
随机森林超参数调整:用编码解释的过程
已发表: 2020-12-23随机森林是一种以决策树为基础的机器学习算法。 随机森林易于使用且是一种灵活的 ML 算法。 由于其简单性和多样性,它被广泛使用。 它在许多分类任务上都给出了很好的结果,即使没有太多的超参数调整。
在本文中,我们将主要关注随机森林的工作以及可以控制以获得最佳结果的不同超参数。 由于每个数据都有其特征,因此需要进行超参数调整。
这些特征可以是变量的类型、数据的大小、二元/多类目标变量、分类变量中的类别数量、数值数据的标准差、数据的正态性等。因此,根据数据调整模型对于最大化模型的性能。
目录
建设和工作
随机森林算法作为大量去相关决策树的集合。 它也被称为装袋技术。 Bagging 属于集成学习的范畴,它基于这样的理论:噪声模型和无偏模型的组合可以平均化以创建具有低方差的模型。 让我们了解如何构建随机森林。
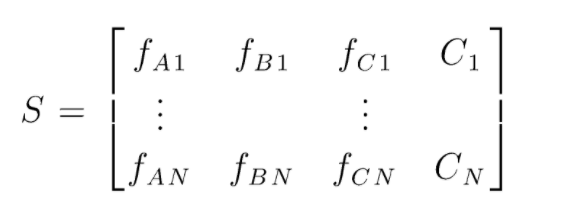
S 是用于执行随机森林分类的数据矩阵。 存在 N 个实例,A、B、C 是数据的特征。 根据这些数据,创建随机的数据子集。 在哪些决策树上创建。 从下图中我们可以看出,每个数据子集创建一个决策树,并且根据数据的大小,决策树也会增加。
所有经过训练的决策树的输出都经过投票,多数投票的类别是随机森林算法的有效输出。 决策树模型过度拟合数据,因此需要随机森林。 决策树模型可能是低偏差,但它们大多是高方差。 因此,为了减少测试集上的方差误差,使用了随机森林。

超参数
在随机森林中可以控制多种超参数:
- N_estimators:在森林中构建的决策树的数量。 sklearn 中的默认值为 100。N_estimators 主要与数据的大小相关,为了封装数据中的趋势,需要更多数量的 DT。
- 标准:用于衡量决策树中拆分质量的函数(分类问题)。 支持的标准是基尼系数:基尼系数杂质或熵:信息增益。 在回归的情况下,可以使用平均绝对误差 (MAE) 或均方误差 (MSE)。 默认为 gini 和 mse。
- Max_depth:决策树中允许的最大级别。 如果设置为空,决策树将继续分裂,直到达到纯度。
- Max_features:用于节点拆分过程的最大特征数。 类型:sqrt、log2。 如果总特征为 n_features,则:可以选择 sqrt(n_features) 或 log2(n_features) 作为节点拆分的最大特征。
- Bootstrap:如果在 bootstrap 中选择 True,则在构建决策树时使用 Bootstrap 样本,否则将整个数据用于每个决策树。
- Min_samples_split:此参数决定拆分内部节点所需的最小样本数。 默认值 =2。 这么小的值的问题是在终端节点上检查条件。 如果节点中的数据点超过值 2,则进一步拆分。 而如果设置更宽松的值(如 6),则拆分将提前停止,并且决策树不会过度拟合数据。
- Min_sample_leaf:此参数设置决策树节点中数据点要求的最小数量。 它影响终端节点,基本上有助于控制树的深度。 如果拆分后节点中的数据点低于 min_sample_leaf 数字,则拆分将不会通过并将在父节点处停止。
在超参数调整过程中,还可以考虑其他不太重要的参数。
n_jobs:可用于训练的处理器数量。 (-1 表示无限制)
max_samples:每个决策树中可以使用的最大数据
random_state:具有特定 random_state 的模型将产生相似的准确度/输出。
Class_weight:字典输入,可以处理不平衡的数据集。
必读:人工智能算法的类型
超参数调整过程
有多种方法可以执行超参数调整过程。 在创建和评估基础模型后,可以调整超参数以增加一些特定的指标,例如模型的准确性或 f1 分数。
必须检查调整前后的过度拟合和偏差方差误差。 模型应根据实时要求进行调整。 有时,过拟合模型可能对验证中的数据波动非常敏感,因此应在模型调整前后检查交叉验证分数与交叉验证偏差是否可能出现过拟合。
接下来介绍在 python 上进行随机森林调优的方法。
随机搜索简历
我们可以使用 scikit learn 和 RandomisedSearchCV 来定义网格,随机森林模型将通过从网格中随机选择参数来反复拟合。 我们不会得到最好的参数,但我们肯定会从正在拟合和测试的不同模型中得到最好的模型。

源代码:
