
Walidacja krzyżowa w Pythonie: wszystko, co musisz wiedzieć
Opublikowany: 2020-02-14W Data Science walidacja jest prawdopodobnie jedną z najważniejszych technik stosowanych przez Data Scientists do walidacji stabilności modelu ML i oceny, jak dobrze uogólniałby się on na nowe dane. Walidacja zapewnia, że model ML odbierze właściwe (odpowiednie) wzorce z zestawu danych, jednocześnie skutecznie eliminując szum w zestawie danych. Zasadniczo celem technik walidacji jest upewnienie się, że modele ML mają niski współczynnik odchylenia.
Dzisiaj omówimy szczegółowo jedną z takich technik walidacji modelu – walidację krzyżową.
Spis treści
Co to jest walidacja krzyżowa?
Cross-Validation to technika walidacji zaprojektowana do oceny i oceny, w jaki sposób wyniki analizy statystycznej (modelu) zostaną uogólnione na niezależny zestaw danych. Walidacja krzyżowa jest używana głównie w scenariuszach, w których przewidywanie jest głównym celem, a użytkownik chce oszacować, jak dobrze i dokładnie model predykcyjny będzie działał w rzeczywistych sytuacjach.
Cross-Validation ma na celu zdefiniowanie zestawu danych, testując model w fazie uczenia, aby pomóc zminimalizować problemy, takie jak nadmierne i niedostateczne dopasowanie. Należy jednak pamiętać, że zarówno zestaw walidacyjny, jak i treningowy muszą być wydobyte z tej samej dystrybucji, w przeciwnym razie doprowadziłoby to do problemów w fazie walidacji.
Zapoznaj się z kursem certyfikacyjnym z zakresu nauki o danych z najlepszych uniwersytetów na świecie. Zdobywaj programy Executive PG, Advanced Certificate Programs lub Masters Programs, aby przyspieszyć swoją karierę.
Korzyści z walidacji krzyżowej
- Pomaga ocenić jakość Twojego modelu.
- Przyczynia się do zmniejszenia/uniknięcia problemów z overfittingiem i underfittingiem.
- Pozwala wybrać model, który zapewni najlepszą wydajność na niewidocznych danych.
Przeczytaj: Projekty Pythona dla początkujących
Czym są nadmierne i niedostateczne dopasowanie?
Nadmierne dopasowanie odnosi się do stanu, w którym model staje się zbyt wrażliwy na dane i kończy się wychwytywaniem dużej ilości szumu i losowych wzorców, które nie uogólniają dobrze na niewidoczne dane. Podczas gdy taki model zwykle działa dobrze na zbiorze uczącym, jego wydajność spada na zbiorze testowym.
Niedopasowanie odnosi się do problemu, gdy model nie wychwytuje wystarczającej liczby wzorców w zbiorze danych, zapewniając w ten sposób słabą wydajność zarówno w przypadku uczenia, jak i zestawu testowego.
Idąc przez te dwie skrajności, idealny model to taki, który sprawdza się równie dobrze zarówno w przypadku zestawów treningowych, jak i testowych.
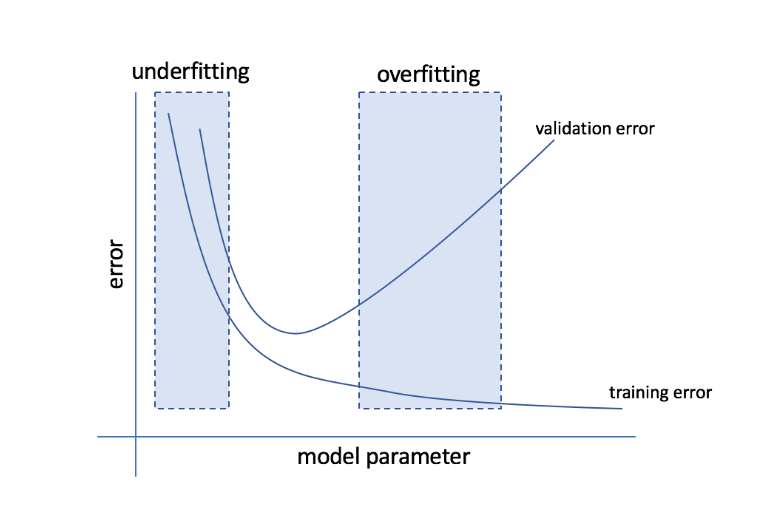
Źródło
Walidacja krzyżowa: różne strategie walidacji
Strategie walidacji są kategoryzowane na podstawie liczby podziałów wykonanych w zbiorze danych. Przyjrzyjmy się teraz różnym strategiom walidacji krzyżowej w Pythonie.
