
Convalida incrociata in Python: tutto ciò che devi sapere
Pubblicato: 2020-02-14In Data Science, la convalida è probabilmente una delle tecniche più importanti utilizzate dai data scientist per convalidare la stabilità del modello ML e valutare quanto bene si generalizzerebbe ai nuovi dati. La convalida garantisce che il modello ML raccolga i modelli corretti (rilevanti) dal set di dati, eliminando con successo il rumore nel set di dati. In sostanza, l'obiettivo delle tecniche di convalida è assicurarsi che i modelli ML abbiano un basso fattore di varianza di distorsione.
Oggi discuteremo a lungo su una di queste tecniche di convalida del modello: la convalida incrociata.
Sommario
Che cos'è la convalida incrociata?
La convalida incrociata è una tecnica di convalida progettata per valutare e valutare come i risultati dell'analisi statistica (modello) si generalizzeranno a un set di dati indipendente. La convalida incrociata viene utilizzata principalmente in scenari in cui la previsione è l'obiettivo principale e l'utente desidera stimare quanto bene e accuratamente un modello predittivo funzionerà in situazioni del mondo reale.
La convalida incrociata cerca di definire un set di dati testando il modello nella fase di addestramento per ridurre al minimo problemi come overfitting e underfitting. Bisogna però ricordare che sia la validazione che il training set devono essere estratti dalla stessa distribuzione, altrimenti si avrebbero problemi in fase di validazione.
Impara il corso di certificazione della scienza dei dati dalle migliori università del mondo. Guadagna programmi Executive PG, programmi di certificazione avanzati o programmi di master per accelerare la tua carriera.
Vantaggi della convalida incrociata
- Aiuta a valutare la qualità del tuo modello.
- Aiuta a ridurre/evitare problemi di overfitting e underfitting.
- Ti consente di selezionare il modello che fornirà le migliori prestazioni su dati invisibili.
Leggi: Progetti Python per principianti
Cosa sono Overfitting e Underfitting?
L'overfitting si riferisce alla condizione in cui un modello diventa troppo sensibile ai dati e finisce per acquisire molto rumore e schemi casuali che non si generalizzano bene ai dati invisibili. Mentre un tale modello di solito si comporta bene sul set di allenamento, le sue prestazioni ne risentono sul set di prova.
L'underfitting si riferisce al problema quando il modello non riesce a catturare un numero sufficiente di modelli nel set di dati, offrendo così prestazioni scadenti sia per l'addestramento che per il set di test.
Passando da queste due estremità, il modello perfetto è quello che si comporta ugualmente bene sia per l'allenamento che per i set di prova.
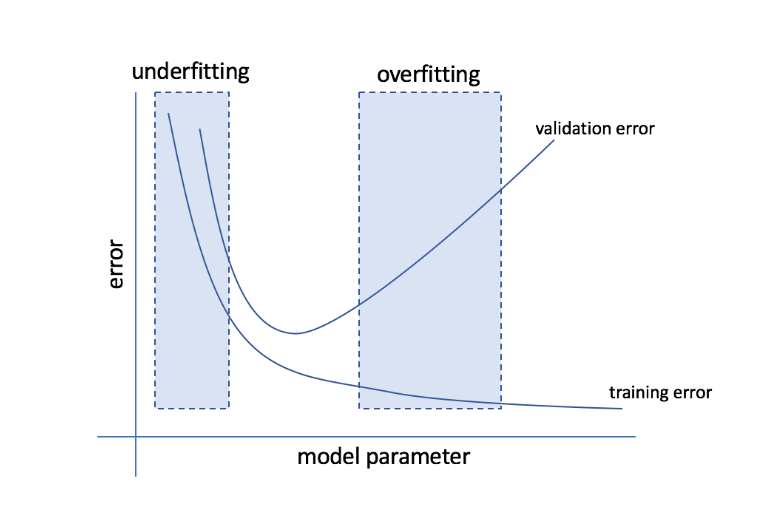
Fonte
Convalida incrociata: diverse strategie di convalida
Le strategie di convalida sono classificate in base al numero di suddivisioni eseguite in un set di dati. Ora, diamo un'occhiata alle diverse strategie di convalida incrociata in Python.
