
Ottimizzazione dell'iperparametro della foresta casuale: processi spiegati con la codifica
Pubblicato: 2020-12-23Random Forest è un algoritmo di Machine Learning che utilizza alberi decisionali come base. Random Forest è facile da usare e un algoritmo ML flessibile. Grazie alla sua semplicità e diversità, è ampiamente utilizzato. Dà buoni risultati in molte attività di classificazione, anche senza molta regolazione degli iperparametri.
In questo articolo, ci concentreremo principalmente sul funzionamento di Random Forest e sui diversi parametri iper che possono essere controllati per risultati ottimali. La necessità dell'ottimizzazione dell'iperparametro sorge perché ogni dato ha le sue caratteristiche.
Queste caratteristiche possono essere tipi di variabili, dimensione dei dati, variabile target binaria/multiclasse, numero di categorie nelle variabili categoriali, deviazione standard dei dati numerici, normalità nei dati, ecc. Pertanto, l'ottimizzazione del modello in base ai dati è fondamentale per massimizzare le prestazioni di un modello.
Sommario
Costruire e lavorare
Random Forest Algorithm funziona come un'ampia raccolta di alberi decisionali decorrelati. È anche noto come tecnica di insacco. Il baging rientra nella categoria dell'apprendimento d'insieme e si basa sulla teoria secondo cui la combinazione di modelli rumorosi e imparziali può essere calcolata in media per creare un modello con bassa varianza. Cerchiamo di capire come viene costruita una Foresta Casuale.
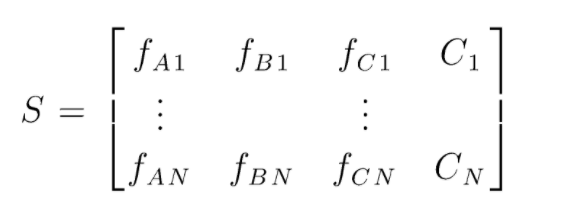
S è la matrice dei dati presenti per eseguire la classificazione casuale delle foreste. Sono presenti N istanze e A,B,C sono le caratteristiche dei dati. Da questi dati vengono creati sottoinsiemi casuali di dati. Su quali alberi decisionali vengono creati. Come possiamo vedere dalla figura seguente, viene creato un albero decisionale per sottoinsieme di dati e, a seconda della dimensione dei dati, vengono aumentati anche gli alberi decisionali.
L'output di tutti gli alberi decisionali addestrati viene votato e la classe votata dalla maggioranza è l'output effettivo di un algoritmo Random Forest. I modelli dell'albero decisionale si adattano ai dati, quindi sorge la necessità di Random Forest. I modelli dell'albero decisionale possono essere Low Bias, ma sono per lo più ad alta varianza. Quindi, per ridurre questo errore di varianza sul set di test, viene utilizzata la foresta casuale.

Iperparametri
Esistono vari iperparametri che possono essere controllati in una foresta casuale:
- N_estimators: il numero di alberi decisionali in costruzione nella foresta. I valori predefiniti in sklearn sono 100. Gli stimatori N sono per lo più correlati alla dimensione dei dati, per incapsulare le tendenze nei dati è necessario un numero maggiore di DT.
- Criterio: la funzione utilizzata per misurare la qualità delle suddivisioni in un albero decisionale (problema di classificazione). I criteri supportati sono gini: gini impurità o entropia: guadagno di informazioni. In caso di regressione è possibile utilizzare l'errore medio assoluto (MAE) o l'errore quadratico medio (MSE). L'impostazione predefinita è gini e mse.
- Max_depth: i livelli massimi consentiti in un albero decisionale. Se impostato su zero, l'albero decisionale continuerà a dividersi fino al raggiungimento della purezza.
- Max_features: numero massimo di funzioni utilizzate per un processo di suddivisione del nodo. Tipi: sqrt, log2. Se le funzionalità totali sono n_features, è possibile selezionare sqrt(n_features) o log2(n_features) come funzionalità massime per la divisione dei nodi.
- Bootstrap: i campioni Bootstrap vengono utilizzati durante la creazione di alberi decisionali se True è selezionato in bootstrap, altrimenti vengono utilizzati dati interi per ogni albero decisionale.
- Min_samples_split: questo parametro decide il numero minimo di campioni necessari per dividere un nodo interno. Valore predefinito =2. Il problema con un valore così piccolo è che la condizione viene verificata sul nodo terminale. Se i punti dati nel nodo superano il valore 2, si verifica un'ulteriore suddivisione. Considerando che se viene impostato un valore più indulgente come 6, la divisione si interromperà presto e l'albero decisionale non si adatterà ai dati.
- Min_sample_leaf: questo parametro imposta il numero minimo di requisiti del punto dati in un nodo dell'albero decisionale. Colpisce il nodo terminale e aiuta fondamentalmente a controllare la profondità dell'albero. Se dopo una divisione i punti dati in un nodo vanno sotto il numero min_sample_leaf, la divisione non andrà a buon fine e verrà interrotta nel nodo padre.
Ci sono altri parametri meno importanti che possono essere considerati anche durante il processo di ottimizzazione degli iperparametri.
n_jobs: numero di processori che possono essere utilizzati per la formazione. (-1 per nessun limite)
max_samples: i dati massimi che possono essere utilizzati in ogni Albero decisionale
random_state: il modello con uno specifico random_state produrrà accuratezza/output simili.
Class_weight: input del dizionario, in grado di gestire set di dati sbilanciati.
Da leggere: Tipi di algoritmi di intelligenza artificiale
Processi di ottimizzazione degli iperparametri
Esistono vari modi per eseguire processi di ottimizzazione degli iperparametri. Dopo che il modello di base è stato creato e valutato, gli iperparametri possono essere ottimizzati per aumentare alcune metriche specifiche come l'accuratezza o il punteggio f1 del modello.
