
ضبط فرط معلمة الغابة العشوائية: شرح العمليات مع الترميز
نشرت: 2020-12-23Random Forest هي خوارزمية تعلم آلي تستخدم أشجار القرار كأساس لها. تعد Random Forest سهلة الاستخدام وخوارزمية ML مرنة. نظرًا لبساطته وتنوعه ، يتم استخدامه على نطاق واسع جدًا. إنه يعطي نتائج جيدة في العديد من مهام التصنيف ، حتى بدون ضبط المعلمات الفائقة.
في هذه المقالة ، سنركز بشكل رئيسي على عمل Random Forest والمعلمات الفائقة المختلفة التي يمكن التحكم فيها للحصول على أفضل النتائج. تنشأ الحاجة إلى ضبط Hyperparameter لأن كل بيانات لها خصائصها.
يمكن أن تكون هذه الخصائص أنواعًا من المتغيرات ، وحجم البيانات ، ومتغير هدف ثنائي / متعدد الفئات ، وعدد الفئات في المتغيرات الفئوية ، والانحراف المعياري للبيانات الرقمية ، والحالة الطبيعية في البيانات ، وما إلى ذلك ، ومن ثم فإن ضبط النموذج وفقًا للبيانات أمر ضروري لـ تعظيم أداء النموذج.
جدول المحتويات
البناء والعمل
تعمل خوارزمية Random Forest كمجموعة كبيرة من أشجار القرار ذات الصلة. تُعرف أيضًا باسم تقنية التعبئة. يندرج التعبئة في فئة التعلم الجماعي ويستند إلى النظرية القائلة بأنه يمكن حساب متوسط مزيج من النماذج الصاخبة وغير المنحازة لإنشاء نموذج بتباين منخفض. دعونا نفهم كيف يتم إنشاء الغابة العشوائية.
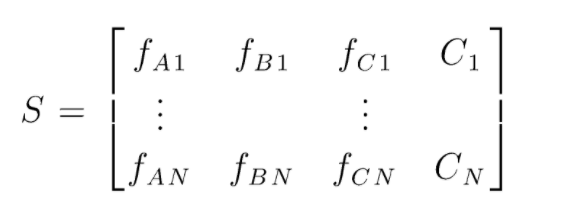
S هي مصفوفة البيانات الموجودة لإجراء تصنيف عشوائي للغابات. هناك حالات N موجودة و A و B و C هي ميزات البيانات. من هذه البيانات ، يتم إنشاء مجموعات فرعية عشوائية من البيانات. فوق أي أشجار القرار يتم إنشاؤها. كما نرى من الشكل أدناه ، يتم إنشاء شجرة قرار واحدة لكل مجموعة فرعية من البيانات ، واعتمادًا على حجم البيانات ، يتم أيضًا زيادة أشجار القرار.
يتم التصويت على ناتج جميع أشجار القرار المدربة وفئة الأغلبية هي الناتج الفعال لخوارزمية Random Forest. نماذج شجرة القرار تتفوق على البيانات ومن ثم تنشأ الحاجة إلى Random Forest. قد تكون نماذج شجرة القرار منخفضة التحيز لكنها في الغالب عالية التباين. ومن ثم لتقليل خطأ التباين هذا في مجموعة الاختبار ، يتم استخدام Random Forest.

Hyperparameters
هناك العديد من المعلمات التشعبية التي يمكن التحكم فيها في مجموعة عشوائية:
- N_estimators: عدد أشجار القرار التي يتم بناؤها في الغابة. القيم الافتراضية في sklearn هي 100. ترتبط N_estimators في الغالب بحجم البيانات ، لتغليف الاتجاهات في البيانات ، هناك حاجة إلى عدد أكبر من DTs.
- المعيار: الوظيفة المستخدمة لقياس جودة الانقسامات في شجرة القرار (مشكلة التصنيف). المعايير المدعومة هي جيني: شوائب جيني أو إنتروبيا: اكتساب المعلومات. في حالة الانحدار يمكن استخدام متوسط الخطأ المطلق (MAE) أو متوسط الخطأ التربيعي (MSE). الافتراضي هو جيني و MSE.
- Max_depth: المستويات القصوى المسموح بها في شجرة القرار. إذا تم التعيين على لا شيء ، ستستمر شجرة القرار في الانقسام حتى الوصول إلى النقاء.
- Max_features: الحد الأقصى لعدد الميزات المستخدمة في عملية انقسام العقدة. الأنواع: الجذر التربيعي ، السجل 2. إذا كان إجمالي الميزات عبارة عن n_features ، فيمكن تحديد sqrt (n_features) أو log2 (n_features) كميزات قصوى لتقسيم العقدة.
- Bootstrap: يتم استخدام عينات Bootstrap عند إنشاء أشجار القرار إذا تم تحديد True في bootstrap ، وإلا يتم استخدام البيانات الكاملة لكل شجرة قرار.
