
Reglare aleatorie a hiperparametrului pădurii: procese explicate cu codare
Publicat: 2020-12-23Random Forest este un algoritm de învățare automată care folosește arbori de decizie ca bază. Random Forest este ușor de utilizat și este un algoritm ML flexibil. Datorită simplității și diversității sale, este utilizat pe scară largă. Oferă rezultate bune la multe sarcini de clasificare, chiar și fără prea multă reglare a hiperparametrilor.
În acest articol, ne vom concentra în principal pe funcționarea Random Forest și pe diferiții hiper parametri care pot fi controlați pentru rezultate optime. Necesitatea reglajului hiperparametrului apare deoarece fiecare dată are caracteristicile sale.
Aceste caracteristici pot fi tipuri de variabile, dimensiunea datelor, variabilă țintă binară/multiclasă, numărul de categorii în variabile categoriale, abaterea standard a datelor numerice, normalitatea datelor etc. Prin urmare, ajustarea modelului în funcție de date este imperativă pentru maximizarea performanței unui model.
Cuprins
Construiți și lucrați
Random Forest Algorithm funcționează ca o colecție mare de arbori de decizie decorelați. Este cunoscută și ca tehnică de însacare. Bagajul se încadrează în categoria învățării în ansamblu și se bazează pe teoria conform căreia combinația de modele zgomotoase și imparțiale poate fi mediată pentru a crea un model cu varianță scăzută. Să înțelegem cum este construită o pădure aleatorie.
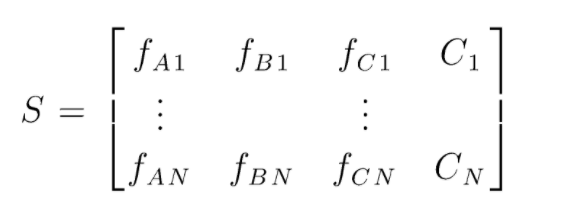
S este matricea datelor prezente pentru efectuarea clasificării aleatorii a pădurilor. Există N cazuri prezente și A,B,C sunt caracteristicile datelor. Din aceste date, sunt create subseturi aleatorii de date. Peste care arbori de decizie sunt creați. După cum putem vedea din figura de mai jos, un arbore de decizie este creat pentru fiecare subset de date și, în funcție de dimensiunea datelor, arborii de decizie sunt, de asemenea, măriți.
Rezultatul tuturor arborilor de decizie antrenați este votat și clasa votată cu majoritate este rezultatul efectiv al unui algoritm de pădure aleatorie. Modelele arborelui de decizie depășesc datele, astfel încât apare nevoia de Random Forest. Modelele de arbore de decizie pot avea o prejudecată scăzută, dar sunt în mare parte variate mari. Prin urmare, pentru a reduce această eroare de varianță pe setul de testare, se folosește Random Forest.

Hiperparametri
Există diverși hiperparametri care pot fi controlați într-o pădure aleatoare:
- N_estimatori: numărul de arbori de decizie construiți în pădure. Valorile implicite în sklearn sunt 100. N_estimatorii sunt în mare parte corelate cu dimensiunea datelor, pentru a încapsula tendințele în date, este nevoie de un număr mai mare de DT.
- Criteriu: Funcția care este utilizată pentru a măsura calitatea divizărilor într-un arbore de decizie (Problemă de clasificare). Criteriile acceptate sunt gini: gini impuritate sau entropie: câștig de informații. În cazul regresiei Eroare medie absolută (MAE) sau Eroare medie pătratică (MSE) pot fi utilizate. Implicit este gini și mse.
- Max_depth: nivelurile maxime permise într-un arbore de decizie. Dacă nu se setează, arborele de decizie va continua să se despartă până când se atinge puritatea.
- Max_features: numărul maxim de caracteristici utilizate pentru un proces de împărțire a nodurilor. Tipuri: sqrt, log2. Dacă caracteristicile totale sunt n_features, atunci: sqrt(n_features) sau log2(n_features) pot fi selectate ca caracteristici maxime pentru împărțirea nodurilor.
