
Pythonでの相互検証:知っておくべきことすべて
公開: 2020-02-14データサイエンスでは、検証はおそらく、データサイエンティストが、MLモデルの安定性を検証し、それが新しいデータにどれだけうまく一般化するかを評価するために使用する最も重要な手法の1つです。 検証により、MLモデルがデータセットから適切な(関連する)パターンを取得し、データセット内のノイズを正常にキャンセルすることが保証されます。 基本的に、検証手法の目標は、MLモデルのバイアス分散係数が低いことを確認することです。
今日は、そのようなモデル検証手法の1つである相互検証について詳しく説明します。
目次
相互検証とは何ですか?
相互検証は、統計分析(モデル)の結果が独立したデータセットにどのように一般化されるかを評価および評価するために設計された検証手法です。 相互検証は主に、予測が主な目的であり、ユーザーが実際の状況で予測モデルがどれだけ適切かつ正確に実行されるかを推定したいシナリオで使用されます。
Cross-Validationは、トレーニングフェーズでモデルをテストしてデータセットを定義し、過剰適合や過適合などの問題を最小限に抑えることを目的としています。 ただし、検証とトレーニングセットの両方を同じディストリビューションから抽出する必要があることを覚えておく必要があります。そうしないと、検証フェーズで問題が発生します。
世界のトップ大学からデータサイエンス認定コースを学びましょう。 エグゼクティブPGプログラム、高度な証明書プログラム、または修士プログラムを取得して、キャリアを早急に進めましょう。
相互検証の利点
- モデルの品質を評価するのに役立ちます。
- 過剰適合および過適合の問題を軽減/回避するのに役立ちます。
- 見えないデータで最高のパフォーマンスを発揮するモデルを選択できます。
読む:初心者のためのPythonプロジェクト
過剰適合と過適合とは何ですか?
過剰適合とは、モデルがデータに敏感になりすぎて、目に見えないデータにうまく一般化されない多くのノイズやランダムパターンをキャプチャしてしまう状態を指します。 このようなモデルは通常、トレーニングセットではうまく機能しますが、テストセットではパフォーマンスが低下します。
アンダーフィッティングとは、モデルがデータセット内の十分なパターンをキャプチャできず、それによってトレーニングとテストセットの両方のパフォーマンスが低下する場合の問題を指します。
これらの2つの端を通り抜けると、完璧なモデルは、トレーニングセットとテストセットの両方で同等に機能するモデルです。
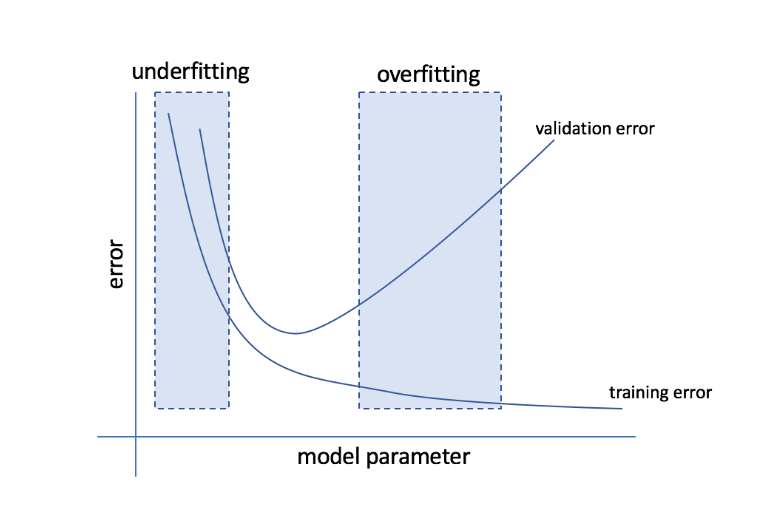
ソース
相互検証:さまざまな検証戦略
検証戦略は、データセットで行われた分割の数に基づいて分類されます。 それでは、Pythonのさまざまな相互検証戦略を見てみましょう。
1.検証セット
この検証アプローチでは、データセットを2つの等しい部分に分割します。データセットの50%は検証用に予約され、残りの50%はモデルトレーニング用に予約されています。 このアプローチでは、特定のデータセットの50%のみに基づいてモデルをトレーニングするため、他の50%のデータに隠されている関連性のある意味のある情報を見逃す可能性が常にあります。 結果として、このアプローチは一般的にモデルに高いバイアスを作成します。
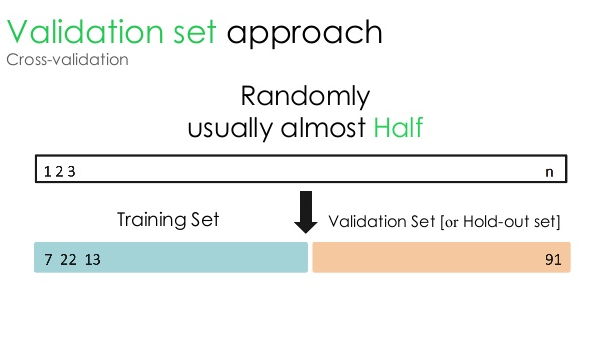
ソース
Pythonコード:
トレイン、検証= train_test_split(data、test_size = 0.50、random_state = 5)
2.トレーニング/テスト分割
