
Random Forest Hyperparameter Tuning: Prozesse, die durch Codierung erklärt werden
Veröffentlicht: 2020-12-23Random Forest ist ein Algorithmus für maschinelles Lernen, der Entscheidungsbäume als Grundlage verwendet. Random Forest ist einfach zu bedienen und ein flexibler ML-Algorithmus. Aufgrund seiner Einfachheit und Vielfalt wird es sehr häufig verwendet. Es liefert gute Ergebnisse bei vielen Klassifizierungsaufgaben, auch ohne viel Hyperparameter-Tuning.
In diesem Artikel konzentrieren wir uns hauptsächlich auf die Funktionsweise von Random Forest und die verschiedenen Hyperparameter, die für optimale Ergebnisse gesteuert werden können. Die Notwendigkeit für Hyperparameter-Tuning entsteht, weil alle Daten ihre Eigenschaften haben.
Diese Merkmale können Arten von Variablen, Größe der Daten, binäre/mehrklassige Zielvariable, Anzahl der Kategorien in kategorialen Variablen, Standardabweichung numerischer Daten, Normalität in den Daten usw. sein. Daher ist es unerlässlich, das Modell entsprechend den Daten abzustimmen Maximierung der Leistung eines Modells.
Inhaltsverzeichnis
Bauen und Arbeiten
Der Random-Forest-Algorithmus funktioniert wie eine große Sammlung von dekorrelierten Entscheidungsbäumen. Es ist auch als Bagging-Technik bekannt. Bagging fällt in die Kategorie des Ensemble-Lernens und basiert auf der Theorie, dass die Kombination aus verrauschten und unvoreingenommenen Modellen gemittelt werden kann, um ein Modell mit geringer Varianz zu erstellen. Lassen Sie uns verstehen, wie ein Random Forest aufgebaut ist.
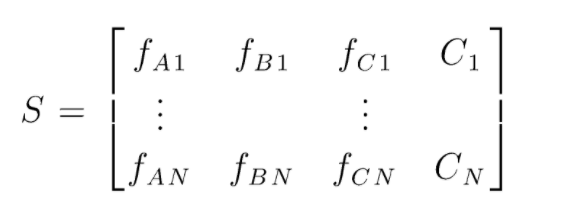
S ist die Datenmatrix, die zum Durchführen einer zufälligen Gesamtstrukturklassifizierung vorhanden ist. Es sind N Instanzen vorhanden und A, B, C sind die Merkmale der Daten. Aus diesen Daten werden zufällige Teilmengen von Daten erstellt. Über welche Entscheidungsbäume erstellt werden. Wie wir in der folgenden Abbildung sehen können, wird ein Entscheidungsbaum pro Teilmenge von Daten erstellt, und je nach Datengröße werden die Entscheidungsbäume auch erhöht.
Die Ausgabe aller trainierten Entscheidungsbäume wird abgestimmt, und die mehrheitlich gewählte Klasse ist die effektive Ausgabe eines Random-Forest-Algorithmus. Die Entscheidungsbaummodelle passen die Daten überan, daher entsteht die Notwendigkeit für Random Forest. Entscheidungsbaummodelle können Low Bias sein, aber sie haben meistens eine hohe Varianz. Um diesen Varianzfehler auf dem Testsatz zu reduzieren, wird daher Random Forest verwendet.

Hyperparameter
Es gibt verschiedene Hyperparameter, die in einem Random Forest gesteuert werden können:
- N_estimators: Die Anzahl der Entscheidungsbäume, die im Wald gebaut werden. Standardwerte in sklearn sind 100. N_estimators korrelieren hauptsächlich mit der Datengröße, um die Trends in den Daten einzukapseln, wird eine größere Anzahl von DTs benötigt.
- Kriterium: Die Funktion, die verwendet wird, um die Qualität von Splits in einem Entscheidungsbaum zu messen (Klassifikationsproblem). Unterstützte Kriterien sind Gini: Gini-Verunreinigung oder Entropie: Informationsgewinn. Im Falle einer Regression kann der mittlere absolute Fehler (MAE) oder der mittlere quadratische Fehler (MSE) verwendet werden. Standard ist gini und mse.
- Max_Tiefe: Die in einem Entscheidungsbaum maximal zulässigen Ebenen. Wenn auf nichts gesetzt, teilt sich der Entscheidungsbaum weiter, bis die Reinheit erreicht ist.