1. Set di convalida
Questo approccio di convalida divide il set di dati in due parti uguali: mentre il 50% del set di dati è riservato alla convalida, il restante 50% è riservato all'addestramento del modello. Poiché questo approccio addestra il modello in base solo al 50% di un determinato set di dati, rimane sempre la possibilità di perdere informazioni rilevanti e significative nascoste nell'altro 50% dei dati. Di conseguenza, questo approccio generalmente crea una maggiore distorsione nel modello.
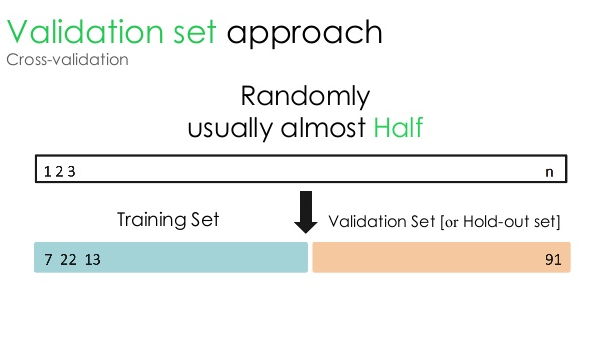
Fonte
Codice Python:
train, validation = train_test_split(data, test_size=0.50, random_state = 5)
2. Divisione treno/prova
In questo approccio di convalida, il set di dati è suddiviso in due parti: set di addestramento e set di test. Questo viene fatto per evitare qualsiasi sovrapposizione tra il set di allenamento e il set di test (se il set di allenamento e il set di test si sovrappongono, il modello sarà difettoso). Pertanto, è fondamentale garantire che il set di dati utilizzato per il modello non contenga campioni duplicati nel nostro set di dati. La strategia di suddivisione treno/test consente di riqualificare il modello in base all'intero set di dati senza alterare alcun iperparametro del modello.

Fonte
Tuttavia, questo approccio ha una limitazione significativa: le prestazioni e l'accuratezza del modello dipendono in gran parte da come è suddiviso. Ad esempio, se la divisione non è casuale o un sottoinsieme del set di dati contiene solo una parte delle informazioni complete, si verificherà un overfitting. Con questo approccio, non è possibile essere sicuri di quali punti dati si troveranno in quale set di convalida, creando così risultati diversi per set diversi. Pertanto, la strategia di suddivisione treno/test dovrebbe essere utilizzata solo quando si dispone di dati sufficienti.
Codice Python:
>>> da sklearn.model_selection import train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> X
matrice([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> elenco(i)
[0, 1, 2, 3, 4]
3. Piega a K
Come visto nelle due strategie precedenti, esiste la possibilità di perdere informazioni importanti nel set di dati, il che aumenta la probabilità di errore indotto da bias o overfitting. Ciò richiede un metodo che riserva dati abbondanti per l'addestramento del modello lasciando al contempo dati sufficienti per la convalida.
Immettere la tecnica di convalida K-fold. In questa strategia, il set di dati è suddiviso in un numero "k" di sottoinsiemi o pieghe, in cui i sottoinsiemi k-1 sono riservati per l'addestramento del modello e l'ultimo sottoinsieme viene utilizzato per la convalida (set di test). Il modello viene mediato rispetto alle singole pieghe e quindi finalizzato. Una volta finalizzato il modello, puoi testarlo utilizzando il set di test.
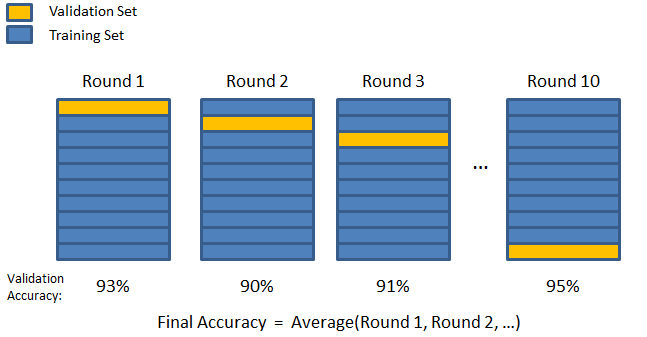
Fonte
Qui, ogni punto dati appare nel set di validazione esattamente una volta rimanendo nel set di addestramento k-1 numero di volte. Poiché la maggior parte dei dati viene utilizzata per l'adattamento, il problema dell'underfitting si riduce notevolmente. Allo stesso modo, il problema dell'overfitting viene eliminato poiché la maggior parte dei dati viene utilizzata anche nel set di convalida.