1. Zestaw walidacyjny
To podejście do walidacji dzieli zbiór danych na dwie równe części — podczas gdy 50% zbioru danych jest zarezerwowane do walidacji, pozostałe 50% jest zarezerwowane do trenowania modelu. Ponieważ to podejście szkoli model w oparciu o tylko 50% danego zestawu danych, zawsze istnieje możliwość pominięcia istotnych i znaczących informacji ukrytych w pozostałych 50% danych. W rezultacie takie podejście generalnie prowadzi do większego odchylenia w modelu.
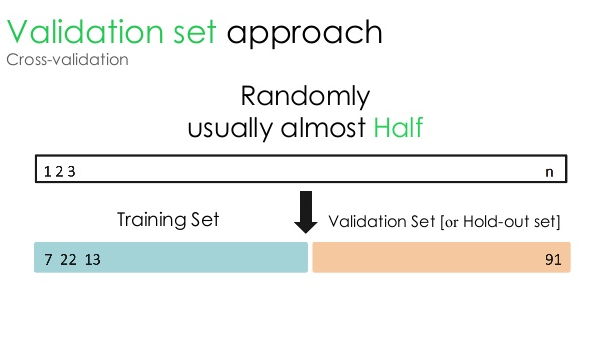
Źródło
Kod w Pythonie:
pociąg, walidacja = train_test_split(dane, test_size=0.50, random_state = 5)
2. Podział pociągu/testu
W tym podejściu do walidacji zbiór danych jest podzielony na dwie części – zbiór uczący i zbiór testowy. Ma to na celu uniknięcie nakładania się zestawu uczącego i zestawu testowego (jeśli zestawy uczące i testowe nakładają się, model będzie wadliwy). Dlatego ważne jest, aby upewnić się, że zestaw danych używany w modelu nie może zawierać żadnych zduplikowanych próbek w naszym zestawie danych. Strategia podziału trenowania/testowania umożliwia ponowne trenowanie modelu na podstawie całego zestawu danych bez zmiany jakichkolwiek hiperparametrów modelu.

Źródło
Podejście to ma jednak jedno istotne ograniczenie – wydajność i dokładność modelu w dużej mierze zależą od tego, w jaki sposób jest on dzielony. Na przykład, jeśli podział nie jest losowy lub jeden podzbiór zestawu danych zawiera tylko część pełnych informacji, doprowadzi to do nadmiernego dopasowania. Dzięki takiemu podejściu nie można być pewnym, które punkty danych będą się znajdować w jakim zestawie walidacyjnym, tworząc w ten sposób różne wyniki dla różnych zestawów. Dlatego strategia podziału pociąg/próba powinna być używana tylko wtedy, gdy masz pod ręką wystarczającą ilość danych.
Kod w Pythonie:
>>> ze sklearn.model_selection importuj train_test_split
>>> X, y = np.arange(10).reshape((5,2)), range(5)
>>> X
tablica ([[0, 1],
[2, 3],
[4, 5],
[6, 7],
[8, 9]])
>>> lista(y)
[0, 1, 2, 3, 4]
3. Składanie na K
Jak widać w poprzednich dwóch strategiach, istnieje możliwość pominięcia ważnych informacji w zbiorze danych, co zwiększa prawdopodobieństwo błędu spowodowanego uprzedzeniami lub nadmiernego dopasowania. Wymaga to metody, która rezerwuje obfite dane do trenowania modelu, pozostawiając jednocześnie wystarczającą ilość danych do walidacji.
