
Rastgele Orman Hiperparametre Ayarı: Kodlama ile Açıklanan İşlemler
Yayınlanan: 2020-12-23Random Forest, temel olarak karar ağaçlarını kullanan bir Makine Öğrenimi algoritmasıdır. Random Forest, kullanımı kolay ve esnek bir ML algoritmasıdır. Sadeliği ve çeşitliliği nedeniyle çok yaygın olarak kullanılmaktadır. Çok fazla hiperparametre ayarı olmadan bile birçok sınıflandırma görevinde iyi sonuçlar verir.
Bu yazıda, Random Forest'ın çalışmasına ve optimal sonuçlar için kontrol edilebilecek farklı hiper parametrelere odaklanacağız. Her verinin kendine has özellikleri olduğu için Hiperparametre ayarlama ihtiyacı ortaya çıkar.
Bu özellikler değişken türleri, veri boyutu, ikili/çok sınıflı hedef değişken, kategorik değişkenlerdeki kategori sayısı, sayısal verilerin standart sapması, verilerdeki normallik vb. olabilir. Bu nedenle, modelin verilere göre ayarlanması zorunludur. Bir modelin performansını en üst düzeye çıkarmak.
İçindekiler
İnşaat ve Çalışma
Rastgele Orman Algoritması, ilişkisiz karar ağaçlarının geniş bir koleksiyonu olarak çalışır. Torbalama tekniği olarak da bilinir. Torbalama, topluluk öğrenimi kategorisine girer ve düşük varyanslı bir model oluşturmak için gürültülü ve yansız modellerin kombinasyonunun ortalamasının alınabileceği teorisine dayanır. Rastgele Ormanın nasıl inşa edildiğini anlayalım.
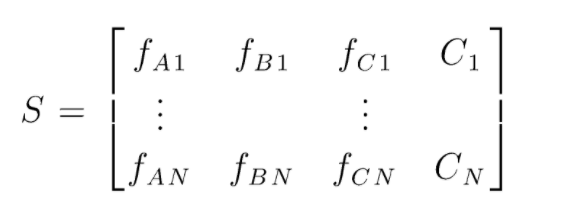
S, rastgele orman sınıflandırması gerçekleştirmek için mevcut veri matrisidir. Mevcut N tane örnek vardır ve A,B,C verilerin özellikleridir. Bu verilerden rastgele veri alt kümeleri oluşturulur. Hangi karar ağaçlarının üzerinde oluşturulur. Aşağıdaki şekilde de görebileceğimiz gibi, her veri alt kümesi için bir karar ağacı oluşturulmakta ve verinin boyutuna bağlı olarak karar ağaçları da artırılmaktadır.
Tüm eğitilmiş karar ağaçlarının çıktısı oylanır ve çoğunluk oyu alan sınıf, Rastgele Orman Algoritmasının etkin çıktısıdır. Karar ağacı modelleri verilere fazla uyuyor ve bu nedenle Rastgele Orman ihtiyacı ortaya çıkıyor. Karar ağacı modelleri Düşük Sapma olabilir, ancak çoğunlukla yüksek varyanslıdır. Bu nedenle, test setindeki bu varyans hatasını azaltmak için Rastgele Orman kullanılmıştır.

hiperparametreler
Rastgele bir ormanda kontrol edilebilecek çeşitli hiperparametreler vardır:
- N_estimators: Ormanda inşa edilen karar ağaçlarının sayısı. Sklearn'deki varsayılan değerler 100'dür. N_tahminciler çoğunlukla verilerin boyutuyla ilişkilidir, verilerdeki eğilimleri kapsüllemek için daha fazla sayıda DT gerekir.
- Kriter: Bir karar ağacındaki bölünmelerin kalitesini ölçmek için kullanılan fonksiyon (Sınıflandırma Problemi). Desteklenen kriterler şunlardır: gini: gini safsızlığı veya entropi: bilgi kazancı. Regresyon durumunda Ortalama Mutlak Hata (MAE) veya Ortalama Kare Hata (MSE) kullanılabilir. Varsayılan, gini ve mse'dir.
- Max_depth: Bir karar ağacında izin verilen maksimum seviyeler. Hiçbir şeye ayarlanmazsa, karar ağacı saflığa ulaşılana kadar bölünmeye devam edecektir.
