
Penyetelan Hyperparameter Hutan Acak: Proses yang Dijelaskan dengan Pengkodean
Diterbitkan: 2020-12-23Random Forest adalah algoritma Machine Learning yang menggunakan pohon keputusan sebagai dasarnya. Random Forest mudah digunakan dan merupakan algoritma ML yang fleksibel. Karena kesederhanaan dan keragamannya, ini digunakan sangat luas. Ini memberikan hasil yang baik pada banyak tugas klasifikasi, bahkan tanpa banyak penyetelan hyperparameter.
Pada artikel ini, kami akan fokus pada kerja Random Forest dan parameter hyper yang berbeda yang dapat dikontrol untuk hasil yang optimal. Kebutuhan akan penyetelan Hyperparameter muncul karena setiap data memiliki karakteristiknya masing-masing.
Karakteristik ini dapat berupa jenis variabel, ukuran data, variabel target biner/multiclass, jumlah kategori dalam variabel kategori, standar deviasi data numerik, normalitas dalam data, dll. Oleh karena itu, penyetelan model sesuai dengan data sangat penting untuk memaksimalkan kinerja model.
Daftar isi
Membangun dan Bekerja
Algoritma Hutan Acak berfungsi sebagai kumpulan besar pohon keputusan yang berhubungan dengan dekorasi. Ini juga dikenal sebagai teknik mengantongi. Bagging termasuk dalam kategori ensemble learning dan didasarkan pada teori bahwa kombinasi model yang berisik dan tidak bias dapat dirata-ratakan untuk membuat model dengan varians yang rendah. Mari kita memahami bagaimana Hutan Acak dibangun.
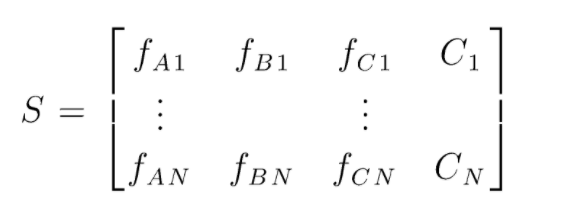
S adalah matriks data yang ada untuk melakukan klasifikasi hutan secara acak. Ada N instance yang ada dan A,B,C adalah fitur dari data. Dari data ini, subset data acak dibuat. Di mana pohon keputusan dibuat. Seperti yang dapat kita lihat dari gambar di bawah, satu pohon keputusan dibuat per subset data, dan tergantung pada ukuran data, pohon keputusan juga bertambah.
Keluaran dari semua pohon keputusan yang dilatih dipilih dan kelas yang dipilih mayoritas adalah keluaran efektif dari Algoritma Hutan Acak. Model pohon keputusan overfit data maka kebutuhan untuk Random Forest muncul. Model pohon keputusan mungkin Bias Rendah tetapi sebagian besar variansnya tinggi. Oleh karena itu untuk mengurangi kesalahan varians ini pada set tes, digunakan Random Forest.

Hyperparameter
Ada berbagai hyperparameter yang dapat dikontrol di hutan acak:
- N_estimators: Jumlah pohon keputusan yang dibangun di hutan. Nilai default dalam sklearn adalah 100. N_estimator sebagian besar berkorelasi dengan ukuran data, untuk merangkum tren dalam data, diperlukan lebih banyak jumlah DT.
- Kriteria: Fungsi yang digunakan untuk mengukur kualitas pemisahan dalam pohon keputusan (Masalah Klasifikasi). Kriteria yang didukung adalah gini: gini impurity or entropy: information gain. Dalam kasus Regression Mean Absolute Error (MAE) atau Mean Squared Error (MSE) dapat digunakan. Defaultnya gini dan mse.
- Max_depth: Level maksimum yang diizinkan dalam pohon keputusan. Jika disetel ke nol, Pohon keputusan akan terus membelah sampai kemurnian tercapai.
