
隨機森林超參數調整:用編碼解釋的過程
已發表: 2020-12-23隨機森林是一種以決策樹為基礎的機器學習算法。 隨機森林易於使用且是一種靈活的 ML 算法。 由於其簡單性和多樣性,它被廣泛使用。 它在許多分類任務上都給出了很好的結果,即使沒有太多的超參數調整。
在本文中,我們將主要關注隨機森林的工作以及可以控制以獲得最佳結果的不同超參數。 由於每個數據都有其特徵,因此需要進行超參數調整。
這些特徵可以是變量的類型、數據的大小、二元/多類目標變量、分類變量中的類別數量、數值數據的標準差、數據的正態性等。因此,根據數據調整模型對於最大化模型的性能。
目錄
建設和工作
隨機森林算法作為大量去相關決策樹的集合。 它也被稱為裝袋技術。 Bagging 屬於集成學習的範疇,它基於這樣的理論:噪聲模型和無偏模型的組合可以平均化以創建具有低方差的模型。 讓我們了解如何構建隨機森林。
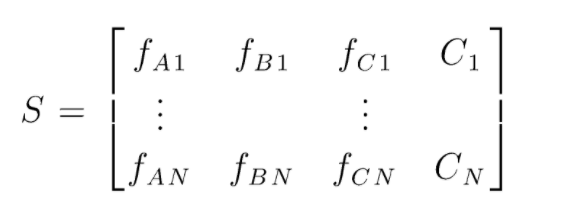
S 是用於執行隨機森林分類的數據矩陣。 存在 N 個實例,A、B、C 是數據的特徵。 根據這些數據,創建隨機的數據子集。 在哪些決策樹上創建。 從下圖中我們可以看出,每個數據子集創建一個決策樹,並且根據數據的大小,決策樹也會增加。
所有經過訓練的決策樹的輸出都經過投票,多數投票的類別是隨機森林算法的有效輸出。 決策樹模型過度擬合數據,因此需要隨機森林。 決策樹模型可能是低偏差,但它們大多是高方差。 因此,為了減少測試集上的方差誤差,使用了隨機森林。

超參數
在隨機森林中可以控制多種超參數:
- N_estimators:在森林中構建的決策樹的數量。 sklearn 中的默認值為 100。N_estimators 主要與數據的大小相關,為了封裝數據中的趨勢,需要更多數量的 DT。
- 標準:用於衡量決策樹中拆分質量的函數(分類問題)。 支持的標準是基尼係數:基尼係數雜質或熵:信息增益。 在回歸的情況下,可以使用平均絕對誤差 (MAE) 或均方誤差 (MSE)。 默認為 gini 和 mse。
- Max_depth:決策樹中允許的最大級別。 如果設置為空,決策樹將繼續分裂,直到達到純度。
- Max_features:用於節點拆分過程的最大特徵數。 類型:sqrt、log2。 如果總特徵為 n_features,則:可以選擇 sqrt(n_features) 或 log2(n_features) 作為節點拆分的最大特徵。
- Bootstrap:如果在 bootstrap 中選擇 True,則在構建決策樹時使用 Bootstrap 樣本,否則將整個數據用於每個決策樹。
- Min_samples_split:此參數決定拆分內部節點所需的最小樣本數。 默認值 =2。 這麼小的值的問題是在終端節點上檢查條件。 如果節點中的數據點超過值 2,則進一步拆分。 而如果設置更寬鬆的值(如 6),則拆分將提前停止,並且決策樹不會過度擬合數據。
- Min_sample_leaf:此參數設置決策樹節點中數據點要求的最小數量。 它影響終端節點,基本上有助於控制樹的深度。 如果拆分後節點中的數據點低於 min_sample_leaf 數字,則拆分將不會通過並將在父節點處停止。
在超參數調整過程中,還可以考慮其他不太重要的參數。
n_jobs:可用於訓練的處理器數量。 (-1 表示無限制)
max_samples:每個決策樹中可以使用的最大數據
random_state:具有特定 random_state 的模型將產生相似的準確度/輸出。
Class_weight:字典輸入,可以處理不平衡的數據集。
必讀:人工智能算法的類型
超參數調整過程
有多種方法可以執行超參數調整過程。 在創建和評估基礎模型後,可以調整超參數以增加一些特定的指標,例如模型的準確性或 f1 分數。
必須檢查調整前後的過度擬合和偏差方差誤差。 模型應根據實時要求進行調整。 有時,過擬合模型可能對驗證中的數據波動非常敏感,因此應在模型調整前後檢查交叉驗證分數與交叉驗證偏差是否可能出現過擬合。
接下來介紹在 python 上進行隨機森林調優的方法。
隨機搜索簡歷
我們可以使用 scikit learn 和 RandomisedSearchCV 來定義網格,隨機森林模型將通過從網格中隨機選擇參數來反复擬合。 我們不會得到最好的參數,但我們肯定會從正在擬合和測試的不同模型中得到最好的模型。

源代碼:
