
Validasi Silang dengan Python: Semua yang Perlu Anda Ketahui Tentang
Diterbitkan: 2020-02-14Dalam Ilmu Data, validasi mungkin merupakan salah satu teknik terpenting yang digunakan oleh Ilmuwan Data untuk memvalidasi stabilitas model ML dan mengevaluasi seberapa baik model tersebut akan digeneralisasi ke data baru. Validasi memastikan bahwa model ML mengambil pola yang benar (relevan) dari set data sekaligus berhasil menghilangkan noise di set data. Pada dasarnya, tujuan teknik validasi adalah untuk memastikan model ML memiliki faktor varian bias yang rendah.
Hari ini kita akan membahas panjang lebar salah satu teknik validasi model tersebut – Cross-Validation.
Daftar isi
Apa itu Cross-Validasi?
Cross-Validation adalah teknik validasi yang dirancang untuk mengevaluasi dan menilai bagaimana hasil analisis statistik (model) akan digeneralisasi ke kumpulan data independen. Cross-Validation terutama digunakan dalam skenario di mana prediksi adalah tujuan utama, dan pengguna ingin memperkirakan seberapa baik dan akurat model prediksi akan tampil dalam situasi dunia nyata.
Cross-Validation berupaya mendefinisikan kumpulan data dengan menguji model dalam fase pelatihan untuk membantu meminimalkan masalah seperti overfitting dan underfitting. Namun, Anda harus ingat bahwa validasi dan set pelatihan harus diekstraksi dari distribusi yang sama, jika tidak maka akan menimbulkan masalah dalam fase validasi.
Pelajari kursus sertifikasi ilmu data dari Universitas top dunia. Dapatkan Program PG Eksekutif, Program Sertifikat Tingkat Lanjut, atau Program Magister untuk mempercepat karier Anda.
Manfaat Cross-Validasi
- Ini membantu mengevaluasi kualitas model Anda.
- Ini membantu mengurangi/menghindari masalah overfitting dan underfitting.
- Ini memungkinkan Anda memilih model yang akan memberikan kinerja terbaik pada data yang tidak terlihat.
Baca: Proyek Python untuk Pemula
Apa itu Overfitting dan Underfitting?
Overfitting mengacu pada kondisi ketika model menjadi terlalu sensitif terhadap data dan akhirnya menangkap banyak noise dan pola acak yang tidak dapat digeneralisasi dengan baik ke data yang tidak terlihat. Sementara model seperti itu biasanya berkinerja baik di set pelatihan, kinerjanya menurun di set pengujian.
Underfitting mengacu pada masalah ketika model gagal menangkap pola yang cukup dalam kumpulan data, sehingga memberikan kinerja yang buruk baik untuk pelatihan maupun kumpulan pengujian.
Dengan menggunakan kedua ekstremitas ini, model yang sempurna adalah model yang memiliki performa yang sama baiknya untuk set pelatihan dan tes.
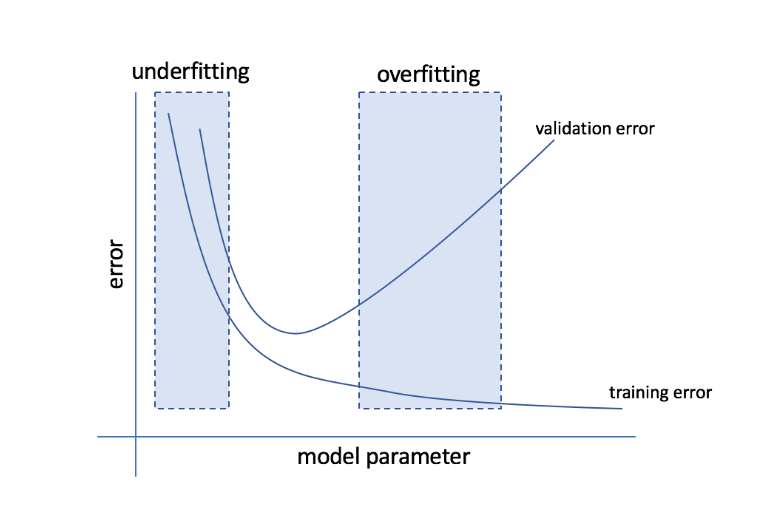
Sumber
Validasi Silang: Strategi Validasi Berbeda
Strategi validasi dikategorikan berdasarkan jumlah pemisahan yang dilakukan dalam kumpulan data. Sekarang, mari kita lihat strategi Cross-Validation yang berbeda dengan Python.