- Max_features: Jumlah maksimum fitur yang digunakan untuk proses pemisahan simpul. Jenis: sqrt, log2. Jika total fitur adalah n_features maka: sqrt(n_features) atau log2(n_features) dapat dipilih sebagai fitur maksimal untuk pemisahan node.
- Bootstrap: Sampel bootstrap digunakan saat membangun pohon keputusan jika True dipilih dalam bootstrap, jika tidak seluruh data digunakan untuk setiap pohon keputusan.
- Min_samples_split: Parameter ini menentukan jumlah minimum sampel yang diperlukan untuk membagi node internal. Nilai bawaan =2. Masalah dengan nilai sekecil itu adalah bahwa kondisinya diperiksa pada simpul terminal. Jika titik data dalam node melebihi nilai 2, maka pemisahan lebih lanjut terjadi. Sedangkan jika nilai yang lebih lunak seperti 6 ditetapkan, maka pemisahan akan berhenti lebih awal dan pohon keputusan tidak akan overfit pada data.
- Min_sample_leaf: Parameter ini menetapkan jumlah minimum persyaratan titik data dalam simpul pohon keputusan. Ini mempengaruhi simpul terminal dan pada dasarnya membantu dalam mengontrol kedalaman pohon. Jika setelah pemisahan titik data dalam sebuah simpul berada di bawah nomor min_sample_leaf, pemisahan tidak akan melalui dan akan dihentikan pada simpul induk.
Ada parameter lain yang kurang penting yang juga dapat dipertimbangkan selama proses penyetelan hyperparameter.
n_jobs: jumlah prosesor yang dapat digunakan untuk pelatihan. (-1 tanpa batas)
max_samples: data maksimum yang dapat digunakan di setiap Pohon Keputusan
random_state: model dengan random_state tertentu akan menghasilkan akurasi/output yang serupa.
Class_weight: input kamus, yang dapat menangani kumpulan data yang tidak seimbang.
Wajib Dibaca: Jenis-Jenis Algoritme AI
Proses Penyetelan Hyperparameter
Ada berbagai cara untuk melakukan proses penyetelan hyperparameter. Setelah model dasar dibuat dan dievaluasi, hyperparameter dapat disetel untuk meningkatkan beberapa metrik tertentu seperti akurasi atau skor f1 model.
Seseorang harus memeriksa kesalahan overfitting dan varians bias sebelum dan sesudah penyesuaian. Model harus disetel sesuai dengan kebutuhan waktu nyata. Terkadang model overfitting mungkin sangat sensitif terhadap fluktuasi data dalam validasi, oleh karena itu skor validasi silang dengan deviasi validasi silang harus diperiksa untuk kemungkinan overfit sebelum dan sesudah penyetelan model.

Metode untuk penyetelan Hutan Acak pada python dibahas selanjutnya.
Pencarian Acak CV
Kita dapat menggunakan scikit learn dan RandomisedSearchCV di mana kita dapat menentukan grid, model hutan acak akan dipasang berulang-ulang dengan memilih parameter secara acak dari grid. Kami tidak akan mendapatkan parameter terbaik, tetapi kami pasti akan mendapatkan model terbaik dari berbagai model yang dipasang dan diuji.
Kode sumber:
dari sklearn.model_selection impor GridSearchCV
# Buat kotak pencarian parameter yang akan diacak
param_grid = {
'bootstrap': [Benar],
'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, Tidak Ada],
'max_features': ['otomatis', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimator': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# Menggunakan kisi acak dan mencari hyperparameter terbaik
rf = RandomForestRegressor() #membuat model dasar
rf_random = RandomizedSearchCV(estimator = rf, param_distribution = random_grid, n_iter = 100, cv = 5, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit adalah untuk memulai proses pelatihan
Fungsi pencarian acak akan mencari parameter melalui validasi silang 5 kali lipat dan 100 iterasi untuk mendapatkan parameter terbaik.
