
Python中的交叉驗證:你需要知道的一切
已發表: 2020-02-14在數據科學中,驗證可能是數據科學家用來驗證 ML 模型的穩定性並評估其泛化到新數據的能力的最重要技術之一。 驗證確保 ML 模型從數據集中提取正確(相關)模式,同時成功消除數據集中的噪聲。 本質上,驗證技術的目標是確保 ML 模型具有低偏差方差因子。
今天我們將詳細討論一種這樣的模型驗證技術——交叉驗證。
目錄
什麼是交叉驗證?
交叉驗證是一種驗證技術,旨在評估和評估統計分析(模型)的結果將如何推廣到獨立數據集。 交叉驗證主要用於以預測為主要目標的場景,用戶希望估計預測模型在現實世界中的表現如何。
交叉驗證旨在通過在訓練階段測試模型來定義數據集,以幫助最大限度地減少過度擬合和欠擬合等問題。 但是,您必須記住,驗證集和訓練集必須從同一分佈中提取,否則會導致驗證階段出現問題。
學習世界頂尖大學的數據科學認證課程。 獲得行政 PG 課程、高級證書課程或碩士課程,以加快您的職業生涯。
交叉驗證的好處
- 它有助於評估模型的質量。
- 它有助於減少/避免過擬合和欠擬合的問題。
- 它使您可以選擇將在看不見的數據上提供最佳性能的模型。
閱讀:面向初學者的 Python 項目
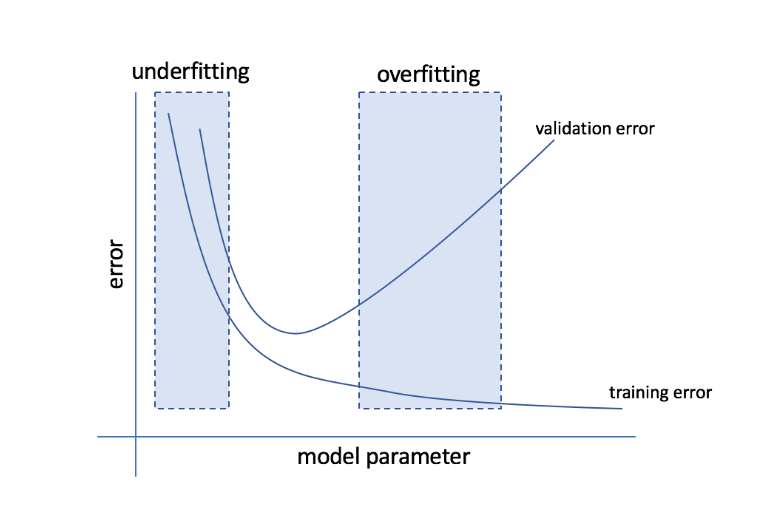
什麼是過擬合和欠擬合?
過度擬合是指模型變得對數據過於敏感並最終捕獲大量噪聲和隨機模式而無法很好地推廣到看不見的數據的情況。 雖然這樣的模型通常在訓練集上表現良好,但在測試集上表現不佳。
欠擬合是指模型未能在數據集中捕獲足夠多的模式,從而導致訓練集和測試集的性能不佳的問題。
從這兩個極端來看,完美的模型是在訓練集和測試集上表現同樣出色的模型。
資源
交叉驗證:不同的驗證策略
驗證策略根據數據集中完成的拆分數量進行分類。 現在,讓我們看看 Python 中不同的交叉驗證策略。
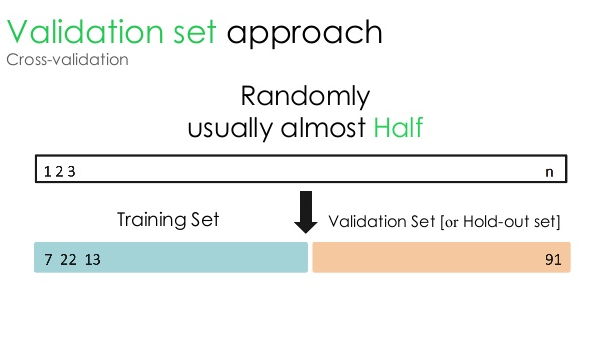
1.驗證集
這種驗證方法將數據集分成兩個相等的部分——50% 的數據集保留用於驗證,剩餘的 50% 保留用於模型訓練。 由於這種方法僅基於給定數據集的 50% 來訓練模型,因此總是有可能遺漏隱藏在其他 50% 數據中的相關且有意義的信息。 因此,這種方法通常會在模型中產生更高的偏差。
資源
Python代碼:
訓練,驗證 = train_test_split(數據,test_size=0.50,random_state = 5)
2. 訓練/測試拆分
在這種驗證方法中,數據集分為兩部分——訓練集和測試集。 這樣做是為了避免訓練集和測試集之間的任何重疊(如果訓練集和測試集重疊,模型就會出錯)。 因此,確保用於模型的數據集不能在我們的數據集中包含任何重複的樣本至關重要。 訓練/測試拆分策略允許您基於整個數據集重新訓練模型,而無需更改模型的任何超參數。

資源
然而,這種方法有一個明顯的局限性——模型的性能和準確性在很大程度上取決於它的分割方式。 例如,如果拆分不是隨機的,或者數據集的一個子集只有完整信息的一部分,則會導致過度擬合。 使用這種方法,您無法確定哪些數據點將在哪個驗證集中,從而為不同的集創建不同的結果。 因此,只有當您手頭有足夠的數據時,才應使用訓練/測試拆分策略。
Python代碼:
>>> 從 sklearn.model_selection 導入 train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
數組([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>>列表(y)