- Max_features: Bir düğüm bölme işlemi için kullanılan maksimum özellik sayısı. Türler: sqrt, log2. Toplam özellikler n_features ise: sqrt(n_features) veya log2(n_features) düğüm bölme için maksimum özellikler olarak seçilebilir.
- Bootstrap: Bootstrap'ta True seçilirse karar ağaçları oluşturulurken Bootstrap örnekleri kullanılır, aksi takdirde her karar ağacı için tüm veriler kullanılır.
- Min_samples_split: Bu parametre, bir dahili düğümü bölmek için gereken minimum örnek sayısına karar verir. Varsayılan değer =2. Böyle küçük bir değerle ilgili sorun, koşulun terminal düğümünde kontrol edilmesidir. Düğümdeki veri noktaları 2 değerini aşarsa, daha fazla bölme gerçekleşir. Oysa 6 gibi daha esnek bir değer ayarlanırsa, bölme erken durur ve karar ağacı verilere fazla sığmaz.
- Min_sample_leaf: Bu parametre, karar ağacının bir düğümündeki minimum veri noktası gereksinimi sayısını ayarlar. Terminal düğümünü etkiler ve temel olarak ağacın derinliğini kontrol etmeye yardımcı olur. Bölme işleminden sonra bir düğümdeki veri noktaları min_sample_leaf sayısının altına düşerse, bölme gerçekleşmez ve üst düğümde durdurulur.
Hiperparametre ayarlama işlemi sırasında dikkate alınabilecek daha az önemli başka parametreler de vardır.
n_jobs: eğitim için kullanılabilecek işlemci sayısı. (sınırsız -1)
max_samples: Her Karar Ağacında kullanılabilecek maksimum veri
rastgele_durum: belirli bir rastgele_durumlu model benzer doğruluk/çıktılar üretecektir.
Class_weight: dengesiz veri kümelerini işleyebilen sözlük girişi.
Okumalısınız: AI Algoritması Türleri
Hiperparametre Ayar İşlemleri
Hiperparametre ayarlama işlemlerini gerçekleştirmenin çeşitli yolları vardır. Temel model oluşturulup değerlendirildikten sonra, modelin doğruluğu veya f1 puanı gibi bazı belirli metrikleri artırmak için hiperparametreler ayarlanabilir.
Ayarlamalardan önce ve sonra aşırı uyum ve önyargı varyansı hataları kontrol edilmelidir. Model, gerçek zaman gereksinimine göre ayarlanmalıdır. Bazen fazla uydurma bir model, doğrulamadaki veri dalgalanmasına karşı çok hassas olabilir, bu nedenle çapraz doğrulama sapması ile çapraz doğrulama puanları, model ayarından önce ve sonra olası fazla uyum için kontrol edilmelidir.

Python'da Rastgele Orman ayarlama yöntemleri daha sonra ele alınacaktır.
Rastgele Arama Özgeçmişi
Izgarayı tanımlayabileceğimiz scikit öğrenme ve RandomisedSearchCV kullanabiliriz, ızgaradan rastgele parametreler seçerek rastgele orman modeli tekrar tekrar takılacaktır. En iyi parametreleri alamayacağız, ancak takılan ve test edilen farklı modellerden kesinlikle en iyi modeli alacağız.
Kaynak kodu:
sklearn.model_selection'dan GridSearchCV'yi içe aktarın
# Karıştırılacak bir parametre arama ızgarası oluşturun
param_grid = {
'önyükleme': [Doğru],
'max_depth': [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, Yok],
'max_features': ['auto', 'sqrt'],
'min_samples_leaf': [1, 2, 4],
'min_samples_split': [2, 5, 10],
'n_estimators': [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# Rastgele ızgarayı kullanma ve en iyi hiperparametreleri arama
rf = RandomForestRegressor() #temel model oluşturma
rf_random = RandomizedSearchCV(tahminleyici = rf, param_distributions = random_grid, n_iter = 100, cv = 5, ayrıntılı=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit, eğitim sürecini başlatmaktır
Rastgele arama işlevi, en iyi parametreleri elde etmek için 5 kat çapraz doğrulama ve 100 yineleme yoluyla parametreleri arayacaktır.
Izgara Arama Özgeçmişi
Izgara araması, mükemmel hiperparametreleri aramak için aralığı daraltmak için rastgele aramadan sonra kullanılır. Artık nereye odaklanabileceğimizi bildiğimize göre, bu parametreleri ızgara arama yoluyla açıkça çalıştırabilir ve her hiperparametre için nihai değerleri elde etmek için farklı modelleri değerlendirebiliriz.