1. Set validasi
Pendekatan validasi ini membagi dataset menjadi dua bagian yang sama – sementara 50% dari dataset dicadangkan untuk validasi, 50% sisanya dicadangkan untuk pelatihan model. Karena pendekatan ini melatih model hanya berdasarkan 50% dari kumpulan data yang diberikan, selalu ada kemungkinan kehilangan informasi yang relevan dan bermakna yang tersembunyi di 50% data lainnya. Akibatnya, pendekatan ini umumnya menciptakan bias yang lebih tinggi dalam model.
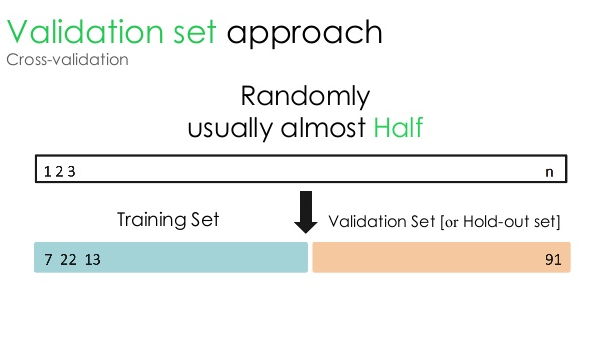
Sumber
kode python:
kereta, validasi = train_test_split(data, test_size=0,50, random_state = 5)
2. Perpecahan Kereta/Tes
Dalam pendekatan validasi ini, dataset dibagi menjadi dua bagian – training set dan test set. Hal ini dilakukan untuk menghindari tumpang tindih antara training set dan test set (jika training dan test set tumpang tindih, model akan rusak). Oleh karena itu, sangat penting untuk memastikan bahwa kumpulan data yang digunakan untuk model tidak boleh berisi sampel duplikat dalam kumpulan data kami. Strategi pemisahan latihan/pengujian memungkinkan Anda melatih kembali model Anda berdasarkan seluruh kumpulan data tanpa mengubah hyperparameter model apa pun.

Sumber
Namun, pendekatan ini memiliki satu batasan signifikan – kinerja dan akurasi model sangat bergantung pada cara pemisahannya. Misalnya, jika pemisahan tidak acak, atau satu subset dari dataset hanya memiliki sebagian dari informasi lengkap, itu akan menyebabkan overfitting. Dengan pendekatan ini, Anda tidak dapat memastikan titik data mana yang akan berada di set validasi mana, sehingga menciptakan hasil yang berbeda untuk set yang berbeda. Oleh karena itu, strategi split train/test hanya boleh digunakan jika Anda memiliki cukup data.
kode python:
>>> dari sklearn.model_selection impor train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
larik([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> daftar (y)
[0, 1, 2, 3, 4]
3. K-lipat
Seperti yang terlihat dalam dua strategi sebelumnya, ada kemungkinan kehilangan informasi penting dalam kumpulan data, yang meningkatkan kemungkinan kesalahan atau overfitting yang diinduksi bias. Ini memerlukan metode yang menyimpan banyak data untuk pelatihan model sambil juga menyisakan data yang cukup untuk validasi.
Masukkan teknik validasi K-fold. Dalam strategi ini, dataset dipecah menjadi 'k' jumlah subset atau fold, dimana k-1 subset dicadangkan untuk pelatihan model, dan subset terakhir digunakan untuk validasi (test set). Model dirata-ratakan terhadap lipatan individu dan kemudian diselesaikan. Setelah model selesai, Anda dapat mengujinya menggunakan set tes.
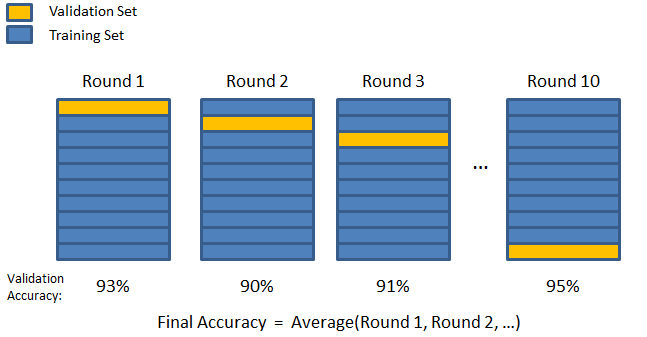
Sumber
Di sini, setiap titik data muncul di set validasi tepat satu kali sementara tetap di set pelatihan k-1 beberapa kali. Karena sebagian besar data digunakan untuk fitting, masalah underfitting berkurang secara signifikan. Demikian pula, masalah overfitting dihilangkan karena sebagian besar data juga digunakan dalam set validasi.

