
Jak specjalista ds. danych może łatwo używać ScRapy w Notatniku w Pythonie?
Opublikowany: 2020-11-30Spis treści
Wstęp
Web-Scraping to jeden z najłatwiejszych i najtańszych sposobów na uzyskanie dostępu do dużej ilości danych dostępnych w Internecie. Możemy łatwo tworzyć ustrukturyzowane zbiory danych, a dane te mogą być dalej wykorzystywane do analizy ilościowej, prognozowania, analizy nastrojów itp. Najlepszą metodą pobierania danych ze strony internetowej jest użycie jej publicznego API danych (najszybszego i niezawodnego), ale nie wszystkich strony internetowe udostępniają interfejsy API. Czasami interfejsy API nie są regularnie aktualizowane i możemy przegapić ważne dane.
Dlatego możemy użyć narzędzi takich jak Scrapy lub Selenium do indeksowania sieci i skrobania jako alternatywy. Scrapy to darmowy framework do przeszukiwania sieci typu open source napisany w Pythonie. Najpopularniejszym sposobem korzystania ze scrapy jest terminal Pythona i istnieje wiele artykułów , które poprowadzą Cię przez ten proces.
Chociaż powyższy proces jest bardzo popularny wśród programistów Pythona, dla naukowców zajmujących się danymi nie jest on zbyt intuicyjny. Jest prostszy, ale niepopularny sposób na używanie scrapy, np. na notebooku Jupyter. Jak wiemy, notatniki Pythona są dość nowe i używane głównie do celów analizy danych, tworzenie funkcji scrapy w tym samym narzędziu jest stosunkowo łatwe i proste.
Podstawy tagów HTML
Instalowanie Scrapy w Notatniku Pythona
Poniższy blok kodu instaluje i importuje niezbędne pakiety potrzebne do rozpoczęcia pracy ze scrapy na notebooku Pythona:
!pip install scrapy
importuj scrapy
z scrapy.crawler import CrawlerRunner
!pip zainstaluj szydełko
z konfiguracji importu szydełka
organizować coś()
żądania importu
ze scrapy.http import TextResponse
Crawler Runner posłuży do uruchomienia stworzonego przez nas pająka. TextResponse działa jak scrapy shell, który może być użyty do zeskrobania jednego adresu URL i zbadania znaczników HTML w celu wyodrębnienia danych ze strony internetowej. Możemy później stworzyć pająka, aby zautomatyzować cały proces i zeskrobać dane do n liczby stron.
Szydełko jest skonfigurowane do obsługi błędu ReactorNotRestartable . Zobaczmy teraz, jak faktycznie możemy wyodrębnić dane ze strony internetowej za pomocą selektora CSS i ścieżki X. W tym przykładzie zeskrobujemy witrynę Yahoo News z ciągiem wyszukiwania jako tesla . Przeszukamy stronę internetową, aby uzyskać tytuły artykułów.
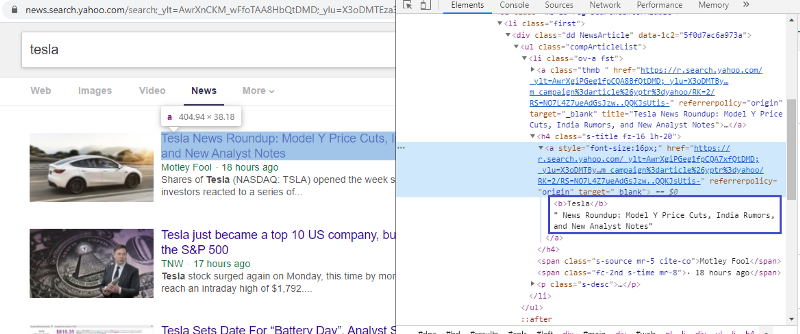
Sprawdź element, aby sprawdzić tag HTML
Kliknięcie prawym przyciskiem myszy na pierwszy link i wybranie elementu inspekcji da nam powyższy wynik. Widzimy, że tytuł jest częścią klasy <a>. Użyjemy tego tagu i spróbujemy wyodrębnić informacje o tytule w Pythonie. Poniższy kod załaduje witrynę Yahoo News w obiekcie Pythona.