Wprowadź technikę walidacji K-fold. W tej strategii zbiór danych jest podzielony na liczbę „k” podzbiorów lub fałd, przy czym podzbiory k-1 są zarezerwowane do uczenia modelu, a ostatni podzbiór jest używany do walidacji (zestaw testowy). Model jest uśredniany względem poszczególnych fałd, a następnie finalizowany. Po sfinalizowaniu modelu możesz go przetestować za pomocą zestawu testowego.
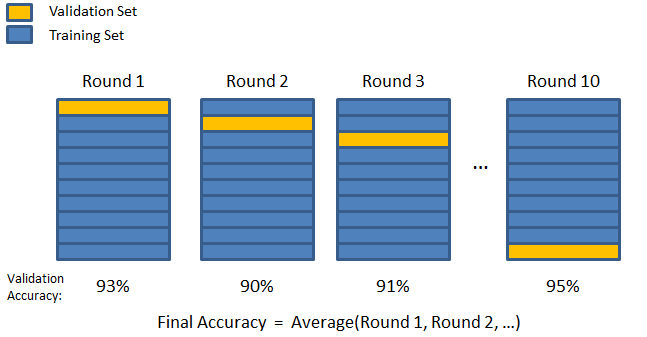
Źródło
Tutaj każdy punkt danych pojawia się w zbiorze walidacyjnym dokładnie raz, pozostając w zbiorze uczącym liczbę razy k-1. Ponieważ większość danych jest wykorzystywana do dopasowania, problem niedopasowania znacznie się zmniejsza. Podobnie wyeliminowany zostaje problem nadmiernego dopasowania, ponieważ większość danych jest również wykorzystywana w zestawie walidacyjnym.

Przeczytaj: Python vs Ruby: Pełne porównanie side-by-side
Strategia K-fold jest najlepsza w przypadkach, w których masz ograniczoną ilość danych i istnieje znaczna różnica w jakości fałd lub różnych optymalnych parametrów między nimi.
Kod w Pythonie:
ze sklearn.model_selection importuj KFold # importuj KFold
X = np.array([[1, 2], [3, 4], [1, 2], [3, 4]]) # utwórz tablicę
y = np.array([1, 2, 3, 4]) # Utwórz kolejną tablicę
kf = KFold(n_splits=2) # Zdefiniuj podział – na 2 fałdy
kf.get_n_splits(X) # zwraca liczbę iteracji dzielenia w walidatorze krzyżowym
drukuj (kf)
KFold(n_splits=2, random_state=Brak, shuffle=Fałsz)
4. Zostaw jeden poza
Pomiń jedno z walidacji krzyżowej (LOOCV) to szczególny przypadek K-krotności, gdy k jest równe liczbie próbek w określonym zbiorze danych. Tutaj tylko jeden punkt danych jest zarezerwowany dla zestawu testowego, a reszta zestawu danych to zestaw uczący. Tak więc, jeśli użyjesz obiektu „k-1” jako próbek uczących i obiektu „1” jako zestawu testowego, będą one kontynuowały iterację przez każdą próbkę w zestawie danych. Jest to najbardziej przydatna metoda, gdy dostępnych jest zbyt mało danych.