Baca: Python vs Ruby: Perbandingan Berdampingan Lengkap
Strategi K-fold adalah yang terbaik untuk kasus di mana Anda memiliki jumlah data yang terbatas, dan ada perbedaan substansial dalam kualitas fold atau parameter optimal yang berbeda di antara keduanya.
kode python:
dari sklearn.model_selection impor KFold # impor KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # membuat array
y = np.array([1, 2, 3, 4]) # Buat array lain
kf = KFold(n_splits=2) # Tentukan pembagian – menjadi 2 lipatan
kf.get_n_splits(X) # mengembalikan jumlah iterasi pemisahan di cross-validator
cetak (kf)
KFold(n_splits=2, random_state=Tidak ada, shuffle=False)
4. Tinggalkan satu
Leave one out cross-validation (LOOCV) adalah kasus khusus dari K-fold ketika k sama dengan jumlah sampel dalam kumpulan data tertentu. Di sini, hanya satu titik data yang dicadangkan untuk set pengujian, dan set data lainnya adalah set pelatihan. Jadi, jika Anda menggunakan objek "k-1" sebagai sampel pelatihan dan objek "1" sebagai set pengujian, mereka akan terus mengulangi setiap sampel dalam set data. Ini adalah metode yang paling berguna ketika ada terlalu sedikit data yang tersedia.
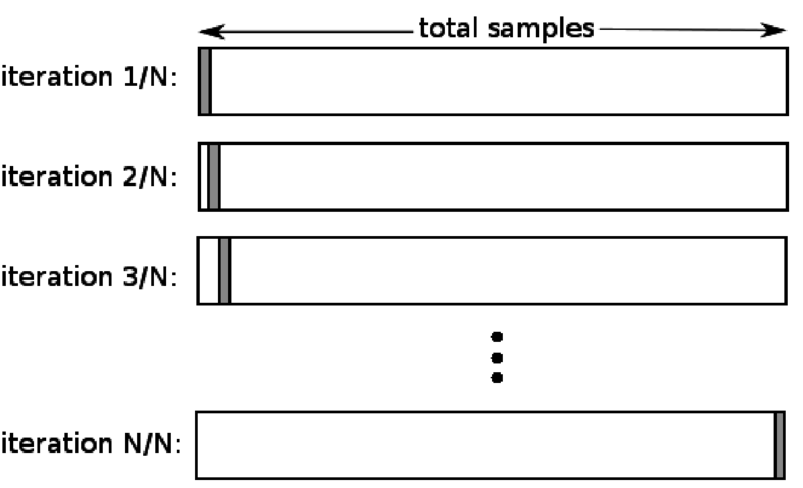
Sumber
Karena pendekatan ini menggunakan semua titik data, biasnya biasanya rendah. Namun, karena proses validasi diulang 'n' beberapa kali (n=jumlah titik data), proses ini menghasilkan waktu eksekusi yang lebih lama. Kendala penting lainnya dari metode ini adalah bahwa hal itu dapat menyebabkan variasi yang lebih tinggi dalam menguji efektivitas model saat Anda menguji model terhadap satu titik data. Jadi, jika titik data tersebut merupakan outlier, maka akan menghasilkan hasil bagi variasi yang lebih tinggi.
kode python:
>>> impor numpy sebagai np
>>> dari sklearn.model_selection impor LeaveOneOut
>>> X = np.array([[1, 2], [3, 4]])
>>> y = np.array([1, 2])
>>> loo = TinggalkanOneOut()
>>> loo.get_n_splits(X)
2
>>> cetak (toilet)
TinggalkanSatuKeluar()
>>> untuk train_index, test_index di loo.split(X):
… print(“TRAIN:”, train_index, “TEST:”, test_index)
… X_train, X_test = X[train_index], X[test_index]
… y_train, y_test = y[train_index], y[test_index]
… print(X_train, X_test, y_train, y_test)
KERETA API: [1] UJI: [0]
[[3 4]] [[1 2]] [2] [1]
KERETA API: [0] UJI: [1]
[[1 2]] [[3 4]] [1] [2]
5. Stratifikasi
Biasanya, untuk pemisahan pelatihan/pengujian dan lipatan-K, data dikocok untuk membuat pemisahan pelatihan dan validasi acak. Dengan demikian, memungkinkan untuk distribusi target yang berbeda di lipatan yang berbeda. Demikian pula, stratifikasi juga memfasilitasi distribusi target pada lipatan yang berbeda saat memisahkan data.
Dalam proses ini, data disusun ulang dalam lipatan yang berbeda dengan cara yang memastikan setiap lipatan menjadi perwakilan dari keseluruhan. Jadi, jika Anda berurusan dengan masalah klasifikasi biner di mana setiap kelas terdiri dari 50% data, Anda dapat menggunakan stratifikasi untuk mengatur data sedemikian rupa sehingga setiap kelas mencakup setengah dari contoh.