r=requests.get("https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=tesla&nojs=1&ei= UTF-8&b=01&pz=10&bct=0&xargs=0”)
odpowiedź = TextResponse(r.url, body=r.text, kodowanie='utf-8′)
Zmienna odpowiedzi przechowuje stronę internetową w formacie html. Spróbujmy wydobyć informacje za pomocą znacznika <a>. Poniższy wiersz kodu używa ekstraktora CSS, który używa tagu <a> do wyodrębniania tytułów ze strony internetowej.
response.css('a').extract()
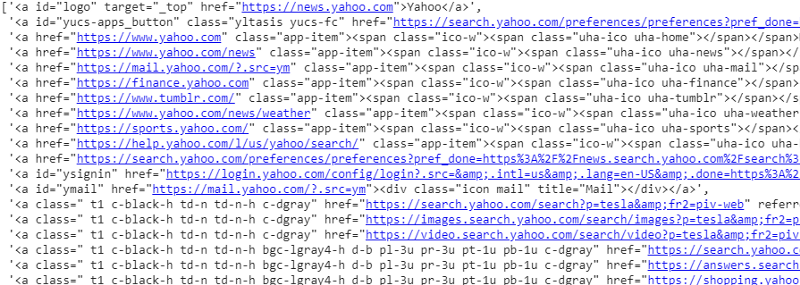
Dane wyjściowe selektora CSS na zmienną odpowiedzi
Jak widać, pod tagiem <a> kryje się więcej niż tylko szczegóły artykułu. Dlatego tag <a> nie jest w stanie prawidłowo wyodrębnić tytułów. Bardziej intuicyjnym i precyzyjnym sposobem uzyskania określonych tagów jest użycie gadżetu selektora . Po zainstalowaniu gadżetu selektora w Chrome, możemy go użyć do znalezienia tagów dla określonych części strony internetowej, które chcemy wyodrębnić. Poniżej możemy zobaczyć tag sugerowany przez gadżet Selektor:
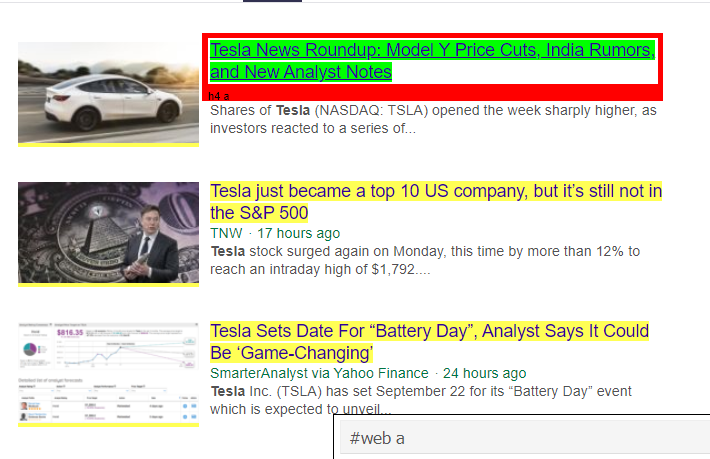
Tag HTML sugerowany przez gadżet selektora
Spróbujmy wyodrębnić informacje za pomocą selektora „#web a”. Poniższy kod wyodrębni informacje o tytule za pomocą ekstraktora CSS.
response.css('#web a').extract()

Dane wyjściowe po użyciu tagu „#web a”
Po użyciu tagu sugerowanego przez Gadget Selector uzyskujemy bardziej zwięzłe wyniki za pomocą tego tagu. Ale nadal musimy tylko wyodrębnić tytuł artykułu i pozostawić inne informacje. Możemy dodać do tego selektor ścieżki X i zrobić to samo. Poniższy kod wyodrębni tekst tytułu z tagów CSS:
response.css('#web a').xpath('@title').extract()

Lista wszystkich tytułów
Jak widać, jesteśmy w stanie z powodzeniem wyodrębnić tytuły artykułów ze strony Yahoo News. Chociaż jest to trochę procedura prób i błędów, zdecydowanie możemy zrozumieć przebieg procesu, który sprowadza się do poprawienia tagów i adresu xpath wymaganych do wyodrębnienia określonych informacji ze strony internetowej.
