
Réglage des hyperparamètres de la forêt aléatoire : processus expliqués avec le codage
Publié: 2020-12-23Random Forest est un algorithme d'apprentissage automatique qui utilise des arbres de décision comme base. Random Forest est facile à utiliser et un algorithme ML flexible. En raison de sa simplicité et de sa diversité, il est très largement utilisé. Il donne de bons résultats sur de nombreuses tâches de classification, même sans beaucoup de réglage des hyperparamètres.
Dans cet article, nous nous concentrerons principalement sur le fonctionnement de Random Forest et les différents hyper paramètres qui peuvent être contrôlés pour des résultats optimaux. Le besoin de réglage des hyperparamètres se fait sentir car chaque donnée a ses caractéristiques.
Ces caractéristiques peuvent être des types de variables, la taille des données, une variable cible binaire/multiclasse, le nombre de catégories dans les variables catégorielles, l'écart type des données numériques, la normalité des données, etc. maximiser les performances d'un modèle.
Table des matières
Construire et travailler
Random Forest Algorithm fonctionne comme une grande collection d'arbres de décision décorrélés. Elle est également connue sous le nom de technique d'ensachage. Le bagging tombe dans la catégorie de l'apprentissage d'ensemble et est basé sur la théorie selon laquelle la combinaison de modèles bruyants et non biaisés peut être moyennée pour créer un modèle à faible variance. Comprenons comment une forêt aléatoire est construite.
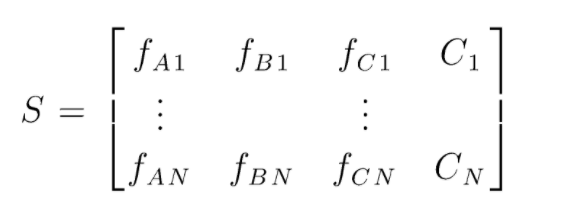
S est la matrice des données présentes pour effectuer la classification aléatoire des forêts. Il y a N instances présentes et A,B,C sont les caractéristiques des données. À partir de ces données, des sous-ensembles aléatoires de données sont créés. Sur quels arbres de décision sont créés. Comme nous pouvons le voir sur la figure ci-dessous, un arbre de décision est créé par sous-ensemble de données, et selon la taille des données, les arbres de décision sont également augmentés.
La sortie de tous les arbres de décision entraînés est votée et la classe votée majoritairement est la sortie effective d'un algorithme de forêt aléatoire. Les modèles d'arbre de décision surajustent les données, d'où la nécessité d'une forêt aléatoire. Les modèles d'arbre de décision peuvent être à faible biais, mais ils sont pour la plupart à variance élevée. Par conséquent, pour réduire cette erreur de variance sur l'ensemble de test, Random Forest est utilisé.

Hyperparamètres
Il existe différents hyperparamètres qui peuvent être contrôlés dans une forêt aléatoire :
- N_estimators : le nombre d'arbres de décision en cours de construction dans la forêt. Les valeurs par défaut dans sklearn sont 100. Les N_estimators sont principalement corrélés à la taille des données, pour encapsuler les tendances dans les données, un plus grand nombre de DT est nécessaire.
- Critère : la fonction utilisée pour mesurer la qualité des divisions dans un arbre de décision (problème de classification). Les critères pris en charge sont gini : gini impureté ou entropie : gain d'information. En cas de régression, l'erreur absolue moyenne (MAE) ou l'erreur quadratique moyenne (MSE) peut être utilisée. La valeur par défaut est gini et mse.
- Max_depth : les niveaux maximum autorisés dans un arbre de décision. S'il est défini sur rien, l'arbre de décision continuera à se diviser jusqu'à ce que la pureté soit atteinte.
- Max_features : nombre maximal de fonctionnalités utilisées pour un processus de fractionnement de nœud. Types : sqrt, log2. Si le nombre total d'entités est de n_entités, alors : sqrt(n_entités) ou log2(n_entités) peuvent être sélectionnés comme entités maximales pour le fractionnement des nœuds.