この検証アプローチでは、データセットはトレーニングセットとテストセットの2つの部分に分割されます。 これは、トレーニングセットとテストセットの重複を回避するために行われます(トレーニングセットとテストセットが重複している場合、モデルに障害が発生します)。 したがって、モデルに使用されるデータセットに、データセット内に重複するサンプルが含まれていないことを確認することが重要です。 トレーニング/テスト分割戦略を使用すると、モデルのハイパーパラメータを変更することなく、データセット全体に基づいてモデルを再トレーニングできます。

ソース
ただし、このアプローチには1つの重要な制限があります。モデルのパフォーマンスと精度は、モデルの分割方法に大きく依存します。 たとえば、分割がランダムでない場合、またはデータセットの1つのサブセットに完全な情報の一部しかない場合、過剰適合につながります。 このアプローチでは、どのデータポイントがどの検証セットに含まれるかを確認できないため、セットごとに異なる結果が作成されます。 したがって、トレイン/テスト分割戦略は、手元に十分なデータがある場合にのみ使用する必要があります。
Pythonコード:
>>> sklearn.model_selectionimporttrain_test_splitから
>>> X、y = np.arange(10).reshape((5、2))、range(5)
>>> X
配列([[0、1]、
[2、3]、
[4、5]、
[6、7]、
[8、9]])
>>>リスト(y)
[0、1、2、3、4]
3.Kフォールド
前の2つの戦略で見られたように、データセット内の重要な情報を見逃す可能性があり、バイアスによって引き起こされるエラーまたは過剰適合の可能性が高くなります。 これには、モデルトレーニング用に豊富なデータを予約すると同時に、検証用に十分なデータを残す方法が必要です。
Kフォールド検証手法を入力します。 この戦略では、データセットは「k」個のサブセットまたはフォールドに分割されます。ここで、k-1個のサブセットはモデルのトレーニング用に予約され、最後のサブセットは検証(テストセット)に使用されます。 モデルは個々のフォールドに対して平均化され、最終化されます。 モデルが完成したら、テストセットを使用してモデルをテストできます。
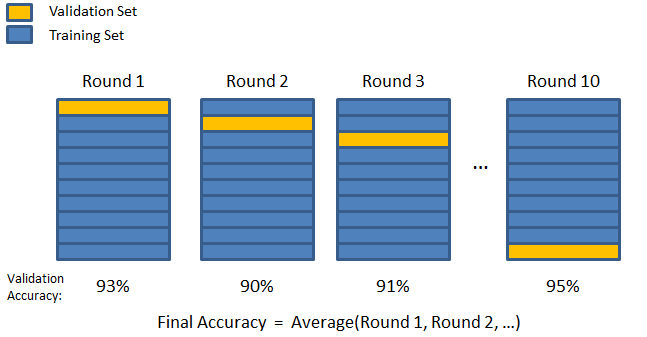

ソース
ここで、各データポイントは、トレーニングセットにk-1回残っている間、検証セットに1回だけ表示されます。 ほとんどのデータはフィッティングに使用されるため、フィッティング不足の問題は大幅に減少します。 同様に、データの大部分が検証セットでも使用されるため、過剰適合の問題は解消されます。
読む: PythonとRuby:完全な並べて比較
Kフォールド戦略は、データ量が限られており、フォールドの品質やフォールド間の最適なパラメーターが大きく異なる場合に最適です。
Pythonコード:
from sklearn.model_selection import KFold#import KFold
X = np.array([[1、2]、[3、4]、[1、2]、[3、4]])#配列を作成します
y = np.array([1、2、3、4])#別の配列を作成します
kf = KFold(n_splits = 2)#分割を定義–2つに分割
kf.get_n_splits(X)#交差検定器での分割反復の数を返します
print(kf)
KFold(n_splits = 2、random_state = None、shuffle = False)
4.1つを除外します
