
Настройка гиперпараметров случайного леса: процессы, объясняемые кодированием
Опубликовано: 2020-12-23Случайный лес — это алгоритм машинного обучения, в основе которого лежат деревья решений. Random Forest прост в использовании и имеет гибкий алгоритм машинного обучения. Благодаря своей простоте и разнообразию он используется очень широко. Это дает хорошие результаты во многих задачах классификации даже без особой настройки гиперпараметров.
В этой статье мы сосредоточимся на работе Random Forest и различных гиперпараметрах, которыми можно управлять для достижения оптимальных результатов. Необходимость в настройке гиперпараметров возникает потому, что каждые данные имеют свои характеристики.
Этими характеристиками могут быть типы переменных, размер данных, бинарная/мультиклассовая целевая переменная, количество категорий в категориальных переменных, стандартное отклонение числовых данных, нормальность данных и т. д. Следовательно, настройка модели в соответствии с данными обязательна для максимизация производительности модели.
Оглавление
Строительство и работа
Алгоритм случайного леса работает как большая коллекция декоррелированных деревьев решений. Это также известно как техника мешков. Бэггинг относится к категории ансамблевого обучения и основан на теории о том, что комбинация зашумленных и несмещенных моделей может быть усреднена для создания модели с низкой дисперсией. Давайте разберемся, как строится случайный лес.
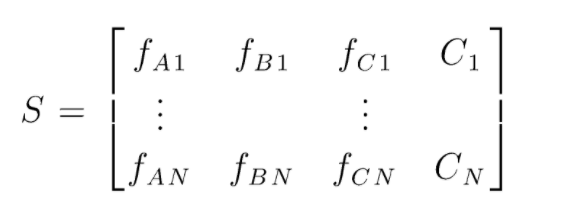
S представляет собой матрицу данных, представленных для выполнения случайной классификации леса. Имеется N экземпляров, а A, B, C являются признаками данных. Из этих данных создаются случайные подмножества данных. Над которыми создаются деревья решений. Как мы видим из рисунка ниже, для каждого подмножества данных создается одно дерево решений, и в зависимости от размера данных деревья решений также увеличиваются.
Результат всех обученных деревьев решений голосуется, а класс с большинством голосов является эффективным выходом алгоритма случайного леса. Модели деревьев решений соответствуют данным, поэтому возникает необходимость в Random Forest. Модели дерева решений могут быть с низким смещением, но в основном они имеют высокую дисперсию. Следовательно, чтобы уменьшить эту ошибку дисперсии в тестовом наборе, используется случайный лес.

Гиперпараметры
Существуют различные гиперпараметры, которыми можно управлять в случайном лесу:
- N_estimators: количество деревьев решений, построенных в лесу. Значения по умолчанию в sklearn — 100. N_estimators в основном коррелируют с размером данных, чтобы инкапсулировать тенденции в данных, требуется большее количество DT.
- Критерий: функция, которая используется для измерения качества расщеплений в дереве решений (проблема классификации). Поддерживаемые критерии: Джини: примесь Джини или энтропия: прирост информации. В случае регрессии можно использовать среднюю абсолютную ошибку (MAE) или среднеквадратичную ошибку (MSE). По умолчанию это джини и mse.
- Max_depth: максимальные уровни, разрешенные в дереве решений. Если не установлено ничего, дерево решений будет продолжать разбиваться до тех пор, пока не будет достигнута чистота.
- Max_features: максимальное количество функций, используемых для процесса разделения узла. Типы: sqrt, log2. Если общее количество признаков равно n_features, то: sqrt(n_features) или log2(n_features) могут быть выбраны в качестве максимальных признаков для разделения узлов.
- Bootstrap: примеры Bootstrap используются при построении деревьев решений, если в начальной загрузке выбрано значение True, в противном случае для каждого дерева решений используются целые данные.
- Min_samples_split: этот параметр определяет минимальное количество выборок, необходимых для разделения внутреннего узла. Значение по умолчанию =2. Проблема с таким маленьким значением в том, что условие проверяется на конечном узле. Если точки данных в узле превышают значение 2, происходит дальнейшее разделение. Принимая во внимание, что если установлено более мягкое значение, такое как 6, то разделение остановится раньше, и дерево решений не будет соответствовать данным.
- Min_sample_leaf: этот параметр устанавливает минимальное количество требований к точкам данных в узле дерева решений. Он влияет на конечный узел и в основном помогает контролировать глубину дерева. Если после разделения точки данных в узле переходят под номером min_sample_leaf, разделение не будет выполнено и будет остановлено на родительском узле.
Существуют и другие менее важные параметры, которые также можно учитывать в процессе настройки гиперпараметров.
n_jobs: количество процессоров, которые можно использовать для обучения. (-1 без ограничений)
max_samples: максимальное количество данных, которые можно использовать в каждом дереве решений.
random_state: модель с определенным random_state будет давать аналогичную точность/результаты.
Class_weight: ввод словаря, который может обрабатывать несбалансированные наборы данных.
Обязательно к прочтению: Типы алгоритмов ИИ
Процессы настройки гиперпараметров
Существуют различные способы выполнения процессов настройки гиперпараметров. После создания и оценки базовой модели можно настроить гиперпараметры для повышения некоторых конкретных показателей, таких как точность или показатель f1 модели.