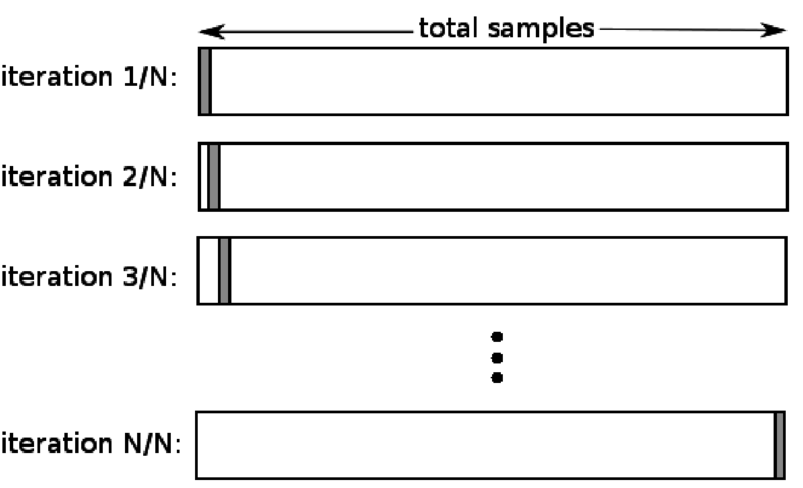
Źródło
Ponieważ to podejście wykorzystuje wszystkie punkty danych, odchylenie jest zwykle niskie. Jednak ponieważ proces walidacji jest powtarzany „n” razy (n=liczba punktów danych), prowadzi to do dłuższego czasu wykonania. Innym godnym uwagi ograniczeniem metod jest to, że może to prowadzić do większej zmienności w testowaniu skuteczności modelu podczas testowania modelu względem jednego punktu danych. Tak więc, jeśli ten punkt danych jest wartością odstającą, utworzy wyższy iloraz zmienności.
Kod w Pythonie:
>>> importuj numpy jako np
>>> ze sklearn.model_selection import LeaveOneOut
>>> X = np. tablica([[1, 2], [3, 4]])
>>> y = np. tablica([1, 2])
>>> loo = LeaveOneOut()
>>> loo.get_n_splits(X)
2
>>> drukuj(loo)
PozostawJedenWyjście()
>>> dla train_index, test_index w loo.split(X):
… print("TRAIN:", train_index, "TEST:", test_index)
… X_train, X_test = X[indeks_pociągu], X[indeks_testu]
… y_pociąg, y_test = y[indeks_pociągu], y[indeks_testu]
… print(X_train, X_test, y_train, y_test)
POCIĄG: [1] TEST: [0]
[[3 4]] [1 2]] [2] [1]
POCIĄG: [0] TEST: [1]
[1 2]] [[3 4]] [1] [2]
5. Stratyfikacja
Zazwyczaj w przypadku podziału trenowanie/testowanie i składanie K, dane są tasowane w celu utworzenia losowego podziału trenowania i walidacji. W ten sposób pozwala na różne rozmieszczenie celów w różnych fałdach. Podobnie stratyfikacja ułatwia również rozkład celu w różnych fałdach podczas dzielenia danych.
W tym procesie dane są przegrupowywane w różnych fałdach w taki sposób, że każda fałda staje się reprezentatywna dla całości. Tak więc, jeśli masz do czynienia z problemem klasyfikacji binarnej, w której każda klasa składa się z 50% danych, możesz użyć stratyfikacji, aby uporządkować dane w taki sposób, aby każda klasa zawierała połowę instancji.
Proces stratyfikacji najlepiej nadaje się do małych i niezrównoważonych zbiorów danych z klasyfikacją wieloklasową.
Kod w Pythonie:
ze sklearn.model_selection import StratifiedKFold
skf = StratifiedKFold(n_splits=5, random_state=Brak)
# X to zestaw funkcji, a y to cel
dla train_index, test_index w skf.split(X,y):
print("Pociąg:", train_index, "Validation:", val_index)
X_train, X_test = X[train_index], X[val_index]
y_train, y_test = y[indeks_pociągu], y[val_index]
Przeczytaj: Ramki danych w Pythonie – samouczek
Kiedy stosować każdą z tych pięciu strategii weryfikacji krzyżowej?