Proses stratifikasi paling cocok untuk kumpulan data kecil dan tidak seimbang dengan klasifikasi multikelas.
kode python:
dari sklearn.model_selection impor StratifiedKFold
skf = StratifiedKFold(n_splits=5, random_state=Tidak ada)
# X adalah kumpulan fitur dan y adalah targetnya
untuk train_index, test_index di skf.split(X,y):
print(“Kereta:”, indeks_kereta, “Validasi:”, val_index)
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[train_index], y[val_index]
Baca: Bingkai Data dengan Python – Tutorial
Kapan Menggunakan masing-masing dari lima strategi Validasi Silang ini?
Seperti yang kami sebutkan sebelumnya, setiap teknik Cross-Validation memiliki kasus penggunaan yang unik, dan karenanya, mereka bekerja paling baik bila diterapkan dengan benar ke skenario yang tepat. Misalnya, jika Anda memiliki cukup data, dan skor serta parameter optimal (dari model) untuk pemisahan yang berbeda kemungkinan besar akan serupa, pendekatan pemisahan kereta/tes akan bekerja dengan sangat baik.
Namun, jika skor dan parameter optimal bervariasi untuk pemisahan yang berbeda, teknik K-fold akan menjadi yang terbaik. Untuk contoh di mana Anda memiliki terlalu sedikit data, pendekatan LOOCV bekerja paling baik, sedangkan, untuk kumpulan data kecil dan tidak seimbang, stratifikasi adalah cara yang harus dilakukan.
Kami harap artikel terperinci ini membantu Anda mendapatkan ide mendalam tentang Validasi Silang dengan Python.
Jika Anda penasaran untuk belajar tentang ilmu data, lihat Program PG Eksekutif IIIT-B & upGrad dalam Ilmu Data yang dibuat untuk para profesional yang bekerja dan menawarkan 10+ studi kasus & proyek, lokakarya praktis, bimbingan dengan pakar industri, 1 -on-1 dengan mentor industri, 400+ jam pembelajaran dan bantuan pekerjaan dengan perusahaan-perusahaan top.
Apa itu 'tes permutasi' di ML?
Dengan menghasilkan statistik uji pada kumpulan data dan kemudian untuk banyak permutasi acak dari data tersebut, uji permutasi digunakan untuk menilai signifikansi statistik suatu model. Nilai statistik uji awal harus masuk ke salah satu ekor distribusi hipotesis nol jika modelnya signifikan. Untuk menemukan nilai-p, Anda hanya perlu menghitung jumlah statistik uji yang sama parahnya atau lebih ekstrem dari statistik uji awal dan kemudian membagi angka itu dengan jumlah total statistik uji yang kami hitung. Mengingat bahwa hipotesis nol benar, nilai-P adalah peluang untuk mendapatkan hasil yang setidaknya sama parahnya dengan statistik uji.
Apa kerugian dari validasi silang dalam pembelajaran mesin?
1. Cross Validation secara signifikan memperpanjang periode pelatihan. Sebelumnya, Anda hanya dapat melatih model Anda pada satu set pelatihan; sekarang, Anda dapat melatihnya di beberapa set pelatihan menggunakan Validasi Silang.
2.Dalam kebanyakan kasus, struktur yang Anda pelajari berkembang dari waktu ke waktu dalam pemodelan prediktif. Akibatnya, Anda mungkin melihat variasi dalam set pelatihan dan validasi.
3. Cross Validation membutuhkan banyak daya komputasi.
Bagaimana cara mendeteksi overfitting dalam model ML?
Sebelum Anda mengevaluasi data, mendeteksi overfitting hampir tidak mungkin. Ini dapat membantu dengan kesulitan menggeneralisasi kumpulan data, yang merupakan fitur intrinsik dari overfitting. Akibatnya, data dapat dibagi menjadi himpunan bagian yang berbeda untuk membuat pelatihan dan pengujian lebih mudah. Proporsi akurasi yang terlihat di kedua set data dapat digunakan untuk menentukan apakah ada overfitting atau tidak. Jika model berperforma lebih baik pada set pelatihan daripada pada set pengujian, ada kemungkinan model tersebut overfitting.
Saran lainnya adalah memulai dengan model ML yang sangat dasar untuk bertindak sebagai baseline. Kemudian, ketika Anda menguji algoritme kompleks, Anda akan memiliki tolok ukur untuk menilai apakah kompleksitas tambahan itu bermanfaat.
Langkah-langkah validasi seperti akurasi dan kerugian juga dapat digunakan untuk mendeteksi overfitting. Ketika model dipengaruhi oleh overfitting, langkah-langkah validasi umumnya tumbuh sampai mereka mendatar atau mulai menurun.