- Max_features: Maximale Anzahl von Features, die für einen Node-Split-Prozess verwendet werden. Typen: sqrt, log2. Wenn die gesamten Features n_features sind, dann: sqrt(n_features) oder log2(n_features) können als maximale Features für die Knotenaufteilung ausgewählt werden.
- Bootstrap: Bootstrap-Beispiele werden beim Erstellen von Entscheidungsbäumen verwendet, wenn True in Bootstrap ausgewählt ist, andernfalls werden für jeden Entscheidungsbaum ganze Daten verwendet.
- Min_samples_split: Dieser Parameter entscheidet über die minimale Anzahl von Samples, die zum Teilen eines internen Knotens erforderlich sind. Standardwert =2. Das Problem bei einem so kleinen Wert ist, dass die Bedingung auf dem Endknoten geprüft wird. Überschreiten die Datenpunkte im Knoten den Wert 2, erfolgt eine weitere Aufteilung. Wenn dagegen ein milderer Wert wie 6 festgelegt wird, stoppt die Aufteilung vorzeitig und der Entscheidungsbaum passt sich nicht zu stark an die Daten an.
- Min_sample_leaf: Dieser Parameter legt die minimale Anzahl von Datenpunktanforderungen in einem Knoten des Entscheidungsbaums fest. Es wirkt sich auf den Endknoten aus und hilft im Wesentlichen bei der Kontrolle der Tiefe des Baums. Wenn nach einer Teilung die Datenpunkte in einem Knoten unter die Zahl min_sample_leaf gehen, wird die Teilung nicht durchlaufen und am übergeordneten Knoten gestoppt.
Es gibt andere, weniger wichtige Parameter, die ebenfalls während des Hyperparameter-Tuning-Prozesses berücksichtigt werden können.
n_jobs: Anzahl der Prozessoren, die für das Training verwendet werden können. (-1 für unbegrenzt)
max_samples: die maximalen Daten, die in jedem Entscheidungsbaum verwendet werden können
random_state: Das Modell mit einem bestimmten random_state erzeugt ähnliche Genauigkeit/Ausgaben.
Class_weight: Dictionary-Eingabe, die unausgeglichene Datensätze verarbeiten kann.
Muss gelesen werden: Arten von KI-Algorithmen
Hyperparameter-Tuning-Prozesse
Es gibt verschiedene Möglichkeiten, Hyperparameter-Tuning-Prozesse durchzuführen. Nachdem das Basismodell erstellt und bewertet wurde, können Hyperparameter optimiert werden, um einige spezifische Metriken wie Genauigkeit oder f1-Wert des Modells zu erhöhen.

Man muss die Überanpassung und die Bias-Varianzfehler vor und nach den Anpassungen überprüfen. Das Modell sollte entsprechend der Echtzeitanforderung abgestimmt werden. Manchmal kann ein überangepasstes Modell sehr empfindlich auf Datenschwankungen bei der Validierung reagieren, daher sollten die Kreuzvalidierungsergebnisse mit der Kreuzvalidierungsabweichung vor und nach der Modelloptimierung auf mögliche Überanpassung überprüft werden.
Als Nächstes werden die Methoden für das Random Forest-Tuning in Python behandelt.
Randomisierter Such-Lebenslauf
Wir können scikit learn und RandomisedSearchCV verwenden, wo wir das Raster definieren können, das Random-Forest-Modell wird immer wieder angepasst, indem zufällig Parameter aus dem Raster ausgewählt werden. Wir werden nicht die besten Parameter bekommen, aber wir werden definitiv das beste Modell aus den verschiedenen Modellen bekommen, die angepasst und getestet werden.
Quellcode:
aus sklearn.model_selection import GridSearchCV
# Erstellen Sie ein Suchraster mit Parametern, die durchgemischt werden
param_grid = {
'bootstrap': [Wahr],
'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, Keine],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_Schätzer': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# Verwenden des Zufallsgitters und Suchen nach den besten Hyperparametern
rf = RandomForestRegressor() #Basismodell erstellen
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 5, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit soll den Trainingsprozess einleiten
Die randomisierte Suchfunktion durchsucht die Parameter durch 5-fache Kreuzvalidierung und 100 Iterationen, um die besten Parameter zu erhalten.