除外交差検定(LOOCV)は、kが特定のデータセット内のサンプル数に等しい場合のKフォールドの特殊なケースです。 ここでは、1つのデータポイントのみがテストセット用に予約されており、残りのデータセットはトレーニングセットです。 したがって、「k-1」オブジェクトをトレーニングサンプルとして使用し、「1」オブジェクトをテストセットとして使用すると、データセット内のすべてのサンプルを繰り返し処理し続けます。 利用可能なデータが少なすぎる場合に最も便利な方法です。
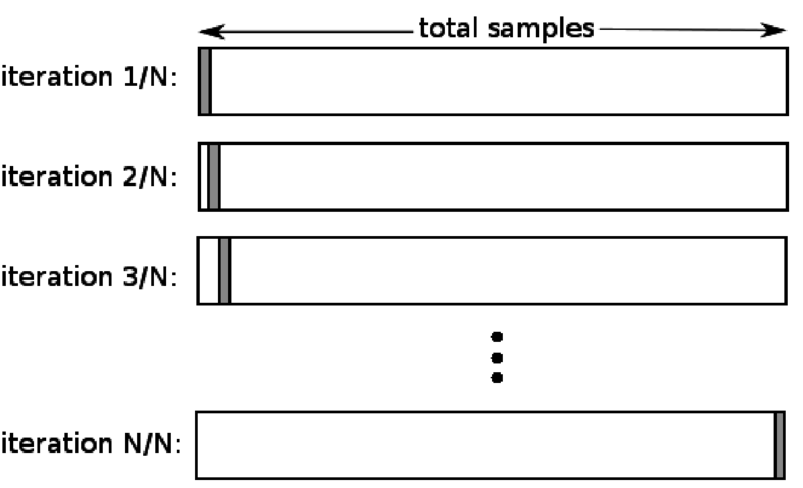
ソース
このアプローチはすべてのデータポイントを使用するため、バイアスは通常低くなります。 ただし、検証プロセスは「n」回繰り返されるため(n =データポイントの数)、実行時間が長くなります。 メソッドのもう1つの注目すべき制約は、1つのデータポイントに対してモデルをテストするときに、モデルの有効性のテストに大きなばらつきが生じる可能性があることです。 したがって、そのデータポイントが外れ値である場合、変動率が高くなります。
Pythonコード:
>>>numpyをnpとしてインポート
>>> sklearn.model_selectionimportLeaveOneOutから
>>> X = np.array([[1、2]、[3、4]])
>>> y = np.array([1、2])
>>> loo = LeaveOneOut()
>>> loo.get_n_splits(X)
2
>>> print(loo)
LeaveOneOut()
>>> loo.split(X)のtrain_index、test_indexの場合:
…print(“ TRAIN:”、train_index、“ TEST:”、test_index)
…X_train、X_test = X [train_index]、X [test_index]
…y_train、y_test = y [train_index]、y [test_index]
…print(X_train、X_test、y_train、y_test)
トレイン:[1]テスト:[0]
[[3 4]] [[1 2]] [2] [1]
トレイン:[0]テスト:[1]
[[1 2]] [[3 4]] [1] [2]
5.階層化
通常、トレイン/テスト分割とKフォールドの場合、データはシャッフルされてランダムなトレーニングと検証の分割が作成されます。 したがって、それは異なるフォールドでの異なるターゲット分布を可能にします。 同様に、階層化により、データを分割しながら、さまざまなフォールドへのターゲットの分散も容易になります。
このプロセスでは、各フォールドが全体を表すように、データがさまざまなフォールドに再配置されます。 したがって、各クラスがデータの50%で構成されるバイナリ分類の問題を扱っている場合は、階層化を使用して、各クラスにインスタンスの半分が含まれるようにデータを配置できます。
階層化プロセスは、マルチクラス分類を使用する小規模で不均衡なデータセットに最適です。
Pythonコード:
sklearn.model_selectionからインポートStratifiedKFold
skf = StratifiedKFold(n_splits = 5、random_state = None)
#Xは機能セットであり、yはターゲットです
skf.split(X、y)のtrain_index、test_indexの場合:
print( "train:"、train_index、 "Validation:"、val_index)
X_train、X_test = X [train_index]、X [val_index]
y_train、y_test = y [train_index]、y [val_index]
読む: Pythonのデータフレーム–チュートリアル
これらの5つの相互検証戦略のそれぞれをいつ使用するのですか?