- Min_samples_split: تحدد هذه المعلمة الحد الأدنى لعدد العينات المطلوبة لتقسيم عقدة داخلية. القيمة الافتراضية = 2. المشكلة مع هذه القيمة الصغيرة هي أن الشرط يتم فحصه على العقدة الطرفية. إذا تجاوزت نقاط البيانات في العقدة القيمة 2 ، فسيحدث المزيد من الانقسام. في حين أنه إذا تم تعيين قيمة أكثر تساهلاً مثل 6 ، فسيتوقف التقسيم مبكرًا ولن تفرط شجرة القرار في البيانات.
- Min_sample_leaf: تحدد هذه المعلمة الحد الأدنى لعدد متطلبات نقطة البيانات في عقدة من شجرة القرار. إنه يؤثر على العقدة الطرفية ويساعد بشكل أساسي في التحكم في عمق الشجرة. بعد الانقسام ، إذا دخلت نقاط البيانات في العقدة تحت رقم min_sample_leaf ، فلن يمر الانقسام وسيتم إيقافه عند العقدة الأصلية.
هناك معلمات أخرى أقل أهمية يمكن أخذها في الاعتبار أثناء عملية ضبط المعلمة الفائقة.
n_jobs: عدد المعالجات التي يمكن استخدامها للتدريب. (-1 بدون حد)
max_samples: الحد الأقصى للبيانات التي يمكن استخدامها في كل شجرة قرار
random_state: النموذج الذي له حالة عشوائية محددة سينتج دقة / مخرجات مماثلة.
Class_weight: إدخال القاموس ، يمكنه التعامل مع مجموعات البيانات غير المتوازنة.
يجب أن تقرأ: أنواع خوارزمية الذكاء الاصطناعي
عمليات ضبط Hyperparameter
هناك طرق مختلفة لأداء عمليات الضبط الفائق. بعد إنشاء النموذج الأساسي وتقييمه ، يمكن ضبط المعلمات الفائقة لزيادة بعض المقاييس المحددة مثل الدقة أو درجة f1 للنموذج.
يجب على المرء التحقق من التجهيز الزائد وأخطاء تباين التحيز قبل التعديلات وبعدها. يجب ضبط النموذج وفقًا لمتطلبات الوقت الفعلي. في بعض الأحيان ، قد يكون نموذج فرط التخصيص حساسًا جدًا لتقلب البيانات في التحقق من الصحة ، ومن ثم يجب التحقق من درجات التحقق من الصحة المتقاطعة مع انحراف التحقق المتقاطع بحثًا عن زيادة محتملة قبل ضبط النموذج وبعده.
يتم تناول طرق ضبط الغابة العشوائية على الثعبان بعد ذلك.
البحث العشوائي للسيرة الذاتية
يمكننا استخدام scikit Learn و RandomisedSearchCV حيث يمكننا تحديد الشبكة ، وسيتم تركيب نموذج الغابة العشوائية مرارًا وتكرارًا عن طريق اختيار معلمات عشوائيًا من الشبكة. لن نحصل على أفضل المعلمات ، لكننا سنحصل بالتأكيد على أفضل طراز من الطرز المختلفة التي يتم تركيبها واختبارها.

مصدر الرمز:
من sklearn.model_selection استيراد GridSearchCV
# إنشاء شبكة بحث من المعلمات التي سيتم خلطها من خلال
param_grid = {
"التمهيد": [صحيح] ،
"max_depth": [10 ، 20 ، 30 ، 40 ، 50 ، 60 ، 70 ، 80 ، 90 ، 100 ، بلا] ،
'max_features': ['auto'، 'sqrt']،
"min_samples_leaf": [1، 2، 4]،
"min_samples_split": [2 ، 5 ، 10] ،
"n_estimators": [200، 400، 600، 800، 1000، 1200، 1400، 1600، 1800، 2000]
}
# استخدام الشبكة العشوائية والبحث عن أفضل المعلمات التشعبية
rf = RandomForestRegressor () # إنشاء نموذج أساسي
rf_random = RandomizedSearchCV (المقدر = rf ، param_distributions = random_grid ، n_iter = 100 ، cv = 5 ، مطول = 2 ، random_state = 42 ، n_jobs = -1)
rf_random.fit (train_features، train_labels) # fit هو بدء عملية التدريب
ستقوم وظيفة البحث العشوائي بالبحث عن المعلمات من خلال التحقق من صحة 5 أضعاف و 100 تكرار للوصول إلى أفضل المعلمات.
شبكة البحث السيرة الذاتية
يستخدم البحث الشبكي بعد البحث العشوائي لتضييق النطاق للبحث عن المعلمات التشعبية المثالية. الآن بعد أن عرفنا أين يمكننا التركيز ، يمكننا تشغيل هذه المعلمات بشكل صريح من خلال بحث الشبكة وتقييم نماذج مختلفة للحصول على القيم النهائية لكل معلمة تشعبية.