- Bootstrap: Eșantioanele Bootstrap sunt folosite la construirea arborilor de decizie dacă este selectat True în bootstrap, altfel sunt folosite date întregi pentru fiecare arbore de decizie.
- Min_samples_split: Acest parametru decide numărul minim de mostre necesare pentru a împărți un nod intern. Valoarea implicită =2. Problema cu o valoare atât de mică este că starea este verificată pe nodul terminal. Dacă punctele de date din nod depășesc valoarea 2, atunci are loc o împărțire ulterioară. În timp ce, dacă este setată o valoare mai îngăduitoare, cum ar fi 6, atunci împărțirea se va opri mai devreme și arborele de decizie nu se va supraadapta pe date.
- Min_sample_leaf: Acest parametru setează numărul minim de cerințe privind punctele de date într-un nod al arborelui de decizie. Afectează nodul terminal și, practic, ajută la controlul adâncimii arborelui. Dacă după o divizare, punctele de date dintr-un nod trec sub numărul min_sample_leaf, împărțirea nu va trece și va fi oprită la nodul părinte.
Există și alți parametri mai puțin importanți care pot fi luați în considerare și în timpul procesului de reglare a hiperparametrului.
n_jobs: numărul de procesoare care pot fi folosite pentru instruire. (-1 pentru fără limită)
max_samples: datele maxime care pot fi utilizate în fiecare Arbore de decizie
random_state: modelul cu o anumită stare_aleatorie va produce o precizie/ieșiri similare.
Class_weight: intrare în dicționar, care poate gestiona seturi de date dezechilibrate.
Trebuie citit: Tipuri de algoritm AI
Procese de reglare hiperparametrică
Există diferite moduri de a efectua procese de reglare hiperparametrică. După ce modelul de bază a fost creat și evaluat, hiperparametrii pot fi reglați pentru a crește anumite valori specifice, cum ar fi acuratețea sau scorul f1 al modelului.

Trebuie verificate supraajustarea și erorile de variație de polarizare înainte și după ajustări. Modelul trebuie reglat în funcție de cerința de timp real. Uneori, un model de supraadaptare poate fi foarte sensibil la fluctuația datelor în validare, prin urmare, scorurile de validare încrucișată cu abaterea de validare încrucișată ar trebui verificate pentru o posibilă supraadaptare înainte și după reglarea modelului.
Metodele pentru reglarea Random Forest pe python sunt acoperite în continuare.
CV de căutare aleatorie
Putem folosi scikit Learn și RandomisedSearchCV unde putem defini grila, modelul de pădure aleatoare va fi montat iar și iar prin selectarea aleatorie a parametrilor din grilă. Nu vom obține cei mai buni parametri, dar cu siguranță vom obține cel mai bun model din diferitele modele montate și testate.
Cod sursa:
din sklearn.model_selection import GridSearchCV
# Creați o grilă de căutare a parametrilor care vor fi amestecați
param_grid = {
„bootstrap”: [Adevărat],
„max_depth”: [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, Niciunul],
'max_features': ['auto', 'sqrt'],
„min_samples_leaf”: [1, 2, 4],
'min_samples_split': [2, 5, 10],
„n_estimators”: [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# Utilizarea grilei aleatoare și căutarea celor mai buni hiperparametri
rf = RandomForestRegressor() #crearea modelului de bază
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 5, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit este de a iniția procesul de formare
Funcția de căutare aleatorie va căuta parametrii prin validare încrucișată de 5 ori și 100 de iterații pentru a ajunge cu cei mai buni parametri.
CV-ul de căutare în grilă
Căutarea în grilă este utilizată după căutarea randomizată pentru a restrânge intervalul pentru a căuta hiperparametrii perfecți. Acum că știm unde ne putem concentra, putem rula în mod explicit acești parametri prin căutarea în grilă și putem evalua diferite modele pentru a obține valorile finale pentru fiecare hiperparametru.
