
Ajuste de hiperparámetros de bosque aleatorio: procesos explicados con codificación
Publicado: 2020-12-23Random Forest es un algoritmo de aprendizaje automático que utiliza árboles de decisión como base. Random Forest es fácil de usar y un algoritmo ML flexible. Debido a su simplicidad y diversidad, se usa mucho. Da buenos resultados en muchas tareas de clasificación, incluso sin ajustar demasiado los hiperparámetros.
En este artículo, nos centraremos principalmente en el funcionamiento de Random Forest y los diferentes hiperparámetros que se pueden controlar para obtener resultados óptimos. La necesidad de ajuste de hiperparámetros surge porque cada dato tiene sus características.
Estas características pueden ser tipos de variables, tamaño de los datos, variable objetivo binaria/multiclase, número de categorías en variables categóricas, desviación estándar de datos numéricos, normalidad en los datos, etc. Por lo tanto, ajustar el modelo de acuerdo con los datos es imperativo para maximizar el rendimiento de un modelo.
Tabla de contenido
Construir y trabajar
Random Forest Algorithm funciona como una gran colección de árboles de decisión descorrelacionados. También se conoce como técnica de embolsado. El embolsado cae en la categoría de aprendizaje conjunto y se basa en la teoría de que la combinación de modelos ruidosos e imparciales se puede promediar para crear un modelo con baja varianza. Entendamos cómo se construye un Random Forest.
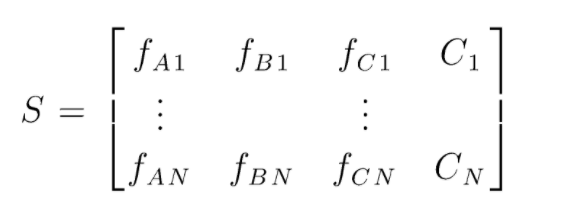
S es la matriz de datos presentes para realizar la clasificación aleatoria de bosques. Hay N instancias presentes y A,B,C son las características de los datos. A partir de estos datos, se crean subconjuntos aleatorios de datos. Sobre qué árboles de decisión se crean. Como podemos ver en la figura a continuación, se crea un árbol de decisión por subconjunto de datos y, según el tamaño de los datos, los árboles de decisión también aumentan.
Se vota la salida de todos los árboles de decisión entrenados y la clase votada por la mayoría es la salida efectiva de un algoritmo de bosque aleatorio. Los modelos de árboles de decisión sobreajustan los datos, por lo que surge la necesidad de Random Forest. Los modelos de árboles de decisión pueden tener un sesgo bajo, pero en su mayoría tienen una varianza alta. Por lo tanto, para reducir este error de varianza en el conjunto de prueba, se utiliza Random Forest.

Hiperparámetros
Hay varios hiperparámetros que se pueden controlar en un bosque aleatorio:
- N_estimadores: el número de árboles de decisión que se están construyendo en el bosque. Los valores predeterminados en sklearn son 100. Los N_estimadores se correlacionan principalmente con el tamaño de los datos, para encapsular las tendencias en los datos, se necesita una mayor cantidad de DT.
- Criterio: la función que se utiliza para medir la calidad de las divisiones en un árbol de decisión (problema de clasificación). Los criterios admitidos son gini: impureza de gini o entropía: ganancia de información. En caso de regresión, se puede utilizar el error absoluto medio (MAE) o el error cuadrático medio (MSE). El valor predeterminado es gini y mse.
- Max_depth: los niveles máximos permitidos en un árbol de decisión. Si se establece en nada, el árbol de decisión seguirá dividiéndose hasta que se alcance la pureza.
- Max_features: número máximo de funciones utilizadas para un proceso de división de nodos. Tipos: sqrt, log2. Si el total de características es n_características, entonces: sqrt(n_características) o log2(n_características) se pueden seleccionar como características máximas para la división de nodos.
- Bootstrap: las muestras de Bootstrap se usan al crear árboles de decisión si se selecciona True en bootstrap, de lo contrario, se usan datos completos para cada árbol de decisión.
- Min_samples_split: este parámetro decide el número mínimo de muestras necesarias para dividir un nodo interno. Valor por defecto =2. El problema con un valor tan pequeño es que la condición se verifica en el nodo terminal. Si los puntos de datos en el nodo superan el valor 2, se produce una división adicional. Mientras que si se establece un valor más indulgente como 6, la división se detendrá antes de tiempo y el árbol de decisión no se ajustará demasiado a los datos.
- Min_sample_leaf: este parámetro establece el número mínimo de requisitos de puntos de datos en un nodo del árbol de decisión. Afecta al nodo terminal y básicamente ayuda a controlar la profundidad del árbol. Si después de una división, los puntos de datos en un nodo pasan por debajo del número min_sample_leaf, la división no se realizará y se detendrá en el nodo principal.
Hay otros parámetros menos importantes que también se pueden considerar durante el proceso de ajuste de hiperparámetros.
n_jobs: número de procesadores que se pueden utilizar para el entrenamiento. (-1 para sin límite)
max_samples: los datos máximos que se pueden usar en cada árbol de decisión
estado_aleatorio: el modelo con un estado_aleatorio específico producirá una precisión/resultados similares.
Class_weight: entrada de diccionario, que puede manejar conjuntos de datos desequilibrados.
Debe leer: Tipos de algoritmo de IA
Procesos de ajuste de hiperparámetros
Hay varias formas de realizar procesos de ajuste de hiperparámetros. Una vez que se ha creado y evaluado el modelo base, se pueden ajustar los hiperparámetros para aumentar algunas métricas específicas, como la precisión o la puntuación f1 del modelo.
