
Перекрестная проверка в Python: все, что вам нужно знать о
Опубликовано: 2020-02-14В науке о данных проверка, вероятно, является одним из наиболее важных методов, используемых специалистами по данным для проверки стабильности модели машинного обучения и оценки того, насколько хорошо она будет обобщаться на новые данные. Проверка гарантирует, что модель машинного обучения выбирает правильные (соответствующие) шаблоны из набора данных, успешно устраняя шум в наборе данных. По сути, цель методов проверки состоит в том, чтобы убедиться, что модели ML имеют низкий коэффициент дисперсии смещения.
Сегодня мы подробно обсудим один из таких методов проверки модели — перекрестную проверку.
Оглавление
Что такое перекрестная проверка?
Перекрестная проверка — это метод проверки, предназначенный для оценки того, как результаты статистического анализа (модели) будут обобщены на независимый набор данных. Перекрестная проверка в основном используется в сценариях, где прогнозирование является основной целью, и пользователь хочет оценить, насколько хорошо и точно прогностическая модель будет работать в реальных ситуациях.
Перекрестная проверка направлена на определение набора данных путем тестирования модели на этапе обучения, чтобы свести к минимуму такие проблемы, как переоснащение и недообучение. Однако вы должны помнить, что и проверочный, и обучающий наборы должны быть извлечены из одного и того же дистрибутива, иначе это может привести к проблемам на этапе проверки.
Пройдите сертификационный курс по науке о данных в лучших университетах мира. Участвуйте в программах Executive PG, Advanced Certificate Programs или Master Programs, чтобы ускорить свою карьеру.
Преимущества перекрестной проверки
- Это помогает оценить качество вашей модели.
- Это помогает уменьшить / избежать проблем переобучения и недообучения.
- Он позволяет выбрать модель, которая обеспечит наилучшую производительность для невидимых данных.
Читайте: Проекты Python для начинающих
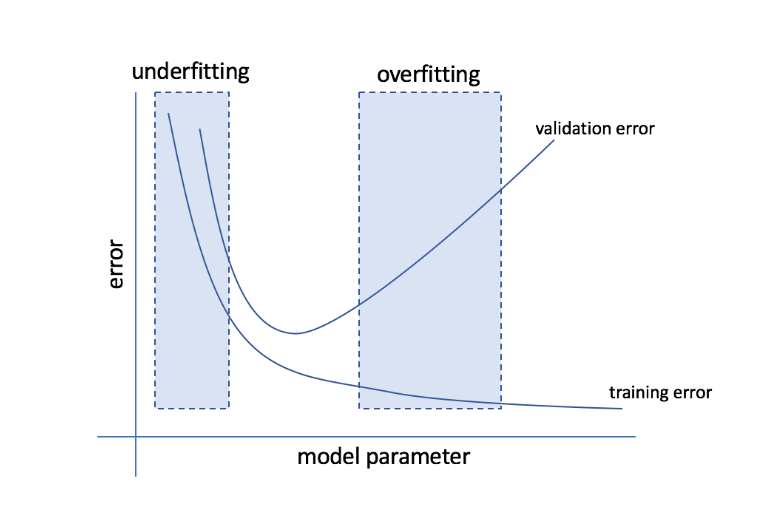
Что такое переобучение и недообучивание?
Переобучение относится к состоянию, когда модель становится слишком чувствительной к данным и в конечном итоге фиксирует много шума и случайных паттернов, которые плохо обобщаются на невидимые данные. Хотя такая модель обычно хорошо работает на тренировочном наборе, ее производительность страдает на тестовом наборе.
Недостаточное приспособление относится к проблеме, когда модель не может зафиксировать достаточное количество шаблонов в наборе данных, что приводит к низкой производительности как для обучения, так и для тестового набора.
Исходя из этих двух крайностей, идеальной моделью является та, которая одинаково хорошо работает как для обучающих, так и для тестовых наборов.
Источник
Перекрестная проверка: различные стратегии проверки
Стратегии проверки классифицируются на основе количества расщеплений, выполненных в наборе данных. Теперь давайте рассмотрим различные стратегии перекрестной проверки в Python.
