
การปรับแต่งไฮเปอร์พารามิเตอร์ของฟอเรสต์แบบสุ่ม: อธิบายกระบวนการด้วยการเข้ารหัส
เผยแพร่แล้ว: 2020-12-23Random Forest เป็นอัลกอริธึม Machine Learning ซึ่งใช้แผนผังการตัดสินใจเป็นฐาน Random Forest ใช้งานง่ายและอัลกอริธึม ML ที่ยืดหยุ่น เนื่องจากความเรียบง่ายและความหลากหลาย จึงมีการใช้กันอย่างแพร่หลาย ให้ผลลัพธ์ที่ดีในงานจำแนกหลายประเภท แม้จะไม่มีการปรับแต่งไฮเปอร์พารามิเตอร์มากนัก
ในบทความนี้ เราจะเน้นไปที่การทำงานของ Random Forest และพารามิเตอร์ไฮเปอร์ที่แตกต่างกันซึ่งสามารถควบคุมได้เพื่อให้ได้ผลลัพธ์ที่ดีที่สุด ความจำเป็นในการปรับแต่งไฮเปอร์พารามิเตอร์เกิดขึ้นเนื่องจากทุกข้อมูลมีลักษณะเฉพาะ
ลักษณะเหล่านี้อาจเป็นประเภทของตัวแปร ขนาดของข้อมูล ตัวแปรเป้าหมายไบนารี/หลายคลาส จำนวนหมวดหมู่ในตัวแปรหมวดหมู่ ค่าเบี่ยงเบนมาตรฐานของข้อมูลตัวเลข ความปกติในข้อมูล เป็นต้น ดังนั้น การปรับโมเดลตามข้อมูลจึงมีความจำเป็น การเพิ่มประสิทธิภาพของแบบจำลอง
สารบัญ
โครงสร้างและการทำงาน
Random Forest Algorithm ทำงานเป็นกลุ่มของต้นไม้ตัดสินใจเกี่ยวกับการตกแต่ง เป็นที่รู้จักกันว่าเทคนิคการบรรจุถุง การบรรจุถุงจัดอยู่ในหมวดหมู่ของการเรียนรู้ทั้งมวลและอยู่บนพื้นฐานของทฤษฎีที่ว่าการผสมผสานระหว่างแบบจำลองที่มีเสียงดังและเป็นกลางสามารถหาค่าเฉลี่ยเพื่อสร้างแบบจำลองที่มีความแปรปรวนต่ำ ให้เราเข้าใจว่าป่าสุ่มถูกสร้างขึ้นอย่างไร
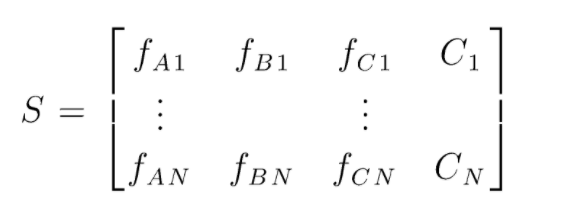
S คือเมทริกซ์ของข้อมูลที่มีอยู่สำหรับการจำแนกประเภทฟอเรสต์แบบสุ่ม มีอินสแตนซ์ N และ A,B,C เป็นคุณสมบัติของข้อมูล จากข้อมูลนี้ ข้อมูลชุดย่อยแบบสุ่มจะถูกสร้างขึ้น ต้นไม้การตัดสินใจใดถูกสร้างขึ้น ดังที่เราเห็นจากรูปด้านล่าง โครงสร้างการตัดสินใจหนึ่งชุดจะถูกสร้างขึ้นต่อชุดย่อยของข้อมูล และต้นไม้การตัดสินใจก็เพิ่มขึ้นด้วย ทั้งนี้ขึ้นอยู่กับขนาดของข้อมูล
ผลลัพธ์ของแผนภูมิการตัดสินใจที่ผ่านการฝึกอบรมทั้งหมดจะได้รับการโหวต และคลาสที่โหวตส่วนใหญ่คือผลลัพธ์ที่มีประสิทธิภาพของอัลกอริธึม Forest แบบสุ่ม แบบจำลองแผนผังการตัดสินใจมีข้อมูลมากเกินไป ดังนั้นจึงจำเป็นต้องมี Random Forest แบบจำลองแผนผังการตัดสินใจอาจเป็น Low Bias แต่ส่วนใหญ่มีความแปรปรวนสูง ดังนั้นเพื่อลดข้อผิดพลาดความแปรปรวนนี้ในชุดทดสอบ จึงใช้ Random Forest

ไฮเปอร์พารามิเตอร์
มีไฮเปอร์พารามิเตอร์ต่างๆ ที่สามารถควบคุมได้ในฟอเรสต์แบบสุ่ม:
- N_estimators: จำนวนต้นไม้ตัดสินใจที่ถูกสร้างขึ้นในป่า ค่าเริ่มต้นใน sklearn คือ 100 N_estimators ส่วนใหญ่สัมพันธ์กับขนาดของข้อมูล เพื่อสรุปแนวโน้มในข้อมูล จำเป็นต้องมี DT จำนวนมากขึ้น