Kaynak kodu:
sklearn.model_selection'dan GridSearchCV'yi içe aktarın
# Rastgele aramanın sonuçlarına göre parametre ızgarasını oluşturun
param_grid = {
'önyükleme': [Doğru],
'max_depth': [80, 90, 100, 110],
'max_features': [2, 3],
'min_samples_leaf': [3, 4, 5],
'min_samples_split': [8, 10, 12],
'n_estimators': [100, 200, 300, 1000]
}
# Tabanlı bir model oluşturun
rf = RandomForestRegressor()
# Izgara arama modelini somutlaştırın
grid_search = GridSearchCV(tahmini = rf, param_grid = param_grid,
cv = 3, n_jobs = -1, ayrıntılı = 2)
Yürütmeden sonraki sonuçlar:
# Izgara aramasını verilere sığdır
grid_search.fit(train_features, train_labels)
grid_search.best_params_
{'bootstrap': Doğru,
'maks_derinlik': 80,
'max_features': 3,
'min_samples_leaf': 5,
'min_samples_split': 12,
'n_tahminciler': 100}
best_grid = grid_search.best_estimator_
Ayrıca Okuyun: Makine Öğrenimi Proje Fikirleri
Çözüm
Rastgele bir orman modelinin çalışmasını ve her bir hiperparametrenin karar ağaçlarını ve dolayısıyla bir bütün olarak rastgele orman modelini değiştirmek için nasıl çalıştığını inceledik. Ayrıca, modelimiz için en iyi parametrelere ulaşmak için rasgele ve ızgara aramanın kullanımını birleştirmeye yönelik etkili tekniğe de baktık. Hiperparametre ayarı, modelimizin sapma ve varyans performansını kontrol etmemize yardımcı olduğu için çok önemlidir.
Karar ağacı, Makine Öğrenimi hakkında daha fazla bilgi edinmek istiyorsanız, IIIT-B & upGrad'ın çalışan profesyoneller için tasarlanmış ve 450+ saatlik zorlu eğitim, 30'dan fazla vaka çalışması ve Makine Öğrenimi ve Yapay Zeka alanında PG Diplomasına göz atın. atamalar, IIIT-B Mezun statüsü, 5+ pratik uygulamalı bitirme projesi ve en iyi firmalarla iş yardımı.
Rastgele ormanda hangi hiperparametreler ayarlanabilir?
Rastgele ormanda, hiperparametreler ağaç sayısı, özellik sayısı ve ağaç türüdür (GBM veya M5 gibi). Özelliklerin sayısı önemlidir ve ayarlanmalıdır. Bu durumda, özellik sayısını otomatik olarak ayarladığından rastgele orman yararlıdır. Ağaç sayısı ve türü o kadar önemli değil ama asla 500'den fazla ağaç kullanılmamalıdır çünkü zaman kaybıdır. Genel olarak, ağaç türleri ve ağaç sayısı verilere göre ayarlanır.
Rastgele Orman modelini nasıl optimize edersiniz?
Başarılı olmak için, Rastgele Orman algoritmasının (ve diğer karar ağacı varyantlarının) iki ana bileşeni, özelliklerin seçimi ve ağaç yapısıdır. Ağaç yapısıyla ilgili olarak, her ağaçta kullanılan ağaç sayısı ve özellikleriyle denemeler yapmanız gerekecektir. En önemlisi, modelinizin hem yeterince doğru olduğu hem de fazla uymadığı o tatlı noktayı bulmanız gerekiyor.
Makine öğreniminde Rastgele Orman nedir?
Rastgele ormanlar, karar ağaçları topluluğudur. Birçok farklı şekilde kullanılabilen güçlü ve esnek modellerdir. Aslında, rastgele ormanlar son on yılda çok popüler hale geldi. Model birçok farklı alanda (biyoloji, pazarlama, finans, metin madenciliği vb.) kullanılmaktadır. Büyük yarışmalarda kullanılmış ve son teknoloji sonuçlar üretmiştir. Rastgele ormanların en yaygın kullanımı, verileri sınıflandırmak (veya etiketlemek) içindir. Ancak, sürekli değerleri geri almak (bir değeri tahmin etmek) ve benzer veri noktalarını kümelemek için de kullanılabilirler.