Grid Search-Lebenslauf
Die Rastersuche wird nach der randomisierten Suche verwendet, um den Bereich für die Suche nach den perfekten Hyperparametern einzugrenzen. Jetzt, da wir wissen, worauf wir uns konzentrieren können, können wir diese Parameter explizit durch die Rastersuche laufen lassen und verschiedene Modelle auswerten, um die endgültigen Werte für jeden Hyperparameter zu erhalten.
Quellcode:
aus sklearn.model_selection import GridSearchCV
# Erstellen Sie das Parameterraster basierend auf den Ergebnissen der zufälligen Suche
param_grid = {
'bootstrap': [Wahr],
'max_tiefe': [80, 90, 100, 110],
'max_features': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_schätzer': [100, 200, 300, 1000]
}
# Erstellen Sie ein basierendes Modell
rf = RandomForestRegressor()
# Instanziiere das Rastersuchmodell
grid_search = GridSearchCV(schätzer = rf, param_grid = param_grid,
cv = 3, n_jobs = -1, ausführlich = 2)
Ergebnisse nach Ausführung:
# Passen Sie die Rastersuche an die Daten an
grid_search.fit(Zugmerkmale, Zugbeschriftungen)
grid_search.best_params_
{'bootstrap': Stimmt,
'max_tiefe': 80,
'max_features': 3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_estimators': 100}
best_grid = grid_search.best_estimator_
Lesen Sie auch: Projektideen für maschinelles Lernen
Fazit
Wir gingen durch die Funktionsweise eines Random-Forest-Modells und wie jeder Hyperparameter funktioniert, um die Entscheidungsbäume und damit das Random-Forest-Modell als Ganzes zu verändern. Wir haben uns auch die effiziente Technik angesehen, um die Verwendung von randomisierter und Rastersuche zu kombinieren, um die besten Parameter für unser Modell zu erhalten. Hyperparameter-Tuning ist sehr wichtig, da es uns hilft, die Bias- und Varianzleistung unseres Modells zu kontrollieren.
Wenn Sie mehr über den Entscheidungsbaum Machine Learning erfahren möchten, sehen Sie sich das PG Diploma in Machine Learning & AI von IIIT-B & upGrad an, das für Berufstätige konzipiert ist und mehr als 450 Stunden strenge Schulungen, mehr als 30 Fallstudien und Aufgaben, IIIT-B-Alumni-Status, mehr als 5 praktische praktische Abschlussprojekte und Arbeitsunterstützung bei Top-Unternehmen.
Welche Hyperparameter können im Random Forest angepasst werden?
In Random Forest sind die Hyperparameter die Anzahl der Bäume, die Anzahl der Features und die Art der Bäume (z. B. GBM oder M5). Die Anzahl der Features ist wichtig und sollte abgestimmt werden. In diesem Fall ist Random Forest nützlich, da es die Anzahl der Features automatisch anpasst. Die Anzahl der Bäume und die Art der Bäume sind nicht so wichtig, aber man sollte nie mehr als 500 Bäume verwenden, weil es Zeitverschwendung ist. Im Allgemeinen werden die Art der Bäume und die Anzahl der Bäume gemäß den Daten abgestimmt.
Wie optimiert man ein Random-Forest-Modell?
Um erfolgreich zu sein, sind die beiden Hauptkomponenten des Random-Forest-Algorithmus (und anderer Entscheidungsbaumvarianten) die Auswahl von Merkmalen und die Baumstruktur. In Bezug auf die Baumstruktur müssen Sie mit der Anzahl der Bäume und Merkmale experimentieren, die in jedem Baum verwendet werden. Am wichtigsten ist, dass Sie den idealen Punkt finden, an dem Ihr Modell sowohl genau genug ist als auch nicht überpasst.
Was ist Random Forest beim maschinellen Lernen?
Random Forests sind ein Ensemble von Entscheidungsbäumen. Sie sind leistungsstarke und flexible Modelle, die vielseitig eingesetzt werden können. Tatsächlich sind zufällige Wälder in den letzten zehn Jahren sehr beliebt geworden. Das Modell wird in vielen verschiedenen Bereichen (Biologie, Marketing, Finanzen, Textmining etc.) verwendet. Es wurde bei großen Wettbewerben eingesetzt und hat Ergebnisse auf dem neuesten Stand der Technik hervorgebracht. Die häufigste Verwendung von Random Forests ist die Klassifizierung (oder Kennzeichnung) von Daten. Sie können aber auch verwendet werden, um kontinuierliche Werte zu regressieren (einen Wert zu schätzen) und ähnliche Datenpunkte zu gruppieren.