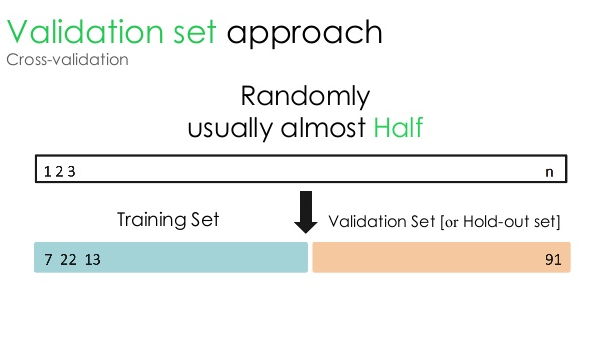
1. Набор для проверки
Этот подход к проверке делит набор данных на две равные части: 50% набора данных зарезервировано для проверки, а остальные 50% зарезервированы для обучения модели. Поскольку при таком подходе модель обучается только на 50 % данного набора данных, всегда остается возможность упустить важную и значимую информацию, скрытую в остальных 50 % данных. В результате такой подход обычно приводит к более высокому смещению модели.
Источник
Код Python:
поезд, проверка = train_test_split (данные, test_size = 0,50, random_state = 5)
2. Сплит «Тренировка/Тест»
В этом подходе к проверке набор данных разделен на две части — обучающий набор и тестовый набор. Это делается для того, чтобы избежать перекрытия между обучающим набором и тестовым набором (если обучающий и тестовый наборы перекрываются, модель будет ошибочной). Таким образом, крайне важно убедиться, что набор данных, используемый для модели, не должен содержать дублирующих выборок в нашем наборе данных. Стратегия разделения обучения/тестирования позволяет переобучить модель на основе всего набора данных без изменения каких-либо гиперпараметров модели.

Источник
Однако у этого подхода есть одно существенное ограничение — производительность и точность модели во многом зависят от того, как она разбита. Например, если разделение не является случайным или одно подмножество набора данных содержит только часть полной информации, это приведет к переоснащению. При таком подходе вы не можете быть уверены, какие точки данных будут в каком наборе проверки, тем самым создавая разные результаты для разных наборов. Следовательно, стратегию разделения обучения/тестирования следует использовать только тогда, когда у вас достаточно данных.
Код Python:
>>> из sklearn.model_selection импорта train_test_split
>>> X, y = np.arange(10).reshape((5, 2)), range(5)
>>> Х
массив([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> список(у)
[0, 1, 2, 3, 4]
3. К-кратный
Как видно из предыдущих двух стратегий, существует возможность упустить важную информацию в наборе данных, что увеличивает вероятность ошибки или переобучения, вызванной предвзятостью. Это требует метода, который резервирует большое количество данных для обучения модели, а также оставляет достаточно данных для проверки.
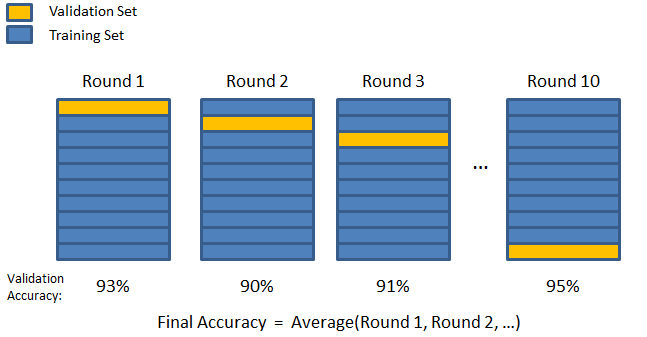
Введите метод проверки K-fold. В этой стратегии набор данных разбивается на «k» подмножеств или сгибов, где k-1 подмножеств зарезервированы для обучения модели, а последнее подмножество используется для проверки (тестовый набор). Модель усредняется по отдельным складкам, а затем дорабатывается. Как только модель будет завершена, вы можете протестировать ее с помощью тестового набора.
Источник
Здесь каждая точка данных появляется в проверочном наборе ровно один раз, оставаясь в обучающем наборе k-1 раз. Поскольку большая часть данных используется для подбора, проблема недообучения значительно уменьшается. Точно так же устраняется проблема переобучения, поскольку большая часть данных также используется в наборе проверки.