Cod sursa:
din sklearn.model_selection import GridSearchCV
# Creați grila de parametri pe baza rezultatelor căutării aleatorii
param_grid = {
„bootstrap”: [Adevărat],
„max_depth”: [80, 90, 100, 110],
„max_features”: [2, 3],
„min_samples_leaf”: [3, 4, 5],
„min_samples_split”: [8, 10, 12],
„n_estimators”: [100, 200, 300, 1000]
}
# Creați un model bazat
rf = RandomForestRegressor()
# Instanciați modelul de căutare în grilă
grid_search = GridSearchCV(estimator = rf, param_grid = param_grid,
cv = 3, n_jobs = -1, verbose = 2)
Rezultate după execuție:
# Potriviți căutarea în grilă la date
grid_search.fit(train_features, train_labels)
grid_search.best_params_
{'bootstrap': Adevărat,
'max_depth': 80,
„max_features”: 3,
„min_samples_leaf”: 5,
„min_samples_split”: 12,
„n_estimators”: 100}
best_grid = grid_search.best_estimator_
Citește și: Idei de proiecte de învățare automată
Concluzie
Am trecut prin lucrul unui model de pădure aleatoare și cum funcționează fiecare hiperparametru pentru a modifica arborii de decizie și, prin urmare, modelul de pădure aleatoare în ansamblu. Ne-am uitat, de asemenea, la tehnica eficientă de a combina utilizarea căutării randomizate și grilă pentru a ajunge la cei mai buni parametri pentru modelul nostru. Reglarea hiperparametrului este foarte importantă, deoarece ne ajută să controlăm performanța și variația modelului nostru.
Dacă sunteți interesat să aflați mai multe despre arborele de decizie, Machine Learning, consultați IIIT-B & upGrad's PG Diploma in Machine Learning & AI, care este conceput pentru profesioniști care lucrează și oferă peste 450 de ore de formare riguroasă, peste 30 de studii de caz și misiuni, statutul de absolvenți IIIT-B, peste 5 proiecte practice practice și asistență la locul de muncă cu firme de top.
Ce hiperparametri pot fi reglați în pădure aleatoare?
În pădurea aleatoare, hiperparametrii sunt numărul de arbori, numărul de caracteristici și tipul de arbori (cum ar fi GBM sau M5). Numărul de funcții este important și trebuie reglat. În acest caz, pădurea aleatoare este utilă, deoarece reglează automat numărul de caracteristici. Numărul de copaci și tipul de copaci nu sunt atât de importante, dar nu ar trebui să folosiți niciodată peste 500 de copaci pentru că este o pierdere de timp. În general, tipul de arbori și numărul de arbori sunt reglate în funcție de date.
Cum optimizezi un model Random Forest?
Pentru a avea succes, cele două componente principale ale algoritmului Random Forest (și alte variante ale arborelui de decizie) sunt selecția caracteristicilor și structura arborelui. În ceea ce privește structura arborelui, va trebui să experimentați cu numărul de arbori și caracteristicile utilizate în fiecare arbore. Cel mai important, trebuie să găsești acel punct favorabil în care modelul tău este suficient de precis și nu se potrivește prea mult.
Ce este Random Forest în învățarea automată?
Pădurile aleatorii sunt un ansamblu de arbori de decizie. Sunt modele puternice și flexibile care pot fi utilizate în multe moduri diferite. De fapt, pădurile aleatorii au devenit foarte populare în ultimul deceniu. Modelul este utilizat în multe domenii diferite (biologie, marketing, finanțe, text mining etc.). A fost folosit în competiții importante și a produs rezultate de ultimă generație. Cea mai comună utilizare a pădurilor aleatorii este clasificarea (sau etichetarea) datelor. Dar, ele pot fi utilizate și pentru a regresa valori continue (estimarea unei valori) și pentru a grupa puncte de date similare.