مصدر الرمز:
من sklearn.model_selection استيراد GridSearchCV
# قم بإنشاء شبكة المعلمة بناءً على نتائج البحث العشوائي
param_grid = {
"التمهيد": [صحيح] ،
"max_depth": [80 ، 90 ، 100 ، 110] ،
"max_features": [2، 3]،
"min_samples_leaf": [3 ، 4 ، 5] ،
"min_samples_split": [8 ، 10 ، 12] ،
"n_estimators": [100، 200، 300، 1000]
}
# إنشاء نموذج قائم
rf = RandomForestRegressor ()
# إنشاء نموذج بحث الشبكة
grid_search = GridSearchCV (المقدر = rf ، param_grid = param_grid ،
السيرة الذاتية = 3 ، n_jobs = -1 ، مطول = 2)
النتائج بعد التنفيذ:
# ملاءمة البحث الشبكي للبيانات
Grid_search.fit (ميزات_قطار ، تصنيفات_قطار)
الشبكة_البحوث_أفضل_المعلمات_
{'bootstrap': صحيح ،
"أقصى عمق": 80 ،
"الحد الأقصى للميزات": 3 ،
"min_samples_leaf": 5 ،
"min_samples_split": 12 ،
"n_estimators": 100}
best_grid = grid_search.best_estimator_
اقرأ أيضًا: أفكار مشروع التعلم الآلي
خاتمة
لقد مررنا بعمل نموذج الغابة العشوائية وكيف تعمل كل معلمة تشعبية على تغيير أشجار القرار وبالتالي نموذج الغابة العشوائية ككل. لقد ألقينا أيضًا نظرة على التقنية الفعالة للجمع بين استخدام البحث العشوائي والبحث الشبكي للوصول إلى أفضل المعلمات لنموذجنا. يعد ضبط Hyperparameter مهمًا جدًا لأنه يساعدنا في التحكم في أداء التحيز والتباين في نموذجنا.
إذا كنت مهتمًا بمعرفة المزيد حول شجرة القرار ، التعلم الآلي ، فراجع IIIT-B & upGrad's دبلوم PG في التعلم الآلي والذكاء الاصطناعي المصمم للمهنيين العاملين ويقدم أكثر من 450 ساعة من التدريب الصارم ، وأكثر من 30 دراسة حالة و المهام ، وحالة خريجي IIIT-B ، وأكثر من 5 مشاريع تتويجا عملية ومساعدة وظيفية مع كبرى الشركات.
ما هي المعلمات الفائقة التي يمكن ضبطها في مجموعة عشوائية؟
في مجموعة التفرعات العشوائية ، تكون المعلمات التشعبية هي عدد الأشجار وعدد الميزات ونوع الأشجار (مثل GBM أو M5). عدد الميزات مهم ويجب ضبطه. في هذه الحالة ، يكون Random Forest مفيدًا لأنه يضبط عدد الميزات تلقائيًا. عدد الأشجار ونوعها ليسا بهذه الأهمية ، لكن لا ينبغي أبدًا استخدام أكثر من 500 شجرة لأنها مضيعة للوقت. بشكل عام ، يتم ضبط نوع الأشجار وعدد الأشجار وفقًا للبيانات.
كيف تقوم بتحسين نموذج الغابة العشوائية؟
لكي تكون ناجحًا ، فإن المكونين الرئيسيين لخوارزمية Random Forest (ومتغيرات شجرة القرار الأخرى) هما اختيار الميزات وهيكل الشجرة. فيما يتعلق ببنية الشجرة ، سيكون عليك تجربة عدد الأشجار والميزات المستخدمة في كل شجرة. الأهم من ذلك ، أنك تحتاج إلى العثور على تلك البقعة الرائعة حيث يكون نموذجك دقيقًا بدرجة كافية ولا يتناسب بشكل زائد.
ما هي Random Forest في التعلم الآلي؟
الغابات العشوائية عبارة عن مجموعة من أشجار القرار. إنها نماذج قوية ومرنة يمكن استخدامها بعدة طرق مختلفة. في الواقع ، أصبحت الغابات العشوائية شائعة جدًا خلال العقد الماضي. يستخدم النموذج في العديد من المجالات المختلفة (علم الأحياء ، التسويق ، التمويل ، التنقيب عن النصوص ، إلخ). لقد تم استخدامه في المسابقات الكبرى وأنتج نتائج متطورة. الاستخدام الأكثر شيوعًا للغابات العشوائية هو تصنيف (أو تسمية) البيانات. ولكن ، يمكن استخدامها أيضًا لتراجع القيم المستمرة (تقدير القيمة) ولتجميع نقاط البيانات المتشابهة.