前に述べたように、各相互検証手法には固有のユースケースがあるため、適切なシナリオに正しく適用すると最高のパフォーマンスを発揮します。 たとえば、十分なデータがあり、さまざまな分割のスコアと(モデルの)最適なパラメーターが類似している可能性が高い場合、トレイン/テスト分割アプローチはうまく機能します。
ただし、分割ごとにスコアと最適なパラメーターが異なる場合は、Kフォールド手法が最適です。 データが少なすぎる場合は、LOOCVアプローチが最適ですが、データセットが小さく不均衡な場合は、階層化が最適です。
この詳細な記事が、Pythonでの相互検証の詳細なアイデアを得るのに役立つことを願っています。
データサイエンスについて知りたい場合は、IIIT-B&upGradのデータサイエンスのエグゼクティブPGプログラムをチェックしてください。これは、働く専門家向けに作成され、10以上のケーススタディとプロジェクト、実践的なハンズオンワークショップ、業界の専門家とのメンターシップを提供します。1業界のメンターとの1対1、400時間以上の学習、トップ企業との仕事の支援。
MLの「順列テスト」とは何ですか?
データセットで検定統計量を生成し、次にそのデータの多くのランダム順列について、順列テストを使用してモデルの統計的有意性を評価します。 モデルが有意である場合、初期検定統計値は帰無仮説分布の裾の1つに分類されます。 p値を見つけるには、最初の検定統計量と同じかそれ以上の検定統計量の数を数え、その数を計算した検定統計量の総数で割る必要があります。 帰無仮説が真であるとすると、P値は、少なくとも検定統計量と同じくらい深刻な結果を得る可能性です。
機械学習における相互検証の欠点は何ですか?
1.相互検証により、トレーニング期間が大幅に長くなります。 以前は、1つのトレーニングセットでのみモデルをトレーニングできました。 これで、相互検証を使用して、いくつかのトレーニングセットでトレーニングできます。
2.ほとんどの場合、調査している構造は、予測モデリングで時間の経過とともに発展します。 その結果、トレーニングセットと検証セットにばらつきがあることに気付く場合があります。
3.相互検証には、多くの計算能力が必要です。
MLモデルの過剰適合を検出するにはどうすればよいですか?
データを評価する前に、過剰適合を検出することはほぼ不可能です。 これは、過剰適合の本質的な機能であるデータセットの一般化の難しさを軽減するのに役立ちます。 その結果、データを個別のサブセットに分割して、トレーニングとテストを容易にすることができます。 両方のデータセットに見られる精度の比率を使用して、過剰適合が存在するかどうかを判断できます。 モデルのパフォーマンスがテストセットよりもトレーニングセットの方が優れている場合は、モデルが過剰適合している可能性があります。
もう1つの提案は、ベースラインとして機能する非常に基本的なMLモデルから始めることです。 後で、複雑なアルゴリズムをテストするときに、追加された複雑さが価値があるかどうかを判断するためのベンチマークがあります。
精度や損失などの検証手段を使用して、過剰適合を検出することもできます。 モデルが過剰適合の影響を受けると、検証手段は通常、停滞するか低下し始めるまで増加します。