- เกณฑ์: ฟังก์ชันที่ใช้วัดคุณภาพของการแยกในแผนผังการตัดสินใจ (Classification Problem) เกณฑ์ที่รองรับคือ gini: gini impurity หรือ entropy: information gain ในกรณีที่สามารถใช้ Regression Mean Absolute Error (MAE) หรือ Mean Squared Error (MSE) ได้ ค่าเริ่มต้นคือ gini และ mse
- Max_depth: ระดับสูงสุดที่อนุญาตในแผนผังการตัดสินใจ หากตั้งค่าเป็นไม่มีอะไร ต้นไม้ตัดสินใจจะแยกออกไปเรื่อยๆ จนกว่าจะถึงความบริสุทธิ์
- Max_features: จำนวนคุณลักษณะสูงสุดที่ใช้สำหรับกระบวนการแยกโหนด ประเภท: sqrt, log2 หากคุณสมบัติทั้งหมดเป็น n_features ดังนั้น: สามารถเลือก sqrt(n_features) หรือ log2(n_features) เป็นคุณสมบัติสูงสุดสำหรับการแยกโหนด
- Bootstrap: ตัวอย่าง Bootstrap จะใช้เมื่อสร้างแผนผังการตัดสินใจ ถ้า True ถูกเลือกใน bootstrap มิฉะนั้น ข้อมูลทั้งหมดจะถูกใช้สำหรับโครงสร้างการตัดสินใจทั้งหมด
- Min_samples_split: พารามิเตอร์นี้กำหนดจำนวนตัวอย่างขั้นต่ำที่จำเป็นในการแยกโหนดภายใน ค่าเริ่มต้น =2 ปัญหาเกี่ยวกับค่าเล็กน้อยดังกล่าวคือมีการตรวจสอบเงื่อนไขบนโหนดปลายทาง หากจุดข้อมูลในโหนดเกินค่า 2 การแยกส่วนเพิ่มเติมจะเกิดขึ้น ในขณะที่มีการตั้งค่าที่ผ่อนปรนมากขึ้นเช่น 6 การแยกจะหยุดก่อนและแผนภูมิการตัดสินใจจะไม่พอดีกับข้อมูลมากเกินไป
- Min_sample_leaf: พารามิเตอร์นี้กำหนดจำนวนขั้นต่ำของข้อกำหนดจุดข้อมูลในโหนดของแผนผังการตัดสินใจ มีผลกับโหนดปลายทางและโดยทั่วไปช่วยในการควบคุมความลึกของต้นไม้ หากหลังจากแยกจุดข้อมูลในโหนดภายใต้หมายเลข min_sample_leaf การแยกจะไม่ผ่านและจะหยุดที่โหนดหลัก
มีพารามิเตอร์อื่นๆ ที่มีความสำคัญน้อยกว่าที่สามารถพิจารณาได้ในระหว่างกระบวนการปรับแต่งไฮเปอร์พารามิเตอร์
n_jobs: จำนวนโปรเซสเซอร์ที่สามารถใช้ในการฝึกอบรมได้ (-1 สำหรับไม่จำกัด)
max_samples: ข้อมูลสูงสุดที่สามารถใช้ได้ในแต่ละ Decision Tree
random_state: โมเดลที่มี random_state เฉพาะจะสร้างความแม่นยำ/เอาต์พุตที่คล้ายคลึงกัน
Class_weight: อินพุตพจนานุกรมที่สามารถจัดการชุดข้อมูลที่ไม่สมดุล
ต้องอ่าน: ประเภทของอัลกอริทึม AI
กระบวนการปรับแต่งไฮเปอร์พารามิเตอร์
มีหลายวิธีในการทำกระบวนการปรับแต่งไฮเปอร์พารามิเตอร์ หลังจากสร้างและประเมินแบบจำลองพื้นฐานแล้ว สามารถปรับไฮเปอร์พารามิเตอร์เพื่อเพิ่มเมตริกเฉพาะบางอย่าง เช่น ความแม่นยำหรือคะแนน f1 ของโมเดล