[0, 1, 2, 3, 4]
3. K折
如前兩種策略所見,有可能遺漏數據集中的重要信息,這增加了偏差導致的錯誤或過擬合的概率。 這就需要一種方法,既要為模型訓練保留大量數據,又要為驗證留下足夠的數據。
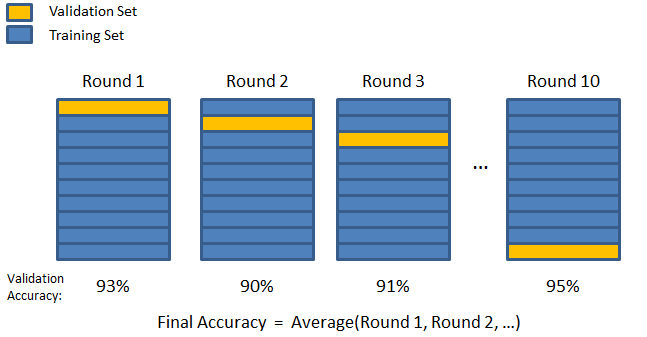
輸入 K 折驗證技術。 在該策略中,數據集被分成“k”個子集或折疊,其中 k-1 個子集保留用於模型訓練,最後一個子集用於驗證(測試集)。 該模型對各個折疊進行平均,然後最終確定。 模型完成後,您可以使用測試集對其進行測試。

資源
在這裡,每個數據點在驗證集中只出現一次,而在訓練集中保留 k-1 次。 由於大部分數據用於擬合,因此欠擬合問題顯著減少。 同樣,由於大部分數據也用於驗證集中,因此消除了過度擬合的問題。
閱讀: Python vs Ruby:完整的並排比較
K-fold 策略最適合數據量有限且折疊質量或它們之間存在不同最佳參數的情況。
Python代碼:
從 sklearn.model_selection 導入 KFold # 導入 KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # 創建一個數組
y = np.array([1, 2, 3, 4]) # 創建另一個數組
kf = KFold(n_splits=2) # 定義拆分 - 成 2 折
kf.get_n_splits(X) # 返回交叉驗證器中的分裂迭代次數
打印(kf)
KFold(n_splits=2, random_state=None, shuffle=False)
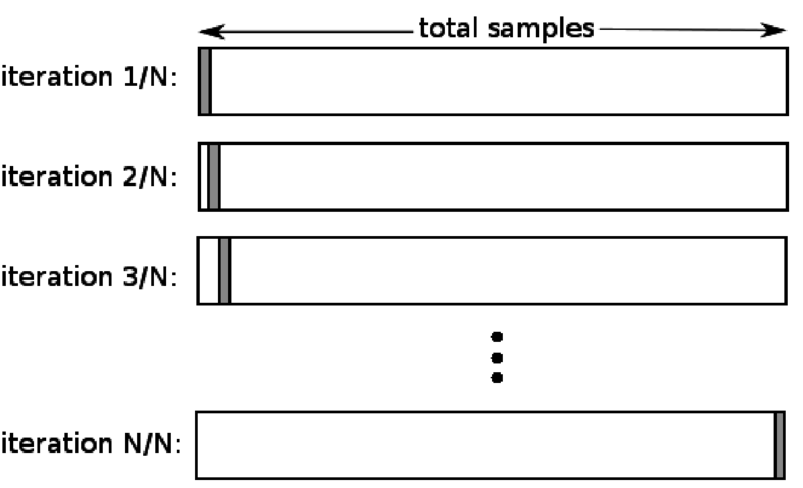
4.留下一個
當 k 等於特定數據集中的樣本數時,留一法交叉驗證 (LOOCV) 是 K-fold 的一種特殊情況。 這裡只為測試集保留一個數據點,數據集的其餘部分是訓練集。 因此,如果您使用“k-1”對像作為訓練樣本,使用“1”對像作為測試集,它們將繼續遍歷數據集中的每個樣本。 當可用數據太少時,這是最有用的方法。
資源
由於這種方法使用所有數據點,因此偏差通常很低。 但是,由於驗證過程重複“n”次(n = 數據點數),因此會導致更長的執行時間。 這些方法的另一個顯著限制是,當您針對一個數據點測試模型時,它可能會導致測試模型有效性的更大變化。 因此,如果該數據點是異常值,則會產生更高的變異商。
Python代碼:
>>> 將 numpy 導入為 np
>>> 從 sklearn.model_selection 導入 LeaveOneOut
>>> X = np.array([[1, 2], [3, 4]])
>>> y = np.array([1, 2])
>>> loo = LeaveOneOut()
>>> loo.get_n_splits(X)
2
>>> 打印(廁所)
LeaveOneOut()
>>> 對於 loo.split(X) 中的 train_index、test_index:
… 打印(“火車:”,train_index,“TEST:”,test_index)
… X_train, X_test = X[train_index], X[test_index]
… y_train, y_test = y[train_index], y[test_index]
… 打印(X_train,X_test,y_train,y_test)
火車:[1] 測試:[0]
[[3 4]] [[1 2]] [2] [1]
火車:[0] 測試:[1]