Jak wspomnieliśmy wcześniej, każda technika walidacji krzyżowej ma unikalne przypadki użycia, a zatem działają najlepiej, gdy są stosowane poprawnie we właściwych scenariuszach. Na przykład, jeśli masz wystarczającą ilość danych, a wyniki i optymalne parametry (modelu) dla różnych podziałów prawdopodobnie będą podobne, podejście podziału pociąg/test będzie działać doskonale.
Jeśli jednak wyniki i optymalne parametry różnią się dla różnych podziałów, najlepsza będzie technika K-fold. W przypadkach, w których masz za mało danych, podejście LOOCV działa najlepiej, podczas gdy w przypadku małych i niezrównoważonych zestawów danych najlepszym rozwiązaniem jest stratyfikacja.
Mamy nadzieję, że ten szczegółowy artykuł pomógł ci uzyskać dogłębną wiedzę o walidacji krzyżowej w Pythonie.
Jeśli jesteś zainteresowany nauką o danych, sprawdź program IIIT-B i upGrad Executive PG w dziedzinie Data Science, który jest stworzony dla pracujących profesjonalistów i oferuje ponad 10 studiów przypadków i projektów, praktyczne warsztaty praktyczne, mentoring z ekspertami z branży, 1 -on-1 z mentorami branżowymi, ponad 400 godzin nauki i pomocy w pracy z najlepszymi firmami.
Co to jest „test permutacji” w ML?
Generując statystykę testową na zbiorze danych, a następnie dla wielu losowych permutacji tych danych, test permutacji służy do oceny istotności statystycznej modelu. Początkowa wartość statystyki testowej powinna mieścić się w jednym z ogonów rozkładu hipotezy zerowej, jeśli model jest istotny. Aby znaleźć wartość p, wystarczy policzyć liczbę statystyk testowych, które są tak samo surowe lub bardziej ekstremalne niż początkowe statystyki testowe, a następnie podzielić tę liczbę przez całkowitą liczbę statystyk testowych, które obliczyliśmy. Biorąc pod uwagę, że hipoteza zerowa jest prawdziwa, wartość P jest szansą na uzyskanie wyniku co najmniej tak poważnego, jak statystyka testowa.
Jakie są wady walidacji krzyżowej w uczeniu maszynowym?
1. Cross Validation znacznie wydłuża okres szkolenia. Wcześniej można było trenować model tylko na jednym zestawie uczącym; teraz możesz trenować go na kilku zestawach treningowych za pomocą walidacji krzyżowej.
2. W większości przypadków badana struktura rozwija się z czasem w modelowaniu predykcyjnym. W rezultacie możesz zauważyć różnice w zestawach uczących i walidacyjnych.
3. Cross Validation wymaga dużej mocy obliczeniowej.
Jak wykryć nadmierne dopasowanie w modelach ML?
Zanim ocenisz dane, wykrycie nadmiernego dopasowania jest prawie niemożliwe. Może to pomóc w trudnościach w uogólnianiu zbiorów danych, co jest nieodłączną cechą nadmiernego dopasowania. W rezultacie dane można podzielić na odrębne podzbiory, aby ułatwić szkolenie i testowanie. Proporcję dokładności zaobserwowaną w obu zestawach danych można wykorzystać do określenia, czy występuje nadmierne dopasowanie. Jeśli model działa lepiej w zestawie uczącym niż w zestawie testowym, istnieje prawdopodobieństwo, że jest przesadnie dopasowany.
Inną sugestią jest rozpoczęcie od bardzo podstawowego modelu ML, który będzie działał jako punkt odniesienia. Później, gdy będziesz testować złożone algorytmy, będziesz miał punkt odniesienia, według którego można ocenić, czy dodatkowa złożoność jest warta zachodu.
Miary walidacji, takie jak dokładność i straty, mogą być również wykorzystywane do wykrywania nadmiernego dopasowania. Kiedy na model ma wpływ nadmierne dopasowanie, miary walidacji generalnie rosną, aż ustabilizują się lub zaczną spadać.