W podobny sposób możemy wyodrębnić link, opis, datę i wydawcę za pomocą elementu inspekcji i gadżetu selektora. Jest to proces iteracyjny i uzyskanie pożądanych wyników może zająć trochę czasu. Możemy użyć tego fragmentu kodu, aby wyodrębnić dane ze strony internetowej Yahoo News.
title = response.css('#web a').xpath(“@title”).extract()
media = response.css('.cite-co::text').extract()
opis = odpowiedź.css('ps-desc').extract()
date = response.css('#web .mr-8::text').extract()
link = response.css('h4.s-title a').xpath(“@href”).extract()
Przeczytaj: Kariera w nauce o danych
Budowa pająka
Teraz wiemy, jak używać tagów do wyodrębniania określonych bitów i fragmentów informacji za pomocą zmiennej odpowiedzi i ekstraktora css. Teraz musimy to połączyć ze Scrapy Spider. Scrapy Spiders to klasy o predefiniowanej strukturze, które są zbudowane w celu przeszukiwania i pobierania informacji ze stron internetowych. Jest wiele rzeczy, którymi pająki mogą sterować:
- Dane do wyodrębnienia ze zmiennych odpowiedzi.
- Strukturyzacja i zwracanie danych.
- Czyszczenie danych, jeśli w wyodrębnionych danych znajdują się niepożądane informacje.
- Możliwość skrobania stron internetowych do określonego numeru strony.
Dlatego pająk jest zasadniczo sercem budowania funkcji skrobania sieci za pomocą Scrapy. Przyjrzyjmy się bliżej każdej części pająka. Część danych do wyodrębnienia została już omówiona powyżej, gdzie używaliśmy zmiennych odpowiedzi, aby wyodrębnić określone dane ze strony internetowej.
Czyszczenie danych
Poniższy blok kodu wyczyści dane opisu.
TAG_RE = re.compile(r'<[^>]+>') # usuwanie tagów html
j = 0
#czyszczenie Ciąg opisu
dla mnie w opisie:
desc[j] = TAG_RE.sub(”, i)
j = j + 1
Ten kod używa wyrażeń regularnych i usuwa niechciane tagi HTML z opisów artykułów.
Zanim:
<p class=”s-desc”>W niedawnym wywiadzie dla Motley Fool Live, współzałożyciel i dyrektor generalny Motley Fool
Tom Gardner przypomniał sobie spotkanie z Kendal Musk — bratem <b>Tesli</b> (NASDAQ: TSLA)… </p>
Po wyrażeniu regularnym:
W niedawnym wywiadzie dla Motley Fool Live współzałożyciel i dyrektor generalny Motley Fool, Tom Gardner, przypomniał spotkanie Kendala Muska — brata Tesli (NASDAQ: TSLA).
Widzimy teraz, że dodatkowe tagi html zostały usunięte z opisu artykułu.
Strukturyzacja i zwracanie danych
# Mądrze podaj wyodrębniony wiersz treści

dla pozycji w zip (tytuł, media, link, opis, data):
# utwórz słownik do przechowywania zeskrobanych informacji
zeskrobane_informacje = {
'Tytuł': pozycja[0],
„Media”: pozycja[1],
'Link' : pozycja [2],
„Opis” : pozycja [3],
„Data” : pozycja [4],
'Search_string' : searchstr,
„Źródło”: „Yahoo News”,
}
# wydaj lub przekaż zeskrobane informacje scrapy
wydajność scraped_info
Dane wyodrębnione ze stron internetowych są przechowywane w różnych zmiennych listowych. Tworzymy słownik, który następnie wychodzi poza pająka. Funkcja Yield jest funkcją dowolnej klasy pająka i służy do zwracania danych z powrotem do funkcji. Dane te można następnie zapisać jako json, csv lub różnego rodzaju zestawy danych.
