов и фрагментов информации с помощью переменной ответа и экстрактора css. Теперь нам нужно связать это вместе с Scrapy Spider. Scrapy Spiders — это классы с предопределенной структурой, созданные для сканирования и извлечения информации с веб-сайтов. Есть много вещей, которыми могут управлять пауки:
- Данные, которые необходимо извлечь из переменных ответа.
- Структурирование и возврат данных.
- Очистка данных, если в извлеченных данных есть нежелательные фрагменты информации.
- Возможность очистки веб-сайтов до определенного номера страницы.
Следовательно, паук, по сути, является сердцем создания функции парсинга веб-страниц с использованием Scrapy. Давайте подробнее рассмотрим каждую часть паука. Часть данных, которые необходимо извлечь, уже описана выше, где мы использовали переменные ответа для извлечения определенных данных с веб-страницы.
Очистка данных
Блок кода ниже очистит данные описания.
TAG_RE = re.compile(r'<[^>]+>') # удаление html-тегов
j = 0
#очистка Строка описания
для я в описании:
desc[j] = TAG_RE.sub(", i)
дж = дж + 1
Этот код использует регулярное выражение и удаляет ненужные html-теги из описания статей.
До:
<p class="s-desc">В недавнем интервью Motley Fool Live соучредитель и генеральный директор Motley Fool
Том Гарднер вспомнил встречу с Кендалом Маском — братом <b>Tesla</b> (NASDAQ: TSLA)… </p>
После регулярного выражения:
В недавнем интервью на Motley Fool Live соучредитель и генеральный директор Motley Fool Том Гарднер вспомнил встречу с Кендалом Маском — братом Tesla (NASDAQ: TSLA).
Теперь мы видим, что лишние html-теги удалены из описания статьи.
Структурирование и возврат данных
# Предоставление извлеченного содержимого по строкам

для элемента в почтовом индексе (название, медиа, ссылка, описание, дата):
# создаем словарь для хранения вычищенной информации
скрап_информация = {
«Название»: элемент [0],
«Медиа»: элемент[1],
«Ссылка»: элемент [2],
«Описание»: элемент [3],
«Дата»: элемент [4],
'Search_string' : строка поиска,
«Источник»: «Yahoo News»,
}
# выдать или передать скопированную информацию в scrapy
урожайность scraped_info
Данные, извлеченные из веб-страниц, хранятся в различных переменных списка. Мы создаем словарь, который затем возвращается за пределы паука. Функция Yield является функцией любого класса пауков и используется для возврата данных обратно в функцию. Затем эти данные можно сохранить в виде json, csv или других наборов данных.
Обязательно прочитайте: Заработная плата специалиста по данным в Индии
Переход на n страниц
Блок кода ниже использует ссылку, когда кто-то пытается перейти на следующую страницу результатов в новостях Yahoo. Переменная номера страницы повторяется до тех пор, пока не будет достигнуто значение page_limit, и для каждого номера страницы создается уникальная ссылка, поскольку переменная используется в строке ссылки. Затем следующая команда переходит на новую страницу и возвращает информацию с этой страницы.
В целом, мы можем перемещаться по страницам, используя базовую гиперссылку, и редактировать информацию, такую как номер страницы и ключевое слово. Может быть немного сложно извлечь базовую гиперссылку для некоторых страниц, но, как правило, это требует понимания закономерности обновления ссылки на следующих страницах.
pagenumber = 1 #начальный номер страницы
page_limit = 5 #Страницы для очистки
# Следите за инициализацией URL-адреса страницы next_page="https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MySpider.keyword+”&nojs=1&ei=UTF-8&b=”+str(MySpider.pagenumber)+”1&pz=10&bct=0&xargs=0″
если (MySpider.pagenumber < MySpider.res_limit):
MySpider.номер_страницы += 1
выходной ответ. Следуйте (следующая_страница, обратный вызов = self.parse)
#навигация на следующую страницу
Конечная функция
Блок кода ниже — это последняя функция, которая при вызове экспортирует данные строки поиска в формате .csv.