Читайте: Python против Ruby: полное параллельное сравнение
Стратегия K-fold лучше всего подходит для случаев, когда у вас ограниченный объем данных, и существует существенная разница в качестве кратности или различных оптимальных параметрах между ними.
Код Python:
from sklearn.model_selection import KFold # импорт KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # создаем массив
y = np.array([1, 2, 3, 4]) # Создаем еще один массив
kf = KFold(n_splits=2) # Определяем разделение – на 2 сгиба
kf.get_n_splits(X) # возвращает количество итераций разделения в кросс-валидаторе
печать (кф)
KFold (n_splits = 2, random_state = None, shuffle = False)
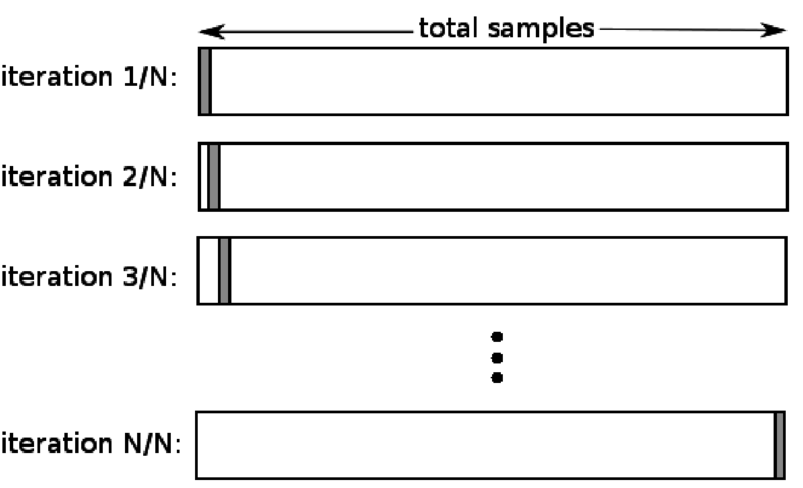
4. Оставьте один
Перекрестная проверка с исключением одного (LOOCV) является частным случаем K-кратности, когда k равно количеству выборок в конкретном наборе данных. Здесь только одна точка данных зарезервирована для тестового набора, а остальная часть набора данных является обучающим набором. Таким образом, если вы используете объект «k-1» в качестве обучающей выборки и объект «1» в качестве тестового набора, они будут продолжать повторять каждую выборку в наборе данных. Это самый полезный метод, когда данных слишком мало.
Источник
Поскольку в этом подходе используются все точки данных, систематическая ошибка обычно невелика. Однако, поскольку процесс проверки повторяется «n» раз (n = количество точек данных), это приводит к увеличению времени выполнения. Еще одно заметное ограничение методов заключается в том, что это может привести к большему разбросу в эффективности модели тестирования, когда вы тестируете модель по одной точке данных. Таким образом, если эта точка данных является выбросом, она создаст более высокий коэффициент вариации.
Код Python:
>>> импортировать numpy как np
>>> из sklearn.model_selection импортировать LeaveOneOut
>>> X = np.array([[1, 2], [3, 4]])
>>> у = np.массив ([1, 2])
>>> loo = LeaveOneOut()
>>> loo.get_n_splits(X)
2
>>> печатать (туалет)
Выйти из одного()
>>> для train_index, test_index в loo.split(X):
… распечатать («ПОЕЗД:», train_index, «ТЕСТ:», test_index)
… X_train, X_test = X[train_index], X[test_index]
… y_train, y_test = y[train_index], y[test_index]
… распечатать (X_train, X_test, y_train, y_test)
ПОЕЗД: [1] ТЕСТ: [0]
[[3 4]] [[1 2]] [2] [1]
ПОЕЗД: [0] ТЕСТ: [1]
[[1 2]] [[3 4]] [1] [2]
5. Стратификация
Как правило, для разделения обучения/тестирования и K-fold данные перемешиваются для создания случайного разделения обучения и проверки. Таким образом, он допускает различное целевое распределение в разных складках. Точно так же стратификация также облегчает целевое распределение по разным складкам при разделении данных.