Trzeba przeczytać: Wynagrodzenie analityka danych w Indiach
Przechodzenie do liczby n stron
Poniższy blok kodu używa linku, gdy ktoś próbuje przejść do następnej strony wyników w wiadomościach Yahoo. Zmienna numeru strony jest powtarzana aż do osiągnięcia limitu strony i dla każdego numeru strony tworzony jest unikalny link, ponieważ zmienna jest używana w ciągu linku. Następujące polecenie następnie podąża do nowej strony i wyświetla informacje z tej strony.
Podsumowując, jesteśmy w stanie poruszać się po stronach za pomocą podstawowego hiperłącza i edytować informacje, takie jak numer strony i słowo kluczowe. Wyodrębnienie hiperłącza podstawowego dla niektórych stron może być nieco skomplikowane, ale generalnie wymaga zrozumienia wzorca aktualizacji łącza na następnych stronach.
numer strony = 1 #numer strony inicjującej
page_limit = 5 #Strony do zeskrobania
#śledź inicjalizację adresu URL strony next_page=”https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=
X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=”+MójSpider.słowo kluczowe+”&nojs=1&ei=UTF-8&b=”+str(MójSpider=0+10″1
if(Moj Pająk.numer strony < MójPająk.res_limit):
MójPająk.numer strony += 1
wydajność response.follow(next_page,callback=self.parse)
#nawigacja do następnej strony
Funkcja końcowa
Poniższy blok kodu jest ostatnią funkcją po wywołaniu, która wyeksportuje dane ciągu wyszukiwania w formacie .csv.
def yahoo_news ( searchstr,lim ):
TAG_RE = dot. kompilacja (r '<[^>]+>' ) # usuwanie tagów html
klasa MySpider ( scrapy . Spider ):
cnt = 1
nazwa = 'yahonenews' #imię pająka
numer strony = 1 #numer strony inicjującej
res_limit = limit #Strony do zeskrobania
słowo kluczowe = searchstr #Wyszukiwany ciąg
start_urls = [ “https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG8DZ3ExBHBvcwMxBHZ0aWQDBHNlYp9uNwF ?
„ +słowo kluczowe+ „&nojs=1&ei=UTF-8&b=01&pz=10&bct=0&xargs=0” ]
def parse ( siebie , odpowiedź ):
#Dane do wyodrębnienia z HTML
title = response.css( '#web a' ).xpath( “@title” ).extract()
media = response.css( '.cite-co::text' ).extract()
desc = response.css( 'ps-desc' ).extract()
date = response.css( '#web .mr-8::text' ).extract()
link = response.css( 'h4.s-title a' ).xpath( “@href” ).extract()
j = 0
#czyszczenie Ciąg opisu
dla mnie w opisie :
opis[j] = TAG_RE.sub( ” , i)
j = j + 1
# Mądrze podaj wyodrębniony wiersz treści
dla pozycji w zip (tytuł, media, link, opis, data):
# utwórz słownik do przechowywania zeskrobanych informacji
zeskrobane_informacje = {
'Tytuł' : pozycja[ 0 ],
'Media' : pozycja[ 1 ],
'Link' : pozycja[ 2 ],
'Opis' : pozycja[ 3 ],
„Data” : pozycja[ 4 ],
'Search_string' : searchstr,
'Źródło' : „Yahoo News” ,
}
# wydaj lub przekaż zeskrobane informacje scrapy
wydajność scraped_info
#follow na inicjalizacji adresu URL strony
next_page= „https://news.search.yahoo.com/search;_ylt=AwrXnCKM_wFfoTAA8HbQtDMD;_ylu=X3oDMTEza3NiY3RnBGNvbG” \
„8DZ3ExBHBvcwMxBHZ0aWQDBHNlYwNwYWdpbmF0aW9u?p=” +MySpider.słowo kluczowe+ „&nojs=1&ei=” \
„UTF-8&b=” +str(Mój Pająk.numer strony)+ „1&pz=10&bct=0&xargs=0”
if(Moj Pająk.numer strony < MójPająk.res_limit):
MójPająk.numer strony += 1
yield response.follow(next_page,callback= self .parse) #navigation to next page
if __name__ == „__main__” :
#rozpocznij proces indeksowania
biegacz = CrawlerRunner(settings={
“FEEDS” : { “yahoo_output.csv” : { “format” : “csv” }, #ustaw wyjście w ustawieniach
},
})
d=runner.crawl(MySpider) # skrypt zablokuje się tutaj do zakończenia indeksowania
Możemy dostrzec różne bloki kodów, które są zintegrowane w celu stworzenia pająka. Główna część jest faktycznie używana do uruchomienia pająka i skonfigurowania formatu wyjściowego. Istnieje wiele różnych ustawień, które można edytować w odniesieniu do robota. Do przeskakiwania można używać oprogramowania pośredniczącego lub proxy.