ต้องตรวจสอบการใส่มากเกินไปและข้อผิดพลาดความแปรปรวนของอคติก่อนและหลังการปรับ ควรปรับโมเดลตามความต้องการแบบเรียลไทม์ บางครั้งแบบจำลองที่ใส่มากเกินไปอาจมีความไวมากต่อความผันผวนของข้อมูลในการตรวจสอบ ดังนั้นคะแนนการตรวจสอบความถูกต้องที่มีการเบี่ยงเบนการตรวจสอบความถูกต้องควรตรวจสอบเพื่อหาชุดที่พอดีได้ก่อนและหลังการปรับแต่งแบบจำลอง

วิธีการสำหรับการปรับแต่ง Random Forest บน python จะกล่าวถึงต่อไป
สุ่มค้นหา CV
เราสามารถใช้ scikit learn และ RandomisedSearchCV ที่ซึ่งเราสามารถกำหนดกริดได้ โมเดลฟอเรสต์แบบสุ่มจะถูกติดตั้งซ้ำแล้วซ้ำอีกโดยสุ่มเลือกพารามิเตอร์จากกริด เราจะไม่ได้รับพารามิเตอร์ที่ดีที่สุด แต่เราจะได้โมเดลที่ดีที่สุดจากรุ่นต่างๆ ที่ติดตั้งและทดสอบอย่างแน่นอน
รหัสแหล่งที่มา:
จาก sklearn.model_selection นำเข้า GridSearchCV
# สร้างตารางค้นหาของพารามิเตอร์ที่จะสับเปลี่ยนผ่าน
param_grid = {
'bootstrap': [จริง],
'max_deep': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, ไม่มี],
'max_features': ['อัตโนมัติ', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimators': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# ใช้ตารางสุ่มและค้นหาไฮเปอร์พารามิเตอร์ที่ดีที่สุด
rf = RandomForestRegressor() #creating base model
rf_random = RandomizedSearchCV (ตัวประมาณ = rf, param_distributions = random_grid, n_iter = 100, cv = 5, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit คือการเริ่มต้นกระบวนการฝึกอบรม
ฟังก์ชันการค้นหาแบบสุ่มจะค้นหาพารามิเตอร์ผ่านการตรวจสอบความถูกต้องข้าม 5 เท่าและการทำซ้ำ 100 ครั้งเพื่อให้ได้พารามิเตอร์ที่ดีที่สุด
ตารางค้นหา CV
การค้นหาแบบกริดจะใช้หลังจากการค้นหาแบบสุ่มเพื่อจำกัดช่วงให้แคบลงเพื่อค้นหาไฮเปอร์พารามิเตอร์ที่สมบูรณ์แบบ ตอนนี้เรารู้แล้วว่าจุดไหนที่เราโฟกัสได้ เราสามารถเรียกใช้พารามิเตอร์เหล่านั้นได้อย่างชัดเจนผ่านการค้นหาตารางและประเมินแบบจำลองต่างๆ เพื่อรับค่าสุดท้ายสำหรับไฮเปอร์พารามิเตอร์ทุกตัว
รหัสแหล่งที่มา:
จาก sklearn.model_selection นำเข้า GridSearchCV
# สร้างตารางพารามิเตอร์ตามผลลัพธ์ของการค้นหาแบบสุ่ม
param_grid = {
'bootstrap': [จริง],
'max_deep': [80, 90, 100, 110],
'max_features': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimators': [100, 200, 300, 1000]
}
# สร้างแบบจำลองตาม
rf = RandomForestRegressor ()
# สร้างโมเดลการค้นหากริด
grid_search = GridSearchCV (ตัวประมาณ = rf, param_grid = param_grid,
cv = 3, n_jobs = -1, verbose = 2)
ผลลัพธ์หลังการดำเนินการ:
# ปรับการค้นหากริดให้เข้ากับข้อมูล
grid_search.fit (train_features, train_labels)
grid_search.best_params_