В этом процессе данные перераспределяются по разным сгибам таким образом, чтобы каждый сгиб отражал целое. Итак, если вы имеете дело с проблемой бинарной классификации, где каждый класс состоит из 50% данных, вы можете использовать стратификацию, чтобы упорядочить данные таким образом, чтобы каждый класс включал половину экземпляров.
Процесс стратификации лучше всего подходит для небольших и несбалансированных наборов данных с мультиклассовой классификацией.
Код Python:
из sklearn.model_selection импорт StratifiedKFold
skf = StratifiedKFold (n_splits = 5, random_state = None)
# X — это набор функций, а y — цель
для train_index, test_index в skf.split(X,y):
print("Поезд:", train_index, "Проверка:", val_index)
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[train_index], y[val_index]
Читать: Фреймы данных в Python — учебник
Когда использовать каждую из этих пяти стратегий перекрестной проверки?
Как мы упоминали ранее, каждый метод перекрестной проверки имеет уникальные варианты использования, и, следовательно, они работают лучше всего при правильном применении в правильных сценариях. Например, если у вас достаточно данных, а оценки и оптимальные параметры (модели) для разных расщеплений, вероятно, будут одинаковыми, подход разделения обучения/тестирования будет работать превосходно.
Однако, если оценки и оптимальные параметры различаются для разных расщеплений, метод K-fold будет лучшим. В случаях, когда у вас слишком мало данных, подход LOOCV работает лучше всего, тогда как для небольших и несбалансированных наборов данных лучше всего подходит стратификация.
Мы надеемся, что эта подробная статья помогла вам получить более глубокое представление о перекрестной проверке в Python.
Если вам интересно узнать о науке о данных, ознакомьтесь с программой IIIT-B & upGrad Executive PG по науке о данных, которая создана для работающих профессионалов и предлагает более 10 тематических исследований и проектов, практические семинары, наставничество с отраслевыми экспертами, 1 -на-1 с отраслевыми наставниками, более 400 часов обучения и помощи в трудоустройстве в ведущих фирмах.
Что такое «перестановочный тест» в ML?
Создавая тестовую статистику для набора данных, а затем для многих случайных перестановок этих данных, тест перестановок используется для оценки статистической значимости модели. Начальное статистическое значение теста должно попасть в один из хвостов распределения нулевой гипотезы, если модель значима. Чтобы найти p-значение, вам нужно просто подсчитать количество тестовых статистических данных, которые являются такими же серьезными, как и более экстремальные, чем исходные тестовые статистические данные, а затем разделить это число на общее количество тестовых статистических данных, которые мы вычислили. Учитывая, что нулевая гипотеза верна, P-значение — это шанс получить результат, по крайней мере столь же серьезный, как и статистика теста.
Каковы недостатки перекрестной проверки в машинном обучении?
1. Перекрестная проверка значительно удлиняет период обучения. Раньше вы могли тренировать свою модель только на одном тренировочном наборе; теперь вы можете обучить его на нескольких обучающих наборах с помощью перекрестной проверки.
2. В большинстве случаев структура, которую вы изучаете, со временем развивается в прогнозном моделировании. В результате вы можете заметить различия в наборах для обучения и проверки.
3. Перекрестная проверка требует большой вычислительной мощности.
Как я могу обнаружить переобучение в моделях ML?
До того, как вы оцените данные, обнаружить переоснащение практически невозможно. Это может помочь с трудностью обобщения наборов данных, которая является неотъемлемой чертой переобучения. В результате данные могут быть разделены на отдельные подмножества, чтобы упростить обучение и тестирование. Доля точности, наблюдаемая в обоих наборах данных, может использоваться для определения наличия или отсутствия переобучения. Если модель работает лучше на тренировочном наборе, чем на тестовом, есть вероятность, что она переобучена.
Еще одно предложение — начать с очень простой модели машинного обучения, которая будет служить основой. Позже, когда вы будете тестировать сложные алгоритмы, у вас будет эталон, по которому можно судить, стоит ли добавленная сложность.
Меры проверки, такие как точность и потери, также могут использоваться для обнаружения переобучения. Когда на модель влияет переоснащение, показатели проверки обычно растут до тех пор, пока они не стабилизируются или не начнут снижаться.