Se debe verificar el sobreajuste y los errores de varianza del sesgo antes y después de los ajustes. El modelo debe ajustarse de acuerdo con el requisito de tiempo real. A veces, un modelo con sobreajuste puede ser muy sensible a la fluctuación de los datos en la validación, por lo tanto, las puntuaciones de validación cruzada con la desviación de validación cruzada deben verificarse para detectar un posible sobreajuste antes y después del ajuste del modelo.

Los métodos para el ajuste de Random Forest en python se tratan a continuación.
CV de búsqueda aleatoria
Podemos usar scikit learn y RandomisedSearchCV donde podemos definir la cuadrícula, el modelo de bosque aleatorio se ajustará una y otra vez seleccionando aleatoriamente parámetros de la cuadrícula. No obtendremos los mejores parámetros, pero definitivamente obtendremos el mejor modelo de los diferentes modelos que se están ajustando y probando.
Código fuente:
de sklearn.model_selection importar GridSearchCV
# Cree una cuadrícula de búsqueda de parámetros que se barajarán
param_grid = {
'arranque': [Verdadero],
'max_ depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, Ninguno],
'max_features': ['automático', 'raíz cuadrada'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimadores': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# Usar la cuadrícula aleatoria y buscar los mejores hiperparámetros
rf = RandomForestRegressor() #creando modelo base
rf_random = RandomizedSearchCV(estimador = rf, param_distributions = random_grid, n_iter = 100, cv = 5, detallado=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit es para iniciar el proceso de entrenamiento
La función de búsqueda aleatoria buscará los parámetros a través de una validación cruzada de 5 veces y 100 iteraciones para terminar con los mejores parámetros.
Cuadrícula Buscar CV
La búsqueda en cuadrícula se usa después de la búsqueda aleatoria para reducir el rango y buscar los hiperparámetros perfectos. Ahora que sabemos dónde podemos enfocarnos, podemos ejecutar explícitamente esos parámetros a través de la búsqueda de cuadrícula y evaluar diferentes modelos para obtener los valores finales para cada hiperparámetro.
Código fuente:
de sklearn.model_selection importar GridSearchCV
# Crear la cuadrícula de parámetros basada en los resultados de la búsqueda aleatoria
param_grid = {
'arranque': [Verdadero],
'profundidad_máxima': [80, 90, 100, 110],
'características_máximas': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimadores': [100, 200, 300, 1000]
}
# Crear un modelo basado
rf = RandomForestRegresor()
# Crear una instancia del modelo de búsqueda de cuadrícula
grid_search = GridSearchCV(estimador = rf, param_grid = param_grid,
cv = 3, n_trabajos = -1, detallado = 2)
Resultados después de la ejecución:
# Ajustar la búsqueda de cuadrícula a los datos
grid_search.fit(entrenar_características, entrenar_etiquetas)
grid_search.mejores_parámetros_
{'arranque': Cierto,
'máx_profundidad': 80,
'características_máximas': 3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_estimadores': 100}
best_grid = grid_search.best_estimator_
Lea también: Ideas de proyectos de aprendizaje automático
Conclusión
Examinamos el funcionamiento de un modelo de bosque aleatorio y cómo funciona cada hiperparámetro para alterar los árboles de decisión y, por lo tanto, el modelo de bosque aleatorio en su conjunto. También echamos un vistazo a la técnica eficiente para combinar el uso de búsqueda aleatoria y de cuadrícula para obtener los mejores parámetros para nuestro modelo. El ajuste de hiperparámetros es muy importante ya que nos ayuda a controlar el sesgo y el rendimiento de la varianza de nuestro modelo.
Si está interesado en obtener más información sobre el árbol de decisiones, el aprendizaje automático, consulte el Diploma PG en aprendizaje automático e IA de IIIT-B y upGrad, que está diseñado para profesionales que trabajan y ofrece más de 450 horas de capacitación rigurosa, más de 30 estudios de casos y asignaciones, estado de exalumno de IIIT-B, más de 5 proyectos prácticos finales prácticos y asistencia laboral con las mejores empresas.
¿Qué hiperparámetros se pueden ajustar en un bosque aleatorio?
En Random Forest, los hiperparámetros son la cantidad de árboles, la cantidad de características y el tipo de árboles (como GBM o M5). El número de funciones es importante y debe ajustarse. En este caso, el bosque aleatorio es útil porque ajusta automáticamente la cantidad de características. La cantidad de árboles y el tipo de árboles no son tan importantes, pero uno nunca debe usar más de 500 árboles porque es una pérdida de tiempo. En términos generales, el tipo de árboles y la cantidad de árboles se ajustan de acuerdo con los datos.
¿Cómo se optimiza un modelo de Random Forest?
Para tener éxito, los dos componentes principales del algoritmo Random Forest (y otras variantes del árbol de decisión) son la selección de características y la estructura del árbol. Con respecto a la estructura del árbol, tendrá que experimentar con la cantidad de árboles y las características utilizadas en cada árbol. Lo más importante es que debe encontrar ese punto óptimo en el que su modelo sea lo suficientemente preciso y no se ajuste demasiado.
¿Qué es Random Forest en el aprendizaje automático?
Los bosques aleatorios son un conjunto de árboles de decisión. Son modelos potentes y flexibles que se pueden utilizar de muchas maneras diferentes. De hecho, los bosques aleatorios se han vuelto muy populares durante la última década. El modelo se utiliza en muchos campos diferentes (biología, marketing, finanzas, minería de texto, etc.). Se ha utilizado en las principales competiciones y ha producido resultados de última generación. El uso más común de los bosques aleatorios es clasificar (o etiquetar) datos. Pero también se pueden usar para retroceder valores continuos (estimar un valor) y para agrupar puntos de datos similares.