- Bootstrap : des échantillons de bootstrap sont utilisés lors de la création d'arbres de décision si True est sélectionné dans bootstrap, sinon des données entières sont utilisées pour chaque arbre de décision.
- Min_samples_split : ce paramètre détermine le nombre minimum d'échantillons requis pour diviser un nœud interne. Valeur par défaut =2. Le problème avec une si petite valeur est que la condition est vérifiée sur le nœud terminal. Si les points de données dans le nœud dépassent la valeur 2, un autre fractionnement a lieu. Alors que si une valeur plus indulgente comme 6 est définie, le fractionnement s'arrêtera tôt et l'arbre de décision ne surajustera pas les données.
- Min_sample_leaf : ce paramètre définit le nombre minimum d'exigences de points de données dans un nœud de l'arbre de décision. Cela affecte le nœud terminal et aide essentiellement à contrôler la profondeur de l'arbre. Si, après une scission, les points de données d'un nœud passent sous le nombre min_sample_leaf, la scission ne passera pas et sera arrêtée au nœud parent.
Il existe d'autres paramètres moins importants qui peuvent également être pris en compte lors du processus de réglage des hyperparamètres.
n_jobs : nombre de processeurs pouvant être utilisés pour la formation. (-1 pour pas de limite)
max_samples : les données maximales pouvant être utilisées dans chaque arbre de décision
random_state : le modèle avec un random_state spécifique produira une précision/des sorties similaires.
Class_weight : entrée du dictionnaire, qui peut gérer des ensembles de données déséquilibrés.
Doit lire : Types d'algorithmes d'IA
Processus de réglage des hyperparamètres
Il existe différentes manières d'effectuer des processus de réglage d'hyperparamètres. Une fois le modèle de base créé et évalué, les hyperparamètres peuvent être réglés pour augmenter certaines métriques spécifiques telles que la précision ou le score f1 du modèle.

Il faut vérifier le surajustement et les erreurs de variance de biais avant et après les ajustements. Le modèle doit être réglé en fonction des besoins en temps réel. Parfois, un modèle de surajustement peut être très sensible à la fluctuation des données lors de la validation. Par conséquent, les scores de validation croisée avec l'écart de validation croisée doivent être vérifiés pour un éventuel surajustement avant et après le réglage du modèle.
Les méthodes de réglage Random Forest sur python sont décrites ci-dessous.
CV de recherche aléatoire
Nous pouvons utiliser scikit learn et RandomisedSearchCV où nous pouvons définir la grille, le modèle de forêt aléatoire sera ajusté encore et encore en sélectionnant au hasard des paramètres de la grille. Nous n'obtiendrons pas les meilleurs paramètres, mais nous obtiendrons certainement le meilleur modèle parmi les différents modèles montés et testés.
Code source:
à partir de sklearn.model_selection importer GridSearchCV
# Créez une grille de recherche de paramètres qui seront mélangés
param_grid = {
'bootstrap' : [Vrai],
'max_depth' : [10, 20, 30, 40, 50, 60, 70, 80, 90, 100, Aucun],
'max_features' : ['auto', 'sqrt'],
'min_samples_leaf' : [1, 2, 4],
'min_samples_split' : [2, 5, 10],
'n_estimators' : [200, 400, 600, 800, 1000, 1200, 1400, 1600, 1800, 2000]
}
# Utilisation de la grille aléatoire et recherche des meilleurs hyperparamètres
rf = RandomForestRegressor() #création du modèle de base
rf_random = RandomizedSearchCV(estimator = rf, param_distributions = random_grid, n_iter = 100, cv = 5, verbose=2, random_state=42, n_jobs = -1)
rf_random.fit(train_features, train_labels) #fit est de lancer le processus de formation
La fonction de recherche aléatoire recherchera les paramètres via une validation croisée 5 fois et 100 itérations pour aboutir aux meilleurs paramètres.
Grille de recherche CV
La recherche par grille est utilisée après une recherche aléatoire pour affiner la plage afin de rechercher les hyperparamètres parfaits. Maintenant que nous savons où nous pouvons nous concentrer, nous pouvons explicitement exécuter ces paramètres via une recherche de grille et évaluer différents modèles pour obtenir les valeurs finales pour chaque hyperparamètre.
