
Ajuste de hiperparâmetros de floresta aleatória: processos explicados com codificação
Publicados: 2020-12-23Random Forest é um algoritmo de aprendizado de máquina que usa árvores de decisão como base. Random Forest é fácil de usar e um algoritmo de ML flexível. Devido à sua simplicidade e diversidade, é amplamente utilizado. Dá bons resultados em muitas tarefas de classificação, mesmo sem muito ajuste de hiperparâmetros.
Neste artigo, focaremos principalmente no funcionamento do Random Forest e nos diferentes hiperparâmetros que podem ser controlados para obter resultados ideais. A necessidade de ajuste de hiperparâmetros surge porque cada dado tem suas características.
Essas características podem ser tipos de variáveis, tamanho dos dados, variável de destino binária/multiclasse, número de categorias em variáveis categóricas, desvio padrão de dados numéricos, normalidade nos dados, etc. Portanto, ajustar o modelo de acordo com os dados é imperativo para maximizar o desempenho de um modelo.
Índice
Construir e Trabalhar
Random Forest Algorithm funciona como uma grande coleção de árvores de decisão descorrelacionadas. Também é conhecida como técnica de ensacamento. Bagging se enquadra na categoria de aprendizado de conjunto e é baseado na teoria de que a combinação de modelos ruidosos e imparciais pode ser calculada para criar um modelo com baixa variância. Vamos entender como uma Random Forest é construída.
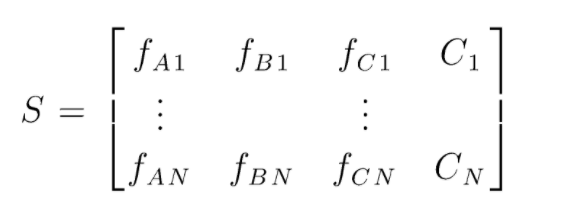
S é a matriz de dados presente para realizar a classificação aleatória de florestas. Existem N instâncias presentes e A,B,C são as características dos dados. A partir desses dados, são criados subconjuntos aleatórios de dados. Sobre quais árvores de decisão são criadas. Como podemos ver na figura abaixo, uma árvore de decisão é criada por subconjunto de dados e, dependendo do tamanho dos dados, as árvores de decisão também são aumentadas.
A saída de todas as árvores de decisão treinadas é votada e a classe votada pela maioria é a saída efetiva de um algoritmo de floresta aleatória. Os modelos de árvore de decisão superajustam os dados, daí a necessidade de Random Forest. Os modelos de árvore de decisão podem ser de baixo viés, mas são principalmente de alta variância. Portanto, para reduzir esse erro de variância no conjunto de teste, o Random Forest é usado.

Hiperparâmetros
Existem vários hiperparâmetros que podem ser controlados em uma floresta aleatória:
- N_estimators: O número de árvores de decisão sendo construídas na floresta. Os valores padrão no sklearn são 100. N_estimators são principalmente correlacionados ao tamanho dos dados, para encapsular as tendências nos dados, mais número de DTs são necessários.
- Critério: A função que é usada para medir a qualidade das divisões em uma árvore de decisão (Problema de Classificação). Os critérios suportados são gini: impureza gini ou entropia: ganho de informação. No caso de Regressão Erro Médio Absoluto (MAE) ou Erro Médio Quadrado (MSE) pode ser usado. O padrão é gini e mse.
- Max_depth: Os níveis máximos permitidos em uma árvore de decisão. Se definido como nada, a árvore de decisão continuará se dividindo até que a pureza seja alcançada.
- Max_features: Número máximo de recursos usados para um processo de divisão de nós. Tipos: sqrt, log2. Se o total de feições são n_features então: sqrt(n_features) ou log2(n_features) podem ser selecionados como feições máximas para divisão de nós.
- Bootstrap: Amostras de bootstrap são usadas ao construir árvores de decisão se True for selecionado no bootstrap, caso contrário, dados inteiros são usados para cada árvore de decisão.
- Min_samples_split: Este parâmetro decide o número mínimo de amostras necessárias para dividir um nó interno. Valor padrão =2. O problema com um valor tão pequeno é que a condição é verificada no nó terminal. Se os pontos de dados no nó excederem o valor 2, ocorrerá uma divisão adicional. Considerando que, se um valor mais brando como 6 for definido, a divisão será interrompida mais cedo e a árvore de decisão não se ajustará aos dados.
- Min_sample_leaf: Este parâmetro define o número mínimo de requisitos de ponto de dados em um nó da árvore de decisão. Afeta o nó terminal e basicamente ajuda a controlar a profundidade da árvore. Se, após uma divisão, os pontos de dados em um nó ficarem abaixo do número min_sample_leaf, a divisão não passará e será interrompida no nó pai.
Existem outros parâmetros menos importantes que também podem ser considerados durante o processo de ajuste de hiperparâmetros.
n_jobs: número de processadores que podem ser usados para treinamento. (-1 sem limite)
max_samples: os dados máximos que podem ser usados em cada Árvore de Decisão
random_state: o modelo com um random_state específico produzirá precisão/saídas semelhantes.
Class_weight: entrada de dicionário, que pode lidar com conjuntos de dados desequilibrados.
Deve ler: Tipos de algoritmo de IA
Processos de ajuste de hiperparâmetros
Existem várias maneiras de realizar processos de ajuste de hiperparâmetros. Após a criação e avaliação do modelo base, os hiperparâmetros podem ser ajustados para aumentar algumas métricas específicas, como precisão ou pontuação f1 do modelo.