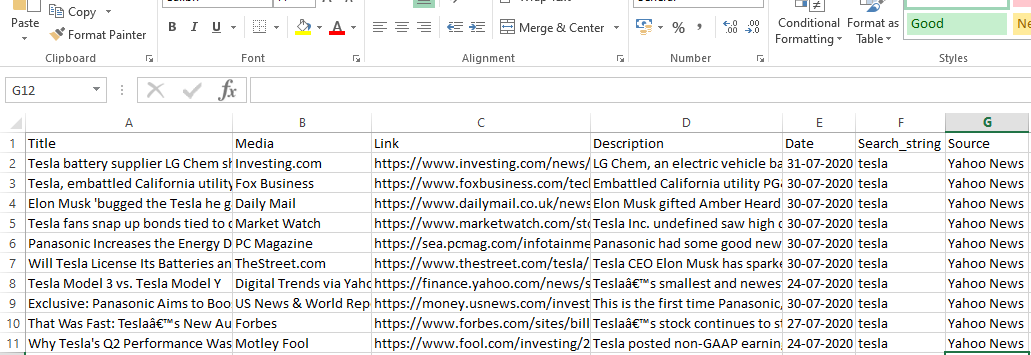
runner.crawl(spider) wykona cały proces i otrzymamy wynik jako plik oddzielony przecinkami.
Wyjście
Wniosek
Możemy teraz używać Scrapy jako interfejsu API w notatnikach Pythona i tworzyć pająki do indeksowania i scrapowania różnych stron internetowych. Przyjrzeliśmy się również, w jaki sposób różne tagi i ścieżki X mogą być używane do uzyskiwania dostępu do informacji ze strony internetowej.
Ucz się kursów nauki o danych z najlepszych światowych uniwersytetów. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Co to jest ScRapy?
Jaki jest rzeczywisty przypadek użycia ScRapy?
ScRapy służy do decydowania o punktach cenowych. Firmy zbierają informacje o cenach i dane z konkurencyjnych stron internetowych, aby pomóc w podjęciu kilku ważnych decyzji biznesowych. Następnie zapisują i analizują wszystkie dane, dokonując modyfikacji cenowych niezbędnych do optymalizacji sprzedaży i zysku. Kilka firm było w stanie uzyskać wgląd w sezonowe zapotrzebowanie na sprzedaż, zbierając dane z witryn konkurencji. Następnie wykorzystali te dane do zidentyfikowania potrzeby większej liczby obiektów lub personelu, aby sprostać rosnącemu zapotrzebowaniu. ScRapy jest również używany do rekrutacji usług, utrzymywania przywództwa kosztowego i logistyki, budowania katalogów i eCommerce.
Jak działa ScRapy?
ScRapy wykorzystuje przetwarzanie sterowane czasem i impulsami, co oznacza, że proces żądający nie czeka na odpowiedź i zamiast tego przechodzi do następnego zadania zgodnie z czasem. Po otrzymaniu odpowiedzi proces żądający przechodzi do zmiany odpowiedzi. ScRapy może bez wysiłku wykonywać duże zadania. Może indeksować grupę adresów URL w mniej niż minutę, w zależności od wielkości grupy, i robi to niezwykle szybko, ponieważ wykorzystuje Twister do równoległości, który działa asynchronicznie (bez blokowania).