Code source:
à partir de sklearn.model_selection importer GridSearchCV
# Créez la grille de paramètres en fonction des résultats de la recherche aléatoire
param_grid = {
'bootstrap' : [Vrai],
'profondeur_max' : [80, 90, 100, 110],
'max_features' : [2, 3],
'min_samples_leaf' : [3, 4, 5],
'min_samples_split' : [8, 10, 12],
'n_estimators' : [100, 200, 300, 1000]
}
# Créer un modèle basé
rf = RandomForestRegressor()
# Instancier le modèle de recherche de grille
grid_search = GridSearchCV(estimator = rf, param_grid = param_grid,
cv = 3, n_jobs = -1, verbeux = 2)
Résultats après exécution :
# Adapter la grille de recherche aux données
grid_search.fit(train_features, train_labels)
grid_search.best_params_
{'bootstrap' : Vrai,
'profondeur_max' : 80,
'max_features' : 3,
'min_samples_leaf' : 5,
'min_samples_split' : 12,
'n_estimators' : 100}
best_grid = grid_search.best_estimator_
Lisez aussi : Idées de projets d'apprentissage automatique
Conclusion
Nous avons parcouru le fonctionnement d'un modèle de forêt aléatoire et comment chaque hyperparamètre fonctionne pour modifier les arbres de décision et donc le modèle de forêt aléatoire dans son ensemble. Nous avons également examiné la technique efficace pour combiner l'utilisation de la recherche aléatoire et de la grille pour obtenir les meilleurs paramètres pour notre modèle. Le réglage des hyperparamètres est très important car il nous aide à contrôler les performances de biais et de variance de notre modèle.
Si vous souhaitez en savoir plus sur l'arbre de décision, l'apprentissage automatique, consultez le diplôme PG d'IIIT-B et upGrad en apprentissage automatique et IA, conçu pour les professionnels en activité et offrant plus de 450 heures de formation rigoureuse, plus de 30 études de cas et affectations, statut IIIT-B Alumni, 5+ projets de synthèse pratiques et aide à l'emploi avec les meilleures entreprises.
Quels hyperparamètres peuvent être réglés dans une forêt aléatoire ?
Dans une forêt aléatoire, les hyperparamètres sont le nombre d'arbres, le nombre d'entités et le type d'arbres (comme GBM ou M5). Le nombre de fonctionnalités est important et doit être réglé. Dans ce cas, la forêt aléatoire est utile car elle règle automatiquement le nombre d'entités. Le nombre d'arbres et le type d'arbres ne sont pas si importants, mais il ne faut jamais utiliser plus de 500 arbres car c'est une perte de temps. De manière générale, le type d'arbres et le nombre d'arbres sont réglés en fonction des données.
Comment optimiser un modèle Random Forest ?
Pour réussir, les deux principaux composants de l'algorithme Random Forest (et d'autres variantes d'arbre de décision) sont la sélection des caractéristiques et la structure arborescente. En ce qui concerne l'arborescence, vous devrez expérimenter le nombre d'arbres et les fonctionnalités utilisées dans chaque arbre. Plus important encore, vous devez trouver le point idéal où votre modèle est à la fois suffisamment précis et ne sur-ajuste pas.
Qu'est-ce que Random Forest dans l'apprentissage automatique ?
Les forêts aléatoires sont un ensemble d'arbres de décision. Ce sont des modèles puissants et flexibles qui peuvent être utilisés de différentes manières. En fait, les forêts aléatoires sont devenues très populaires au cours de la dernière décennie. Le modèle est utilisé dans de nombreux domaines différents (biologie, marketing, finance, text mining, etc.). Il a été utilisé dans des compétitions majeures et a produit des résultats à la pointe de la technologie. L'utilisation la plus courante des forêts aléatoires consiste à classer (ou étiqueter) les données. Mais, ils peuvent également être utilisés pour régresser des valeurs continues (estimer une valeur) et pour regrouper des points de données similaires.