Leggi: Python vs Ruby: confronto completo fianco a fianco
La strategia K-fold è la migliore per i casi in cui hai una quantità limitata di dati e c'è una differenza sostanziale nella qualità delle pieghe o diversi parametri ottimali tra di loro.
Codice Python:
da sklearn.model_selection import KFold # import KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # crea un array
y = np.array([1, 2, 3, 4]) # Crea un altro array
kf = KFold(n_splits=2) # Definisce la divisione – in 2 pieghe
kf.get_n_splits(X) # restituisce il numero di iterazioni di divisione nel validatore incrociato
stampa (kf)
KFold(n_splits=2, random_state=Nessuno, shuffle=False)
4. Lasciane fuori uno
La convalida incrociata leave one out (LOOCV) è un caso speciale di K-fold quando k è uguale al numero di campioni in un particolare set di dati. Qui, solo un punto dati è riservato al set di test e il resto del set di dati è il set di addestramento. Pertanto, se si utilizza l'oggetto "k-1" come campioni di addestramento e l'oggetto "1" come set di test, continueranno a scorrere ogni campione nel set di dati. È il metodo più utile quando i dati disponibili sono insufficienti.
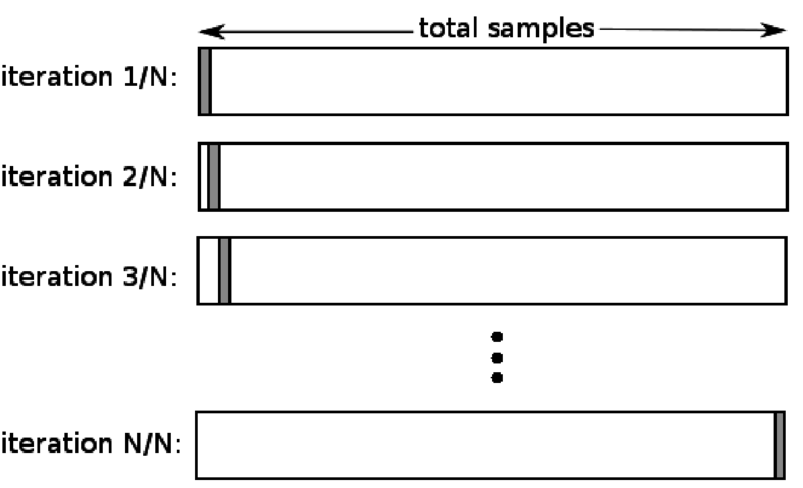
Fonte
Poiché questo approccio utilizza tutti i punti dati, la distorsione è generalmente bassa. Tuttavia, poiché il processo di convalida viene ripetuto un numero 'n' di volte (n=numero di punti dati), porta a un tempo di esecuzione maggiore. Un altro vincolo notevole dei metodi è che può portare a una variazione maggiore nell'efficacia del modello di test quando si testa il modello rispetto a un punto dati. Quindi, se quel punto dati è un valore anomalo, creerà un quoziente di variazione più elevato.
Codice Python:
>>> importa numpy come np
>>> da sklearn.model_selection import LeaveOneOut
>>> X = np.array([[1, 2], [3, 4]])
>>> y = np.array([1, 2])
>>> loo = LeaveOneOut()
>>> loo.get_n_splits(X)
2
>>> stampa (loo)
Lascia uno fuori ()
>>> per train_index, test_index in loo.split(X):
… print(“TRAIN:”, train_index, “TEST:”, test_index)
… X_train, X_test = X[train_index], X[test_index]
… y_train, y_test = y[train_index], y[test_index]
… print(X_treno, X_test, y_train, y_test)
TRENO: [1] PROVA: [0]
[[3 4]] [[1 2]] [2] [1]
TRENO: [0] PROVA: [1]
[[1 2]] [[3 4]] [1] [2]
5. Stratificazione
In genere, per la suddivisione treno/test e K-fold, i dati vengono mescolati per creare una suddivisione casuale di addestramento e convalida. Pertanto, consente una diversa distribuzione del target in diverse pieghe. Allo stesso modo, la stratificazione facilita anche la distribuzione del target su diverse pieghe mentre suddivide i dati.