Deve-se verificar os erros de overfitting e de variância de viés antes e depois dos ajustes. O modelo deve ser ajustado de acordo com o requisito de tempo real. Às vezes, um modelo de overfitting pode ser muito sensível à flutuação de dados na validação, portanto, as pontuações de validação cruzada com o desvio de validação cruzada devem ser verificadas para possível overfit antes e depois do ajuste do modelo.

Os métodos para o ajuste da Random Forest em python são abordados a seguir.
Currículo de pesquisa aleatória
Podemos usar scikit learn e RandomisedSearchCV onde podemos definir a grade, o modelo de floresta aleatória será ajustado repetidamente selecionando parâmetros aleatoriamente da grade. Não obteremos os melhores parâmetros, mas definitivamente obteremos o melhor modelo dos diferentes modelos que estão sendo montados e testados.
Código fonte:
de sklearn.model_selection importar GridSearchCV
# Crie uma grade de pesquisa de parâmetros que serão embaralhadas
param_grid = {
'bootstrap': [Verdadeiro],
'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, Nenhum],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimadores': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# Usando a grade aleatória e procurando os melhores hiperparâmetros
rf = RandomForestRegressor() #criando modelo base
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 5, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit é para iniciar o processo de treinamento
A função de pesquisa aleatória pesquisará os parâmetros por meio de validação cruzada de 5 vezes e 100 iterações para obter os melhores parâmetros.
Currículo de pesquisa de grade
A pesquisa em grade é usada após a pesquisa aleatória para restringir o intervalo para pesquisar os hiperparâmetros perfeitos. Agora que sabemos onde podemos nos concentrar, podemos executar explicitamente esses parâmetros por meio de pesquisa de grade e avaliar diferentes modelos para obter os valores finais para cada hiperparâmetro.
Código fonte:
de sklearn.model_selection importar GridSearchCV
# Cria a grade de parâmetros com base nos resultados da pesquisa aleatória
param_grid = {
'bootstrap': [Verdadeiro],
'max_depth': [80, 90, 100, 110],
'max_features': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimadores': [100, 200, 300, 1000]
}
# Cria um modelo baseado
rf = RandomForestRegressor()
# Instancia o modelo de pesquisa de grade
grid_search = GridSearchCV(estimador = rf, param_grid = param_grid,
cv = 3, n_jobs = -1, detalhado = 2)
Resultados após a execução:
# Ajusta a pesquisa da grade aos dados
grid_search.fit(train_features, train_labels)
grid_search.best_params_
{'bootstrap': Verdade,
'max_profundidade': 80,
'max_features': 3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_estimadores': 100}
best_grid = grid_search.best_estimator_
Leia também: Ideias de projetos de aprendizado de máquina
Conclusão
Passamos pelo trabalho de um modelo de floresta aleatória e como cada hiperparâmetro funciona para alterar as árvores de decisão e, portanto, o modelo de floresta aleatória como um todo. Também analisamos a técnica eficiente de combinar o uso de pesquisa aleatória e de grade para obter os melhores parâmetros para nosso modelo. O ajuste de hiperparâmetros é muito importante, pois nos ajuda a controlar o desempenho de viés e variância do nosso modelo.
Se você estiver interessado em aprender mais sobre a árvore de decisão, Aprendizado de Máquina, confira o Diploma PG do IIIT-B e do upGrad em Aprendizado de Máquina e IA, projetado para profissionais que trabalham e oferece mais de 450 horas de treinamento rigoroso, mais de 30 estudos de caso e atribuições, status de ex-alunos do IIIT-B, mais de 5 projetos práticos práticos e assistência de trabalho com as principais empresas.
Quais hiperparâmetros podem ser ajustados na floresta aleatória?
Na floresta aleatória, os hiperparâmetros são o número de árvores, o número de feições e o tipo de árvores (como GBM ou M5). O número de recursos é importante e deve ser ajustado. Nesse caso, a floresta aleatória é útil porque ajusta automaticamente o número de recursos. O número de árvores e o tipo de árvores não são tão importantes, mas nunca se deve usar mais de 500 árvores porque é uma perda de tempo. De um modo geral, o tipo de árvores e o número de árvores são ajustados de acordo com os dados.
Como você otimiza um modelo Random Forest?
Para ter sucesso, os dois principais componentes do algoritmo Random Forest (e outras variantes da árvore de decisão) são a seleção de recursos e a estrutura da árvore. Em relação à estrutura da árvore, você terá que experimentar o número de árvores e recursos usados em cada árvore. Mais importante, você precisa encontrar o ponto ideal onde seu modelo seja preciso o suficiente e não se ajuste demais.
O que é Random Forest no aprendizado de máquina?
Florestas aleatórias são um conjunto de árvores de decisão. São modelos poderosos e flexíveis que podem ser usados de muitas maneiras diferentes. Na verdade, as florestas aleatórias tornaram-se muito populares na última década. O modelo é usado em muitos campos diferentes (biologia, marketing, finanças, mineração de texto etc.). Ele tem sido usado em grandes competições e produziu resultados de última geração. O uso mais comum de florestas aleatórias é classificar (ou rotular) dados. Mas, eles também podem ser usados para regredir valores contínuos (estimar um valor) e agrupar pontos de dados semelhantes.