Необходимо проверить ошибки переобучения и дисперсии смещения до и после корректировок. Модель должна быть настроена в соответствии с требованиями реального времени. Иногда модель переобучения может быть очень чувствительна к колебаниям данных при проверке, поэтому следует проверять оценки перекрестной проверки с отклонением перекрестной проверки на возможное переобучение до и после настройки модели.
Далее рассматриваются методы настройки Random Forest на Python.
Рандомизированный поиск резюме
Мы можем использовать scikit Learn и RandomisedSearchCV, где мы можем определить сетку, модель случайного леса будет подбираться снова и снова путем случайного выбора параметров из сетки. Мы не получим лучшие параметры, но мы обязательно получим лучшую модель из разных моделей, которые устанавливаются и тестируются.
Исходный код:
из sklearn.model_selection импортировать GridSearchCV
# Создаем поисковую сетку параметров, которые будут перемешиваться
param_grid = {
'начальная загрузка': [Верно],
'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, Нет],
'max_features': ['авто', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimators': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# Использование случайной сетки и поиск лучших гиперпараметров
rf = RandomForestRegressor() #создание базовой модели
rf_random = RandomizedSearchCV (оценщик = rf, param_distributions = random_grid, n_iter = 100, cv = 5, verbose = 2, random_state = 42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit должен инициировать процесс обучения
Функция рандомизированного поиска будет искать параметры через 5-кратную перекрестную проверку и 100 итераций, чтобы получить наилучшие параметры.
Резюме поиска по сетке
Поиск по сетке используется после рандомизированного поиска, чтобы сузить диапазон для поиска идеальных гиперпараметров. Теперь, когда мы знаем, на чем мы можем сосредоточиться, мы можем явно запустить эти параметры через поиск по сетке и оценить различные модели, чтобы получить окончательные значения для каждого гиперпараметра.
Исходный код:
из sklearn.model_selection импортировать GridSearchCV
# Создаем сетку параметров по результатам случайного поиска
param_grid = {
'начальная загрузка': [Верно],
'макс_глубина': [80, 90, 100, 110],
'max_features': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimators': [100, 200, 300, 1000]
}
# Создаем базовую модель
rf = RandomForestRegressor()
# Создаем модель поиска по сетке
grid_search = GridSearchCV (оценщик = rf, param_grid = param_grid,
cv = 3, n_jobs = -1, подробный = 2)
Результаты после выполнения:
# Подогнать поиск по сетке к данным
grid_search.fit (train_features, train_labels)
grid_search.best_params_
{'бутстрап': правда,
'максимальная_глубина': 80,
'max_features': 3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_оценщиков': 100}
best_grid = grid_search.best_estimator_
Читайте также: Идеи проекта машинного обучения
Заключение
Мы рассмотрели работу модели случайного леса и то, как работает каждый гиперпараметр для изменения деревьев решений и, следовательно, модели случайного леса в целом. Мы также рассмотрели эффективный метод сочетания использования рандомизированного поиска и поиска по сетке, чтобы получить наилучшие параметры для нашей модели. Настройка гиперпараметров очень важна, поскольку она помогает нам контролировать смещение и дисперсию нашей модели.
Если вам интересно узнать больше о дереве решений, машинном обучении, ознакомьтесь с дипломом PG IIIT-B и upGrad в области машинного обучения и искусственного интеллекта, который предназначен для работающих профессионалов и предлагает более 450 часов тщательного обучения, более 30 тематических исследований и задания, статус выпускника IIIT-B, более 5 практических практических проектов и помощь в трудоустройстве в ведущих фирмах.
Какие гиперпараметры можно настроить в случайном лесу?
В случайном лесу гиперпараметрами являются количество деревьев, количество признаков и тип деревьев (например, GBM или M5). Количество функций важно и должно быть настроено. В этом случае случайный лес полезен, потому что он автоматически настраивает количество признаков. Количество деревьев и тип деревьев не так важны, но никогда не следует использовать более 500 деревьев, потому что это пустая трата времени. Вообще говоря, тип деревьев и количество деревьев настраиваются в соответствии с данными.
Как оптимизировать модель случайного леса?
Чтобы быть успешным, двумя основными компонентами алгоритма случайного леса (и других вариантов дерева решений) являются выбор функций и древовидная структура. Что касается древовидной структуры, вам придется поэкспериментировать с количеством деревьев и функциями, используемыми в каждом дереве. Самое главное, вам нужно найти ту золотую середину, в которой ваша модель достаточно точна и не дает переобучения.
Что такое случайный лес в машинном обучении?
Случайные леса представляют собой ансамбль деревьев решений. Это мощные и гибкие модели, которые можно использовать по-разному. Фактически, случайные леса стали очень популярными за последнее десятилетие. Модель используется во многих различных областях (биология, маркетинг, финансы, анализ текста и т. д.). Он использовался на крупных соревнованиях и дал самые современные результаты. Чаще всего случайные леса используются для классификации (или маркировки) данных. Но их также можно использовать для регрессии непрерывных значений (оценки значения) и группирования похожих точек данных.