{'bootstrap': จริง
'max_deep': 80,
'max_features': 3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_estimators': 100}
best_grid = grid_search.best_estimator_
อ่านเพิ่มเติม: แนวคิดโครงการการเรียนรู้ของเครื่อง
บทสรุป
เราได้ศึกษาการทำงานของโมเดลสุ่มฟอเรสต์และการทำงานของไฮเปอร์พารามิเตอร์แต่ละตัวเพื่อเปลี่ยนแผนผังการตัดสินใจ และด้วยเหตุนี้จึงทำให้โมเดลฟอเรสต์สุ่มโดยรวม นอกจากนี้เรายังได้ดูเทคนิคที่มีประสิทธิภาพในการรวมการใช้การค้นหาแบบสุ่มและแบบกริดเพื่อให้ได้พารามิเตอร์ที่ดีที่สุดสำหรับแบบจำลองของเรา การปรับแต่งไฮเปอร์พารามิเตอร์มีความสำคัญมาก เนื่องจากช่วยให้เราควบคุมอคติและความแปรปรวนของแบบจำลองของเราได้
หากคุณสนใจที่จะเรียนรู้เพิ่มเติมเกี่ยวกับโครงสร้างการตัดสินใจ แมชชีนเลิร์นนิง โปรดดูที่ IIIT-B & upGrad's PG Diploma in Machine Learning & AI ซึ่งออกแบบมาสำหรับมืออาชีพที่ทำงานและมีการฝึกอบรมอย่างเข้มงวดมากกว่า 450 ชั่วโมง กรณีศึกษามากกว่า 30+ การมอบหมายงาน, สถานะศิษย์เก่า IIIT-B, 5+ โครงการหลักที่ใช้งานได้จริง & ความช่วยเหลือด้านงานกับบริษัทชั้นนำ
ไฮเปอร์พารามิเตอร์ใดที่สามารถปรับค่าได้ในป่าสุ่ม
ในป่าสุ่ม ไฮเปอร์พารามิเตอร์คือจำนวนต้นไม้ จำนวนคุณสมบัติ และประเภทของต้นไม้ (เช่น GBM หรือ M5) จำนวนของคุณสมบัติมีความสำคัญและควรได้รับการปรับแต่ง ในกรณีนี้ ฟอเรสต์แบบสุ่มมีประโยชน์เพราะจะปรับจำนวนคุณสมบัติโดยอัตโนมัติ จำนวนต้นไม้และชนิดของต้นไม้ไม่สำคัญนัก แต่ไม่ควรใช้เกิน 500 ต้นเพราะเป็นการเสียเวลา โดยทั่วไป ชนิดของต้นไม้และจำนวนต้นไม้จะถูกปรับตามข้อมูล
คุณเพิ่มประสิทธิภาพโมเดล Random Forest ได้อย่างไร?
เพื่อให้ประสบความสำเร็จ สององค์ประกอบหลักของอัลกอริธึม Random Forest (และตัวแปรทรีการตัดสินใจอื่นๆ) คือการเลือกคุณสมบัติและโครงสร้างทรี เกี่ยวกับโครงสร้างต้นไม้ คุณจะต้องทดลองกับจำนวนต้นไม้และคุณสมบัติที่ใช้ในต้นไม้แต่ละต้น สิ่งสำคัญที่สุดคือ คุณต้องค้นหาจุดที่โมเดลของคุณมีความแม่นยำเพียงพอและไม่มากเกินไป
Random Forest ในการเรียนรู้ของเครื่องคืออะไร?
ป่าสุ่มเป็นกลุ่มของต้นไม้ตัดสินใจ เป็นรุ่นที่ทรงพลังและยืดหยุ่นซึ่งสามารถใช้งานได้หลายวิธี อันที่จริง ป่าสุ่มได้รับความนิยมอย่างมากในช่วงทศวรรษที่ผ่านมา แบบจำลองนี้ใช้ในหลายสาขา (ชีววิทยา การตลาด การเงิน การทำเหมืองข้อความ เป็นต้น) มันถูกใช้ในการแข่งขันที่สำคัญและได้ผลลัพธ์ที่ล้ำสมัย การใช้ฟอเรสต์สุ่มโดยทั่วไปคือการจำแนก (หรือติดป้ายกำกับ) ข้อมูล แต่ยังสามารถใช้เพื่อถดถอยค่าต่อเนื่อง (ประมาณค่า) และจัดกลุ่มจุดข้อมูลที่คล้ายคลึงกัน