
ランダムフォレストのハイパーパラメータ調整:コーディングで説明されるプロセス
公開: 2020-12-23ランダムフォレストは、決定木をベースとして使用する機械学習アルゴリズムです。 ランダムフォレストは使いやすく、柔軟なMLアルゴリズムです。 そのシンプルさと多様性のために、それは非常に広く使われています。 ハイパーパラメータの調整をあまり行わなくても、多くの分類タスクで良好な結果が得られます。
この記事では、ランダムフォレストの動作と、最適な結果を得るために制御できるさまざまなハイパーパラメーターに主に焦点を当てます。 すべてのデータに特性があるため、ハイパーパラメータ調整の必要性が生じます。
これらの特性には、変数のタイプ、データのサイズ、バイナリ/マルチクラスターゲット変数、カテゴリ変数のカテゴリ数、数値データの標準偏差、データの正規性などがあります。したがって、データに応じてモデルを調整することが不可欠です。モデルのパフォーマンスを最大化します。
目次
構築と作業
ランダムフォレストアルゴリズムは、非相関の決定木の大規模なコレクションとして機能します。 バギング技術としても知られています。 バギングはアンサンブル学習のカテゴリに分類され、ノイズの多いモデルとバイアスのないモデルの組み合わせを平均化して、分散の少ないモデルを作成できるという理論に基づいています。 ランダムフォレストがどのように構築されているかを理解しましょう。
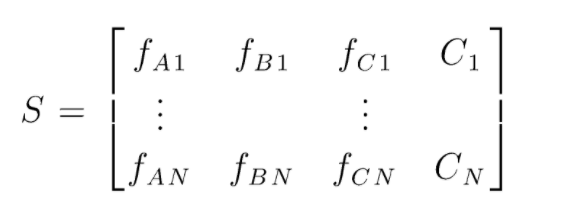
Sは、ランダムフォレスト分類を実行するために存在するデータのマトリックスです。 N個のインスタンスが存在し、A、B、Cがデータの特徴です。 このデータから、データのランダムなサブセットが作成されます。 どの決定木が作成されるか。 下の図からわかるように、データのサブセットごとに1つの決定木が作成され、データのサイズに応じて、決定木も増加します。
トレーニングされたすべての決定木の出力が投票され、多数決されたクラスがランダムフォレストアルゴリズムの効果的な出力になります。 デシジョンツリーモデルはデータに適合しすぎているため、ランダムフォレストが必要になります。 デシジョンツリーモデルは低バイアスである可能性がありますが、ほとんどの場合、分散が大きくなります。 したがって、テストセットでのこの分散エラーを減らすために、ランダムフォレストが使用されます。

ハイパーパラメータ
ランダムフォレストで制御できるさまざまなハイパーパラメータがあります。
- N_estimators:フォレストに構築されている決定木の数。 sklearnのデフォルト値は100です。N_estimatorsは主にデータのサイズと相関関係があり、データの傾向をカプセル化するには、より多くのDTが必要です。
- 基準:決定木の分割の品質を測定するために使用される関数(分類問題)。 サポートされている基準は、ジニ:ジニ不純物またはエントロピー:情報ゲインです。 回帰の場合、平均絶対誤差(MAE)または平均二乗誤差(MSE)を使用できます。 デフォルトはginiとmseです。
- Max_depth:デシジョンツリーで許可される最大レベル。 何も設定されていない場合、決定木は純度に達するまで分割を続けます。
- Max_features:ノード分割プロセスに使用される機能の最大数。 タイプ:sqrt、log2。 合計機能がn_featuresの場合、ノード分割の最大機能としてsqrt(n_features)またはlog2(n_features)を選択できます。
- ブートストラップ:ブートストラップでTrueが選択されている場合、決定木を構築するときにブートストラップサンプルが使用されます。それ以外の場合は、すべての決定木にデータ全体が使用されます。
- Min_samples_split:このパラメーターは、内部ノードを分割するために必要なサンプルの最小数を決定します。 デフォルト値=2。 このような小さな値の問題は、条件がターミナルノードでチェックされることです。 ノード内のデータポイントが値2を超えると、さらに分割が行われます。 一方、6のようなより寛大な値が設定されている場合、分割は早期に停止し、決定木はデータに過剰適合しません。
- Min_sample_leaf:このパラメーターは、決定木のノード内のデータポイント要件の最小数を設定します。 これはターミナルノードに影響を与え、基本的にツリーの深さを制御するのに役立ちます。 分割後、ノード内のデータポイントがmin_sample_leaf番号を下回る場合、分割は実行されず、親ノードで停止されます。
ハイパーパラメータ調整プロセス中に考慮することもできる、それほど重要ではないパラメータが他にもあります。
n_jobs:トレーニングに使用できるプロセッサの数。 (制限なしの場合は-1)
max_samples:各ディシジョンツリーで使用できる最大データ
random_state:特定のrandom_stateを持つモデルは、同様の精度/出力を生成します。
Class_weight:不均衡なデータセットを処理できる辞書入力。
必読: AIアルゴリズムの種類
ハイパーパラメータ調整プロセス
ハイパーパラメータ調整プロセスを実行するには、さまざまな方法があります。 基本モデルを作成して評価した後、ハイパーパラメータを調整して、モデルの精度やf1スコアなどの特定の指標を増やすことができます。
調整の前後で、過剰適合と偏りの分散の誤差を確認する必要があります。 モデルは、リアルタイムの要件に従って調整する必要があります。 過剰適合モデルは、検証のデータ変動に非常に敏感である場合があるため、モデル調整の前後に、交差検証偏差を含む交差検証スコアをチェックして、過剰適合の可能性を確認する必要があります。
次に、Pythonでランダムフォレストを調整する方法について説明します。

ランダム化された検索CV
グリッドを定義できるscikitlearnとRandomisedSearchCVを使用できます。ランダムフォレストモデルは、グリッドからパラメーターをランダムに選択することで何度も適合されます。 最良のパラメーターを取得することはできませんが、取り付けおよびテストされているさまざまなモデルから確実に最良のモデルを取得します。