In questo processo, i dati vengono riorganizzati in diverse pieghe in modo da garantire che ciascuna piega diventi un rappresentante dell'insieme. Quindi, se hai a che fare con un problema di classificazione binaria in cui ogni classe è composta dal 50% dei dati, puoi utilizzare la stratificazione per organizzare i dati in modo che ogni classe includa metà delle istanze.
Il processo di stratificazione è più adatto per set di dati piccoli e sbilanciati con classificazione multiclasse.
Codice Python:
da sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, random_state=Nessuno)
# X è il set di funzionalità e y è l'obiettivo
per train_index, test_index in skf.split(X,y):
print(“Train:”, train_index, “Convalida:”, val_index)
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[train_index], y[val_index]
Leggi: Frame di dati in Python – Tutorial
Quando utilizzare ciascuna di queste cinque strategie di convalida incrociata?
Come accennato in precedenza, ogni tecnica di convalida incrociata ha casi d'uso unici e, quindi, funzionano meglio se applicata correttamente agli scenari corretti. Ad esempio, se si dispone di dati sufficienti ed è probabile che i punteggi e i parametri ottimali (del modello) per le diverse divisioni siano simili, l'approccio della divisione treno/test funzionerà in modo eccellente.
Tuttavia, se i punteggi e i parametri ottimali variano per le diverse divisioni, la tecnica K-fold sarà la migliore. Per i casi in cui hai pochi dati, l'approccio LOOCV funziona meglio, mentre, per set di dati piccoli e sbilanciati, la stratificazione è la strada da percorrere.
Ci auguriamo che questo articolo dettagliato ti abbia aiutato a farti un'idea approfondita della convalida incrociata in Python.
Se sei curioso di conoscere la scienza dei dati, dai un'occhiata al programma Executive PG in Data Science di IIIT-B e upGrad, creato per i professionisti che lavorano e offre oltre 10 casi di studio e progetti, workshop pratici pratici, tutoraggio con esperti del settore, 1 -on-1 con mentori del settore, oltre 400 ore di apprendimento e assistenza al lavoro con le migliori aziende.
Che cos'è il "test di permutazione" in ML?
Generando una statistica di test sul set di dati e quindi per molte permutazioni casuali di tali dati, viene utilizzato un test di permutazione per valutare la significatività statistica di un modello. Il valore della statistica test iniziale dovrebbe rientrare in una delle code della distribuzione dell'ipotesi nulla se il modello è significativo. Per trovare il valore p, devi semplicemente contare il numero di statistiche di test che sono gravi quanto o più estreme delle statistiche di test iniziali e quindi dividere quel numero per il numero totale di statistiche di test che abbiamo calcolato. Dato che l'ipotesi nulla è vera, il valore P è la possibilità di ottenere un risultato almeno grave quanto la statistica del test.
Quali sono gli svantaggi della convalida incrociata nell'apprendimento automatico?
1. La convalida incrociata allunga notevolmente il periodo di formazione. In precedenza, potevi addestrare il tuo modello solo su un set di allenamento; ora puoi addestrarlo su diversi set di allenamento utilizzando la convalida incrociata.
2. Nella maggior parte dei casi, la struttura che stai studiando si sviluppa nel tempo nella modellazione predittiva. Di conseguenza, potresti notare variazioni nei set di addestramento e convalida.
3. La convalida incrociata richiede molta potenza di calcolo.
Come posso rilevare l'overfitting nei modelli ML?
Prima di valutare i dati, è quasi impossibile rilevare l'overfitting. Può aiutare con la difficoltà di generalizzare i set di dati, che è una caratteristica intrinseca dell'overfitting. Di conseguenza, i dati possono essere suddivisi in sottoinsiemi distinti per semplificare l'addestramento e il test. La proporzione di accuratezza osservata in entrambi i set di dati può essere utilizzata per determinare se è presente o meno un overfitting. Se il modello ha prestazioni migliori sul set di allenamento rispetto al set di prova, è probabile che sia overfitting.
Un altro suggerimento è di iniziare con un modello ML molto semplice che funga da linea di base. Successivamente, quando testerai algoritmi complessi, avrai un benchmark rispetto al quale giudicare se vale la pena aggiungere complessità.
Le misure di convalida come l'accuratezza e la perdita possono essere utilizzate anche per rilevare l'overfitting. Quando il modello è influenzato dall'overfitting, le misure di convalida generalmente crescono fino a stabilizzarsi o iniziano a diminuire.