CV Pencarian Kotak
Pencarian grid digunakan setelah pencarian acak untuk mempersempit rentang untuk mencari hyperparameter yang sempurna. Sekarang kita tahu di mana kita dapat fokus, kita dapat secara eksplisit menjalankan parameter tersebut melalui pencarian grid dan mengevaluasi model yang berbeda untuk mendapatkan nilai akhir untuk setiap hyperparameter.
Kode sumber:
dari sklearn.model_selection impor GridSearchCV
# Buat kisi parameter berdasarkan hasil pencarian acak
param_grid = {
'bootstrap': [Benar],
'max_depth': [80, 90, 100, 110],
'max_features': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimator': [100, 200, 300, 1000]
}
# Buat model berbasis
rf = RandomForestRegressor()
# Buat contoh model pencarian grid
grid_search = GridSearchCV(estimator = rf, param_grid = param_grid,
cv = 3, n_pekerjaan = -1, verbose = 2)
Hasil setelah eksekusi:
# Sesuaikan pencarian grid dengan data
grid_search.fit(train_features, train_labels)
grid_search.best_params_
{'bootstrap': Benar,
'max_depth': 80,
'max_features': 3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_estimator': 100}
best_grid = grid_search.best_estimator_
Baca Juga: Ide Proyek Pembelajaran Mesin
Kesimpulan
Kami membahas cara kerja model hutan acak dan bagaimana setiap hyperparameter bekerja untuk mengubah pohon keputusan dan karenanya model hutan acak secara keseluruhan. Kami juga telah melihat teknik yang efisien untuk menggabungkan penggunaan pencarian acak dan grid untuk mendapatkan parameter terbaik untuk model kami. Penyetelan hyperparameter sangat penting karena membantu kami mengontrol kinerja bias dan varians model kami.
Jika Anda tertarik untuk mempelajari lebih lanjut tentang pohon keputusan, Pembelajaran Mesin, lihat PG Diploma IIIT-B & upGrad dalam Pembelajaran Mesin & AI yang dirancang untuk profesional yang bekerja dan menawarkan 450+ jam pelatihan ketat, 30+ studi kasus & tugas, status Alumni IIIT-B, 5+ proyek batu penjuru praktis & bantuan pekerjaan dengan perusahaan-perusahaan top.
Hyperparameter mana yang dapat disetel di hutan acak?
Di hutan acak, hyperparameter adalah jumlah pohon, jumlah fitur dan jenis pohon (seperti GBM atau M5). Jumlah fitur penting dan harus disetel. Dalam hal ini, hutan acak berguna karena secara otomatis menyetel jumlah fitur. Jumlah pohon dan jenis pohon tidak begitu penting, tetapi jangan pernah menggunakan lebih dari 500 pohon karena membuang-buang waktu. Secara umum, jenis pohon dan jumlah pohon disetel sesuai dengan data.
Bagaimana Anda mengoptimalkan model Hutan Acak?
Agar berhasil, dua komponen utama dari algoritma Random Forest (dan varian pohon keputusan lainnya) adalah pemilihan fitur dan struktur pohon. Mengenai struktur pohon, Anda harus bereksperimen dengan jumlah pohon dan fitur yang digunakan di setiap pohon. Yang terpenting, Anda perlu menemukan sweet spot di mana model Anda cukup akurat dan tidak terlalu pas.
Apa itu Hutan Acak dalam pembelajaran mesin?
Hutan acak adalah kumpulan pohon keputusan. Mereka adalah model yang kuat dan fleksibel yang dapat digunakan dalam berbagai cara. Faktanya, hutan acak telah menjadi sangat populer selama dekade terakhir. Model ini digunakan di berbagai bidang (biologi, pemasaran, keuangan, penambangan teks, dll.). Ini telah digunakan dalam kompetisi besar dan telah menghasilkan hasil yang canggih. Penggunaan paling umum dari hutan acak adalah untuk mengklasifikasikan (atau memberi label) data. Namun, mereka juga dapat digunakan untuk meregresi nilai kontinu (memperkirakan nilai) dan mengelompokkan titik data yang serupa.