ソースコード:
sklearn.model_selectionからインポートGridSearchCV
#シャッフルされるパラメータの検索グリッドを作成します
param_grid = {
'ブートストラップ':[True]、
'max_depth':[10、20、30、40、50、60、70、80、90、100、なし]、
'max_features':['auto'、'sqrt']、
'min_samples_leaf':[1、2、4]、
'min_samples_split':[2、5、10]、
'n_estimators':[200、400、600、800、1000、1200、1400、1600、1800、2000]
}
#ランダムグリッドを使用して、最適なハイパーパラメータを検索する
rf = RandomForestRegressor()#ベースモデルの作成
rf_random = RandomizedSearchCV(estimator = rf、param_distributions = random_grid、n_iter = 100、cv = 5、verbose = 2、random_state = 42、n_jobs = -1)
rf_random.fit(train_features、train_labels)#fitはトレーニングプロセスを開始することです
ランダム化された検索機能は、5分割交差検定と100回の反復によってパラメーターを検索し、最終的に最良のパラメーターを取得します。
グリッド検索CV
グリッド検索は、ランダム検索の後に使用され、範囲を絞り込んで完全なハイパーパラメータを検索します。 どこに焦点を合わせることができるかがわかったので、グリッド検索を通じてこれらのパラメーターを明示的に実行し、さまざまなモデルを評価して、すべてのハイパーパラメーターの最終値を取得できます。
ソースコード:
sklearn.model_selectionからインポートGridSearchCV
#ランダム検索の結果に基づいてパラメータグリッドを作成します
param_grid = {
'ブートストラップ':[True]、
'max_depth':[80、90、100、110]、
'max_features':[2、3]、
'min_samples_leaf':[3、4、5]、
'min_samples_split':[8、10、12]、
'n_estimators':[100、200、300、1000]
}
#ベースモデルを作成する
rf = RandomForestRegressor()
#グリッド検索モデルをインスタンス化する
grid_search = GridSearchCV(estimator = rf、param_grid = param_grid、
cv = 3、n_jobs = -1、verbose = 2)
実行後の結果:
#グリッド検索をデータに適合させる
grid_search.fit(train_features、train_labels)
grid_search.best_params_
{'ブートストラップ':真、
'max_depth':80、
'max_features':3、
'min_samples_leaf':5、
'min_samples_split':12、
'n_estimators':100}
best_grid = grid_search.best_estimator_
また読む:機械学習プロジェクトのアイデア
結論
ランダムフォレストモデルの作業と、各ハイパーパラメータがどのように機能して決定木を変更するか、したがってランダムフォレストモデル全体を変更する方法について説明しました。 また、ランダム化検索とグリッド検索の使用を組み合わせて、モデルに最適なパラメーターを取得するための効率的な手法についても検討しました。 ハイパーパラメータの調整は、モデルのバイアスと分散のパフォーマンスを制御するのに役立つため、非常に重要です。
デシジョンツリー、機械学習について詳しく知りたい場合は、IIIT-BとupGradの機械学習とAIのPGディプロマをご覧ください。これは、働く専門家向けに設計されており、450時間以上の厳格なトレーニング、30以上のケーススタディを提供しています。課題、IIIT-B卒業生のステータス、5つ以上の実践的なキャップストーンプロジェクト、トップ企業との仕事の支援。
ランダムフォレストで調整できるハイパーパラメータはどれですか?
ランダムフォレストでは、ハイパーパラメータはツリーの数、フィーチャの数、およびツリーのタイプ(GBMやM5など)です。 機能の数は重要であり、調整する必要があります。 この場合、ランダムフォレストは特徴の数を自動的に調整するため、便利です。 木の数や種類はそれほど重要ではありませんが、時間の無駄なので500本以上は絶対に使わないでください。 一般的に、木の種類と数はデータに応じて調整されます。
ランダムフォレストモデルをどのように最適化しますか?
成功するために、ランダムフォレストアルゴリズム(および他の決定木バリアント)の2つの主要なコンポーネントは、機能の選択とツリー構造です。 ツリー構造に関しては、ツリーの数と各ツリーで使用される機能を実験する必要があります。 最も重要なことは、モデルが十分に正確であり、過剰適合しないスイートスポットを見つける必要があることです。
機械学習におけるランダムフォレストとは何ですか?
ランダムフォレストは、決定木の集合体です。 これらは、さまざまな方法で使用できる強力で柔軟なモデルです。 実際、ランダムフォレストは過去10年間で非常に人気があります。 このモデルは、さまざまな分野(生物学、マーケティング、財務、テキストマイニングなど)で使用されています。 主要な競技会で使用され、最先端の結果を生み出しています。 ランダムフォレストの最も一般的な使用法は、データを分類(またはラベル付け)することです。 ただし、連続値を回帰(値を推定)したり、同様のデータポイントをクラスター化したりするためにも使用できます。