从 sklearn.model_selection 导入 GridSearchCV
# 创建一个参数的搜索网格,这些参数将被打乱
参数网格 = {
“引导程序”:[真],
'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, 无],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimators': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# 使用随机网格并搜索最佳超参数
rf = RandomForestRegressor() #创建基础模型
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 5, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit是启动训练过程
随机搜索功能将通过 5 折交叉验证和 100 次迭代来搜索参数,最终得到最佳参数。
网格搜索简历
在随机搜索之后使用网格搜索来缩小范围以搜索完美的超参数。 现在我们知道我们可以关注的地方,我们可以通过网格搜索明确地运行这些参数并评估不同的模型以获得每个超参数的最终值。
源代码:
从 sklearn.model_selection 导入 GridSearchCV
# 根据随机搜索的结果创建参数网格
参数网格 = {
“引导程序”:[真],
'max_depth': [80, 90, 100, 110],
'max_features': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimators': [100, 200, 300, 1000]
}
# 创建一个基础模型
rf = RandomForestRegressor()
# 实例化网格搜索模型
grid_search = GridSearchCV(估计器 = rf,param_grid = param_grid,
cv = 3,n_jobs = -1,详细 = 2)
执行后的结果:
# 使网格搜索适合数据
grid_search.fit(train_features,train_labels)
grid_search.best_params_
{'bootstrap':是的,
“最大深度”:80,
“最大特征”:3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_estimators': 100}
best_grid = grid_search.best_estimator_
另请阅读:机器学习项目理念
结论
我们经历了随机森林模型的工作,以及每个超参数如何改变决策树,从而改变整个随机森林模型。 我们还研究了结合使用随机搜索和网格搜索以获得模型的最佳参数的有效技术。 超参数调整非常重要,因为它可以帮助我们控制模型的偏差和方差性能。
如果您有兴趣了解有关决策树、机器学习的更多信息,请查看 IIIT-B 和 upGrad 的机器学习和人工智能 PG 文凭,该文凭专为在职专业人士设计,提供 450 多个小时的严格培训、30 多个案例研究和任务、IIIT-B 校友身份、5 个以上实用的实践顶点项目和顶级公司的工作协助。
在随机森林中可以调整哪些超参数?
在随机森林中,超参数是树的数量、特征的数量和树的类型(例如 GBM 或 M5)。 功能的数量很重要,应该进行调整。 在这种情况下,随机森林很有用,因为它会自动调整特征的数量。 树的数量和树的类型并不那么重要,但绝对不要使用超过 500 棵树,因为这是浪费时间。 一般来说,树的类型和树的数量是根据数据进行调整的。
如何优化随机森林模型?
为了成功,随机森林算法(和其他决策树变体)的两个主要组成部分是特征选择和树结构。 关于树结构,您将不得不试验每棵树中使用的树的数量和特征。 最重要的是,您需要找到模型足够准确且不会过度拟合的最佳点。
机器学习中的随机森林是什么?
随机森林是决策树的集合。 它们是强大而灵活的模型,可以以多种不同的方式使用。 事实上,随机森林在过去十年中变得非常流行。 该模型用于许多不同的领域(生物学、市场营销、金融、文本挖掘等)。 它已在重大比赛中使用并产生了最先进的结果。 随机森林最常见的用途是对数据进行分类(或标记)。 但是,它们也可以用于回归连续值(估计一个值)和聚类相似的数据点。