從 sklearn.model_selection 導入 GridSearchCV
# 創建一個參數的搜索網格,這些參數將被打亂
參數網格 = {
“引導程序”:[真],
'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 無],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimators': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# 使用隨機網格並蒐索最佳超參數
rf = RandomForestRegressor() #創建基礎模型
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 5, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit是啟動訓練過程
隨機搜索功能將通過 5 折交叉驗證和 100 次迭代來搜索參數,最終得到最佳參數。
網格搜索簡歷
在隨機搜索之後使用網格搜索來縮小範圍以搜索完美的超參數。 現在我們知道我們可以關注的地方,我們可以通過網格搜索明確地運行這些參數並評估不同的模型以獲得每個超參數的最終值。
源代碼:
從 sklearn.model_selection 導入 GridSearchCV
# 根據隨機搜索的結果創建參數網格
參數網格 = {
“引導程序”:[真],
'max_depth': [80, 90, 100, 110],
'max_features': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimators': [100, 200, 300, 1000]
}
# 創建一個基礎模型
rf = RandomForestRegressor()
# 實例化網格搜索模型
grid_search = GridSearchCV(估計器 = rf,param_grid = param_grid,
cv = 3,n_jobs = -1,詳細 = 2)
執行後的結果:
# 使網格搜索適合數據
grid_search.fit(train_features,train_labels)
grid_search.best_params_
{'bootstrap':是的,
“最大深度”:80,
“最大特徵”:3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_estimators': 100}
best_grid = grid_search.best_estimator_
另請閱讀:機器學習項目理念
結論
我們經歷了隨機森林模型的工作,以及每個超參數如何改變決策樹,從而改變整個隨機森林模型。 我們還研究了結合使用隨機搜索和網格搜索以獲得模型的最佳參數的有效技術。 超參數調整非常重要,因為它可以幫助我們控制模型的偏差和方差性能。
如果您有興趣了解有關決策樹、機器學習的更多信息,請查看 IIIT-B 和 upGrad 的機器學習和人工智能 PG 文憑,該文憑專為在職專業人士設計,提供 450 多個小時的嚴格培訓、30 多個案例研究和任務、IIIT-B 校友身份、5 個以上實用的實踐頂點項目和頂級公司的工作協助。
在隨機森林中可以調整哪些超參數?
在隨機森林中,超參數是樹的數量、特徵的數量和樹的類型(例如 GBM 或 M5)。 功能的數量很重要,應該進行調整。 在這種情況下,隨機森林很有用,因為它會自動調整特徵的數量。 樹的數量和樹的類型並不那麼重要,但絕對不要使用超過 500 棵樹,因為這是浪費時間。 一般來說,樹的類型和樹的數量是根據數據進行調整的。
如何優化隨機森林模型?
為了成功,隨機森林算法(和其他決策樹變體)的兩個主要組成部分是特徵選擇和樹結構。 關於樹結構,您將不得不試驗每棵樹中使用的樹的數量和特徵。 最重要的是,您需要找到模型足夠準確且不會過度擬合的最佳點。
機器學習中的隨機森林是什麼?
隨機森林是決策樹的集合。 它們是強大而靈活的模型,可以以多種不同的方式使用。 事實上,隨機森林在過去十年中變得非常流行。 該模型用於許多不同的領域(生物學、市場營銷、金融、文本挖掘等)。 它已在重大比賽中使用並產生了最先進的結果。 隨機森林最常見的用途是對數據進行分類(或標記)。 但是,它們也可以用於回歸連續值(估計一個值)和聚類相似的數據點。