[[1 2]] [[3 4]] [1] [2]
5.分層
通常,對於訓練/測試拆分和 K-fold,數據會被打亂以創建隨機訓練和驗證拆分。 因此,它允許在不同的折疊中進行不同的目標分佈。 同樣,分層還有助於在拆分數據時在不同折疊上進行目標分佈。
在這個過程中,數據在不同的折疊中重新排列,以確保每個折疊成為整體的代表。 因此,如果您正在處理一個二元分類問題,其中每個類包含 50% 的數據,您可以使用分層來排列數據,使每個類包含一半的實例。
分層過程最適合具有多類分類的小型和不平衡數據集。
Python代碼:
從 sklearn.model_selection 導入 StratifiedKFold
skf = StratifiedKFold(n_splits=5, random_state=None)
# X是特徵集,y是目標
對於 skf.split(X,y) 中的 train_index、test_index:
打印(“火車:”,train_index,“驗證:”,val_index)
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[train_index], y[val_index]
閱讀: Python 中的數據框 – 教程
何時使用這五種交叉驗證策略中的每一種?
正如我們之前提到的,每種交叉驗證技術都有獨特的用例,因此,當正確應用於正確的場景時,它們的性能最好。 例如,如果您有足夠的數據,並且(模型的)不同拆分的分數和最佳參數可能相似,那麼訓練/測試拆分方法將非常有效。
但是,如果分數和最佳參數因不同的拆分而不同,則 K-fold 技術將是最好的。 對於數據太少的情況,LOOCV 方法效果最好,而對於小型且不平衡的數據集,分層是可行的方法。
我們希望這篇詳細的文章能幫助您深入了解 Python 中的交叉驗證。
如果您想了解數據科學,請查看 IIIT-B 和 upGrad 的數據科學執行 PG 計劃,該計劃是為在職專業人士創建的,提供 10 多個案例研究和項目、實用的實踐研討會、與行業專家的指導、1與行業導師一對一,400 多個小時的學習和頂級公司的工作協助。
ML 中的“置換測試”是什麼?
通過在數據集上生成測試統計量,然後對該數據的許多隨機排列,使用排列測試來評估模型的統計顯著性。 如果模型顯著,則初始檢驗統計值應落入原假設分佈的尾部之一。 要找到 p 值,您只需計算與初始測試統計量一樣嚴重或更極端的測試統計量的數量,然後將該數字除以我們計算的測試統計量的總數。 鑑於原假設為真,P 值是獲得至少與檢驗統計量一樣嚴重的結果的機會。
機器學習中交叉驗證的缺點是什麼?
1. 交叉驗證顯著延長了訓練週期。 以前,您只能在一個訓練集上訓練您的模型; 現在,您可以使用交叉驗證在多個訓練集上對其進行訓練。
2.在大多數情況下,您正在研究的結構在預測建模中會隨著時間的推移而發展。 因此,您可能會注意到訓練集和驗證集的變化。
3.交叉驗證需要大量的計算能力。
如何檢測 ML 模型中的過度擬合?
在評估數據之前,檢測過擬合幾乎是不可能的。 它可以幫助解決泛化數據集的困難,這是過擬合的一個內在特徵。 因此,可以將數據劃分為不同的子集,以使訓練和測試更容易。 在兩個數據集中看到的準確率比例可用於確定是否存在過度擬合。 如果模型在訓練集上的表現優於在測試集上的表現,則可能是過度擬合。
另一個建議是從一個非常基本的 ML 模型開始作為基線。 稍後,當您測試複雜的算法時,您將有一個基準來判斷增加的複雜性是否值得。
準確性和損失等驗證措施也可用於檢測過擬合。 當模型受到過度擬合的影響時,驗證度量通常會增長,直到它們達到穩定水平或開始下降。