È necessario controllare gli errori di overfitting e di varianza del bias prima e dopo le regolazioni. Il modello deve essere ottimizzato in base al requisito in tempo reale. A volte un modello di overfitting potrebbe essere molto sensibile alla fluttuazione dei dati nella convalida, quindi i punteggi della convalida incrociata con la deviazione della convalida incrociata dovrebbero essere controllati per un possibile overfit prima e dopo l'ottimizzazione del modello.

I metodi per l'ottimizzazione della foresta casuale su Python sono trattati di seguito.
CV di ricerca randomizzata
Possiamo usare scikit learn e RandomisedSearchCV dove possiamo definire la griglia, il modello di foresta casuale verrà adattato più e più volte selezionando casualmente i parametri dalla griglia. Non otterremo i parametri migliori, ma otterremo sicuramente il modello migliore dai diversi modelli montati e testati.
Codice sorgente:
da sklearn.model_selection importa GridSearchCV
# Crea una griglia di ricerca di parametri che verranno mischiati
param_grid = {
'bootstrap': [Vero],
'max_profondità': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, Nessuno],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimatori': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# Utilizzo della griglia casuale e ricerca dei migliori iperparametri
rf = RandomForestRegressor() #creazione del modello base
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 5, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit serve per avviare il processo di formazione
La funzione di ricerca randomizzata cercherà i parametri attraverso una convalida incrociata di 5 volte e 100 iterazioni per ottenere i parametri migliori.
CV di ricerca griglia
La ricerca della griglia viene utilizzata dopo la ricerca randomizzata per restringere l'intervallo per cercare gli iperparametri perfetti. Ora che sappiamo dove possiamo concentrarci, possiamo eseguire esplicitamente quei parametri attraverso la ricerca nella griglia e valutare diversi modelli per ottenere i valori finali per ogni iperparametro.
Codice sorgente:
da sklearn.model_selection importa GridSearchCV
# Creare la griglia dei parametri in base ai risultati della ricerca casuale
param_grid = {
'bootstrap': [Vero],
'max_profondità': [80, 90, 100, 110],
'caratteristiche_massime': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimatori': [100, 200, 300, 1000]
}
# Crea un modello basato
rf = RandomForestRegressor()
# Istanziare il modello di ricerca della griglia
grid_search = GridSearchCV(stimatore = rf, param_grid = param_grid,
cv = 3, n_jobs = -1, dettagliato = 2)
Risultati dopo l'esecuzione:
# Adatta la ricerca della griglia ai dati
grid_search.fit(caratteristiche_treno, etichette_treno)
grid_search.best_params_
{'bootstrap': Vero,
'max_profondità': 80,
'caratteristiche_massime': 3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_estimatori': 100}
best_grid = grid_search.best_estimator_
Leggi anche: Idee per progetti di apprendimento automatico
Conclusione
Abbiamo esaminato il funzionamento di un modello di foresta casuale e il modo in cui ogni iperparametro funziona per alterare gli alberi decisionali e quindi il modello di foresta casuale nel suo insieme. Abbiamo anche esaminato la tecnica efficiente per combinare l'uso della ricerca randomizzata e della griglia per ottenere i parametri migliori per il nostro modello. L'ottimizzazione dell'iperparametro è molto importante in quanto ci aiuta a controllare le prestazioni di bias e varianza del nostro modello.
Se sei interessato a saperne di più sull'albero decisionale, Machine Learning, dai un'occhiata al Diploma PG di IIIT-B e upGrad in Machine Learning e AI, progettato per i professionisti che lavorano e offre oltre 450 ore di formazione rigorosa, oltre 30 casi di studio e incarichi, stato di Alumni IIIT-B, oltre 5 progetti pratici pratici e assistenza sul lavoro con le migliori aziende.
Quali iperparametri possono essere regolati nella foresta casuale?
Nella foresta casuale, gli iperparametri sono il numero di alberi, il numero di caratteristiche e il tipo di alberi (come GBM o M5). Il numero di funzioni è importante e dovrebbe essere ottimizzato. In questo caso, la foresta casuale è utile perché ottimizza automaticamente il numero di funzionalità. Il numero di alberi e il tipo di alberi non sono così importanti, ma non si dovrebbero mai usare oltre 500 alberi perché è una perdita di tempo. In generale, il tipo di alberi e il numero di alberi sono regolati in base ai dati.
Come si ottimizza un modello Random Forest?
Per avere successo, le due componenti principali dell'algoritmo Random Forest (e altre varianti dell'albero decisionale) sono la selezione delle caratteristiche e la struttura ad albero. Per quanto riguarda la struttura dell'albero, dovrai sperimentare il numero di alberi e le caratteristiche utilizzate in ciascun albero. Ancora più importante, devi trovare quel punto debole in cui il tuo modello è sufficientemente preciso e non si adatta troppo.
Che cos'è Random Forest nell'apprendimento automatico?
Le foreste casuali sono un insieme di alberi decisionali. Sono modelli potenti e flessibili che possono essere utilizzati in molti modi diversi. In effetti, le foreste casuali sono diventate molto popolari nell'ultimo decennio. Il modello è utilizzato in molti campi diversi (biologia, marketing, finanza, text mining ecc.). È stato utilizzato nelle principali competizioni e ha prodotto risultati all'avanguardia. L'uso più comune delle foreste casuali consiste nel classificare (o etichettare) i dati. Ma possono anche essere usati per regredire valori continui (stimare un valore) e per raggruppare punti dati simili.