def yahoo_news ( searchstr,lim ):
TAG_RE = ре. compile (r '<[^>]+>' ) # удаление тегов html
класс MySpider ( scrapy . Spider ):
цент = 1
имя = 'yahoones' #имя паука
номер страницы = 1 #начальный номер страницы
res_limit = предел #Страницы для очистки
ключевое слово = searchstr # Строка поиска
start_urls = [ "https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=
" +keyword+ "&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0" ]
деф синтаксический анализ ( я , ответ ):
#Данные для извлечения из HTML
title = response.css( '#web a' ).xpath( "@title" ).extract()
media = response.css( '.cite-co::text' ).extract()
desc = response.css( 'ps-desc' ).extract()
date = response.css( '#web.mr-8::text' ).extract()
ссылка = response.css( 'h4.s-title a' ).xpath( "@href" ).extract()
j = 0
#очистка Строка описания
для я в описании:
desc[j] = TAG_RE.sub( " , i)
дж = дж + 1
# Предоставление извлеченного содержимого по строкам
для элемента в zip (название, медиа, ссылка, описание, дата):
# создаем словарь для хранения вычищенной информации
скрап_информация = {
«Название» : элемент [ 0 ],
«Медиа» : элемент [ 1 ],
'Ссылка' : элемент[ 2 ],
'Описание' : элемент[ 3 ],
«Дата» : пункт [ 4 ],
'Search_string' : строка поиска,
«Источник» : «Yahoo News» ,
}
# выдать или передать скопированную информацию в scrapy
урожайность scraped_info
#следить за инициализацией URL-адреса страницы
next_page= "https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG" \
«8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=» +MySpider.keyword+ «&nojs=1&ei=» \
«UTF-8&b=» +str(MySpider.pagenumber)+ «1&pz=10&bct=0&xargs=0»
если (MySpider.pagenumber < MySpider.res_limit):
MySpider.номер_страницы += 1
yield response.follow(next_page,callback= self .parse) # переход на следующую страницу
если __name__ == «__main__» :
#начать процесс сканирования
бегун = CrawlerRunner(настройки={
«FEEDS» : { «yahoo_output.csv» : { «format» : «csv» }, # установить вывод в настройках
},
})
d=runner.crawl(MySpider) # скрипт будет блокироваться здесь, пока не завершится сканирование
Мы можем обнаружить различные блоки кодов, которые объединены в паука. Основная часть фактически используется для запуска паука и настройки формата вывода. Существуют различные настройки, которые можно изменить в отношении сканера. Для переключения можно использовать промежуточное ПО или прокси.
runner.crawl(spider) выполнит весь процесс, и мы получим вывод в виде файла, разделенного запятыми.
Выход
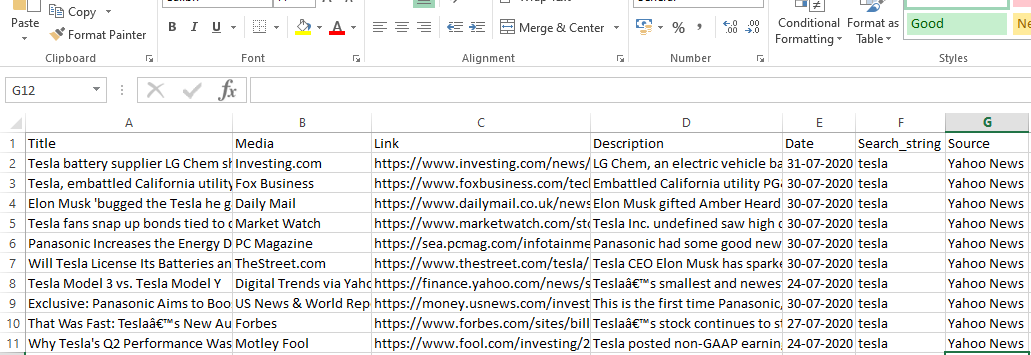
Заключение
Теперь мы можем использовать Scrapy в качестве API для ноутбуков Python и создавать пауков для сканирования и очистки различных веб-сайтов. Мы также рассмотрели, как можно использовать различные теги и X-путь для доступа к информации с веб-страницы.
Изучите курсы по науке о данных в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Что такое ScRapy?
Каков реальный вариант использования ScRapy?
ScRapy используется для определения ценовых категорий. Фирмы собирают информацию о ценах и данные с конкурирующих веб-сайтов, чтобы помочь в принятии нескольких важных бизнес-решений. Затем они сохраняют и анализируют все данные, внося изменения в цены, необходимые для оптимизации продаж и прибыли. Несколько фирм смогли получить представление о спросе на сезонные продажи, собирая данные с сайтов конкурентов. Затем они использовали данные, чтобы определить потребность в дополнительных объектах или персонале для удовлетворения растущего спроса. ScRapy также используется для услуг по подбору персонала, поддержания лидерства по затратам и логистики, создания каталогов и электронной коммерции.
Как работает ScRapy?
ScRapy использует обработку с управлением по времени и по импульсу, что означает, что запрашивающий процесс не ждет ответа, а вместо этого переходит к следующему заданию в зависимости от времени. Когда ответ получен, запрашивающий процесс переходит к изменению ответа. ScRapy может легко выполнять большие задачи. Он может сканировать группу URL-адресов менее чем за минуту, в зависимости от размера группы, и делает это невероятно быстро, поскольку использует Twister для параллелизма, который работает асинхронно (неблокируя).